本文主要是介绍数据仓库架构之详解Kappa和Lambda,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、架构详解
1 Lambda 架构
1.1 Lambda 架构组成
1.2 Lambda 特点
1.3 Lambda 架构的优点
1.4 Lambda 架构的不足
2 Kappa 架构
2.1 Kappa 架构的核心组件
2.2 Kappa 架构优点
2.3 Kappa 架构的注意事项
三、区别对比
四、选择时考虑因素
一、前言
在大数据处理领域,有两种突出的数据架构已成为处理大量数据的流行选择:Lambda架构和Kappa架构。这两种架构为实时和批处理数据提供了强大的技术解决方案,使组织能够从数据资产中获取价值。
本文中我们将深入研究Lambda架构和Kappa架构,理解他们的主要特征、优点和区别。
二、架构详解
1 Lambda 架构
随着大数据应用的发展,人们逐渐对系统的实时性提出了要求,为了计算一些实时指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并。
Lambda 架构(Lambda Architecture)是由 Twitter 工程师南森·马茨(Nathan Marz)提出的大数据处理架构。这一架构的提出基于马茨在 BackType 和 Twitter 上的分布式数据处理系统的经验。
Lambda 架构融合了批处理与实时处理,使开发人员能够构建大规模分布式数据处理系统。它具有很好的灵活性和可扩展性,也对硬件故障和人为失误有很好的容错性。
1.1 Lambda 架构组成
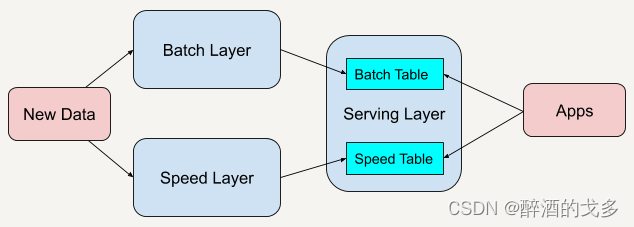
Lambda 架构总共由三层系统组成:
- 批处理层(Batch Layer)
- 加速层(Speed Layer)
- 服务层(Serving Layer)
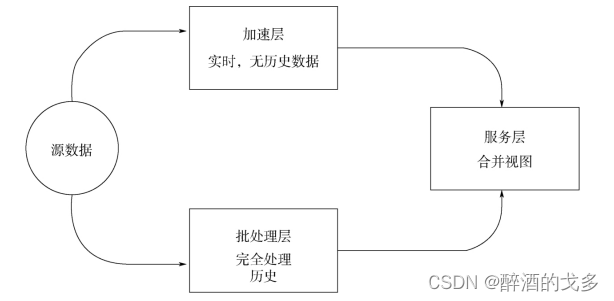
Lambda与DAMA的SBA架构有异曲同工之妙(下图为DAMA-SBA架构)
1.2 Lambda 特点
批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图:批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。
加速层会实时处理新来的大数据:加速层通过提供最新数据的实时视图来最小化延迟。加速层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在加速层的数据就可以被替代掉了。
本质上,加速层弥补了批处理层所导致的数据视图滞后。比如说,批处理层的每个任务都需要 1 个小时才能完成,而在这 1 个小时里,我们是无法获取批处理层中最新任务给出的数据视图的。而加速层因为能够实时处理数据给出结果,就弥补了这 1 个小时的滞后。
服务层用作查询和可视化数据的访问点。所有在批处理层和加速层处理完的结果都输出存储在服务层中,并提供一直的数据视图。服务层通过返回预先计算的数据视图或从加速层处理构建好数据视图来响应查询。
1.3 Lambda 架构的优点
Lambda架构提供了几个好处:
- 它通过跨多个层使用复制的数据来提供容错能力,从而确保数据可用性和弹性。
- 该体系结构还支持可扩展的处理,因为每一层都可以独立扩展以处理不断增加的工作负荷。
- 此外,批处理和实时处理的分离提高了资源利用率,因此批处理计算可以在更大的时间窗口上执行。
1.4 Lambda 架构的不足
虽然 Lambda 架构使用起来十分灵活,并且可以适用于很多的应用场景,但在实际应用的时候,Lambda 架构也存在着一些不足,主要表现在它的维护很复杂。
使用 Lambda 架构时,架构师需要维护两个复杂的分布式系统,并且保证他们逻辑上产生相同的结果输出到服务层中。
我们都知道,在分布式框架中进行编程其实是十分复杂的,尤其是我们还会针对不同的框架进行专门的优化。所以几乎每一个架构师都认同,Lambda 架构在实战中维护起来具有一定的复杂性。
那要怎么解决这个问题呢?我们先来思考一下,造成这个架构维护起来如此复杂的根本原因是什么呢?
维护 Lambda 架构的复杂性在于我们要同时维护两套系统架构:批处理层和加速层。我们已经说过了,在架构中加入批处理层是因为从批处理层得到的结果具有高准确性,而加入加速层是因为它在处理大规模数据时具有低延时性。
那我们能不能改进其中某一层的架构,让它具有另外一层架构的特性呢?
例如,改进批处理层的系统让它具有更低的延时性,又或者是改进加速层的系统,让它产生的数据视图更具准确性和更加接近历史数据呢?
另外一种在大规模数据处理中常用的架构——Kappa 架构(Kappa Architecture),便是在这样的思考下诞生的。
2 Kappa 架构
Kappa 架构通过专注于流处理,提供了 Lambda 架构的简化替代方案。它包含不可变数据流的概念,无需维护单独的批处理层。
Kappa 架构可以认为是 Lambda 架构的简化版(只要移除 lambda 架构中的批处理部分即可)。
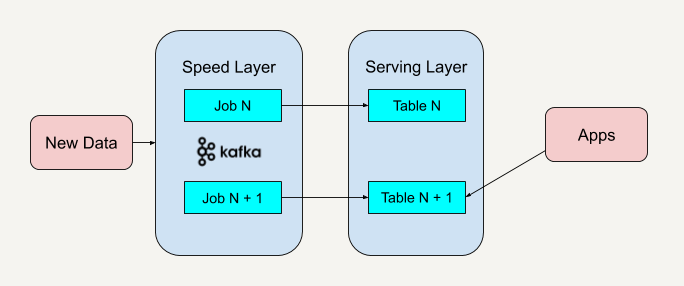
在 Kappa 架构中,所有数据都作为无限的事件流引入和处理。数据流经系统并进行实时处理,从而实现近乎即时的洞察力。
2.1 Kappa 架构的核心组件
流引入:从各种源连续引入数据并存储在事件日志中,例如 Apache Kafka。事件日志充当持久、容错的存储机制,可保留事件的完整历史记录。
流处理:流处理层使用事件日志中的数据,应用实时计算,并生成所需的输出。像Apache Kafka Streams或Apache Flink这样的技术可用于处理和分析。
输出服务:处理后的数据可通过各种输出通道访问,例如实时仪表板、API 或数据接收器,以供进一步分析或使用。
2.2 Kappa 架构优点
Kappa 架构通过专注于流处理,它简化了整体系统设计并降低了操作复杂性。该架构提供低延迟处理,因为数据近乎实时地处理,无需批量计算。它还在数据一致性方面提供了简单性,因为不需要同步和合并来自不同层的数据。
2.3 Kappa 架构的注意事项
在采用 Kappa 架构时需要牢记一些注意事项:由于所有数据都是实时处理的,因此如果没有额外的组件或流程,就没有对批处理或历史分析的固有支持。在处理某些需要分析大型历史数据集的用例时,此限制可能会带来挑战。此外,对连续流处理的依赖引入了对流处理框架的性能和可伸缩性的依赖。
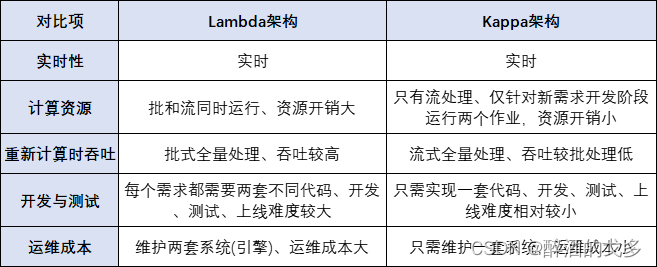
三、区别对比
四、选择时考虑因素
在 Lambda 和 Kappa 架构之间做出决定时,应考虑以下几个因素:
- 数据特征:考虑数据的性质和处理要求。如果应用案例需要实时和历史分析,则 Lambda 架构可能更适合。另一方面,如果主要关注实时处理和低延迟见解,那么 Kappa 架构可能更合适。
- 系统复杂性:评估与在 Lambda 架构中管理多个处理管道相关的复杂性与 Kappa 架构中单个流处理管道的简单性。考虑组织的资源、专业知识以及实施和维护所需的工作量级别。
- 可伸缩性和性能:评估系统的可伸缩性要求。这两种体系结构都可以水平扩展,但特定的技术选择和实现细节可能会影响性能。考虑希望处理的数据量、速度和种类,并选择能够满足可扩展性需求的体系结构。
- 数据一致性:检查应用程序的一致性要求。Lambda 架构提供了用于处理批处理层和加速层之间数据一致性的内置机制。在 Kappa 架构中,由于没有批处理层,因此简化了数据一致性,但在处理无序事件或延迟到达时可能需要额外的考虑因素。
- 操作注意事项:评估每个体系结构的操作方面,例如部署、监视和容错。考虑所选体系结构的工具、库和社区支持的可用性。
总之,Lambda 和 Kappa 架构都为处理大数据工作负载提供了强大的解决方案。Lambda 架构结合了批处理和实时处理的优势,提供了一段时间内数据的全面视图。另一方面,Kappa 架构通过专注于实时处理来简化系统设计,提供低延迟的洞察力。通过仔细考虑数据和应用程序的特定要求和特征,可以选择最适合业务与技术需求的体系结构,并使组织能够从大数据中获得数据资产的价值。
这篇关于数据仓库架构之详解Kappa和Lambda的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






