本文主要是介绍使用 SAP ABAP 代码生成 PDF 文件,填充以业务数据并显示在 SAPGUI 里,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Smart Forms 是 SAP 传统的表单制作和打印的一种可视化工具。
本教程介绍可以看作 Smart Forms 的下一代 SAP 表单工具:Adobe Form. 同 Smart Form 相比,Adobe Form 在表单布局设计层面功能更加强大,能实现比 Smart Forms 更复杂,呈现效果更美观的表单视觉效果,因而广泛应用在 SAP 各个标准产品比如 SAP CRM,SAP Cloud for Customer 等本地部署和 SaaS 产品里。
本教程前一步骤,我们已经在事物码 SFP 里,开发好了一个 Adobe Form 模板,取名 ZPF_STUDY, 这里的前缀 PF,意思是 Print Form.
本文我们将介绍使用 ABAP 编程语言,将这个 Adobe Form 生成 PDF 文件,并且显示在 SAPGUI 里的具体步骤。
先看下效果。
执行报表,指定 First Name 和 Last Name 两个字段的值:
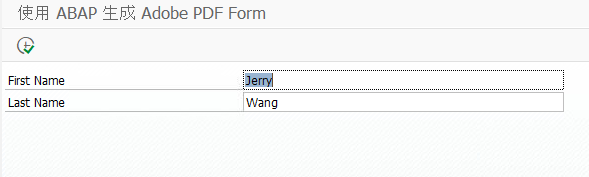
最后在 SAPGUI 里看到生成的 Adobe PDF,而我们在 ABAP 报表里的值,已经成功传递到 PDF 里了:
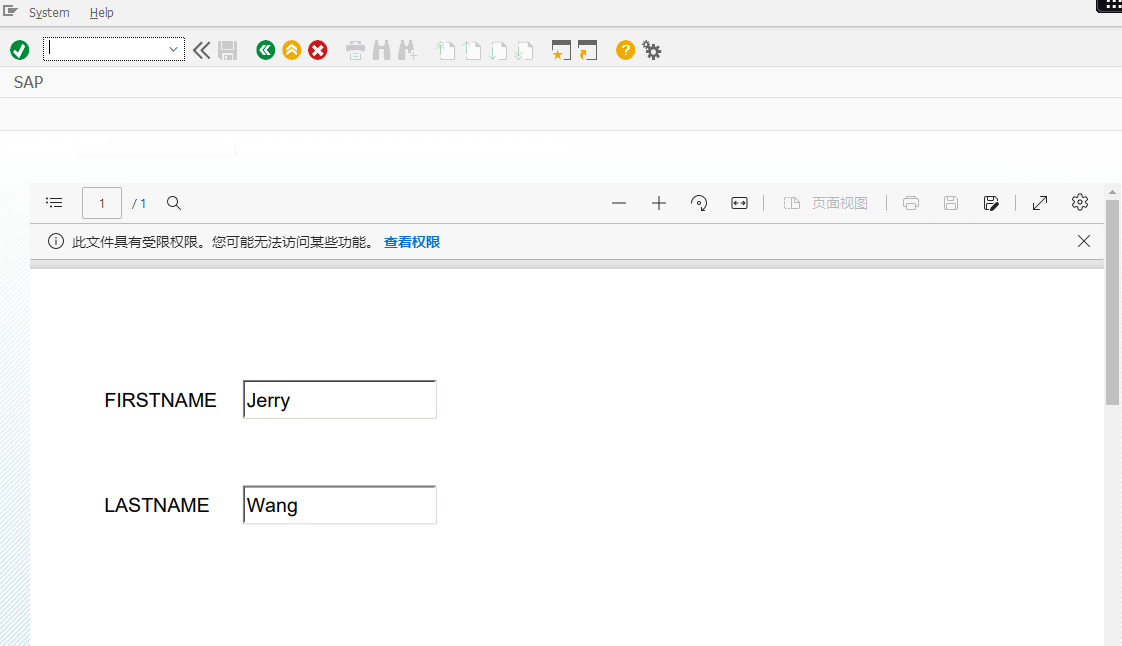
下面是这个例子的详细实现步骤。
我们直接在本教程这个步骤里开发好的 ABAP 报表上进行修改和调整。
这篇关于使用 SAP ABAP 代码生成 PDF 文件,填充以业务数据并显示在 SAPGUI 里的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






