本文主要是介绍论文阅读:基于 LSTM 的船舶航迹预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读:基于 LSTM 的船舶航迹预测
论文下载地址:https://download.csdn.net/download/qq_33302004/15611798
目录
1. 摘要
2. 预测模型结构和流程
3. 实验结果
4. 有趣的想法
1. 摘要

2. 预测模型结构和流程
(1)输入与输出
输出:(t+1 )时刻的经度和纬度(预测目标)
输入:t 时刻以及前(n-1)时刻的经度、纬度、航速、航向


(2)数据预处理
采用“分箱”的方式实现异常值剔除:

![]()
采用“三次样条插值”的方式,将非等时间间隔的数据插值成为等时间间隔的数据,实现时间对齐。

对输入数据进行归一化处理:

(3)预测模型结构

(4)模型相关参数
-
数据插值后时间间隔:10 s
-
输入层节点数量:4
-
隐含层节点数据量:100
-
输出层节点数量:2
-
学习率:0.001
-
批处理大小:20
-
优化函数:adam
-
预测时间步长:5
-
误差评价指标:RMSE 均方根误差
-
模型参数初始化方式:Xavier
-
经纬度预测最大误差不超过0.0005°
(5)训练过程

3. 实验结果
实验测试使用不同的 n 取值(预测使用的历史时间长度)对预测结果的影响,结果是步长为5效果最好:
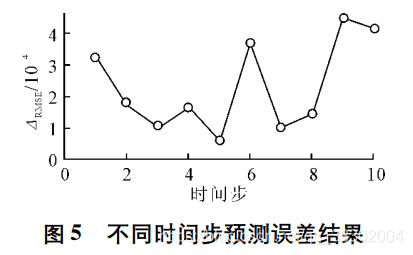
直线类型航迹的预测结果、经度误差、纬度误差:

转向类型航迹的预测结果、经度误差、纬度误差:

和灰度预测、BP算法预测的结果对比:

4. 有趣的想法
-
采用分箱的方式进行异常值剔除
-
对预测输入参数进行归一化处理、对输出数据进行反归一化处理
-
使用Xavier的方法对网络权重初始化(这个方法我之前没有了解过)
-
使用三次样条插值的方式,实现了对数据的时间对齐,将时间不均匀的数据构造成等事件间隔的数据
这篇关于论文阅读:基于 LSTM 的船舶航迹预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
