本文主要是介绍大数据项目:职务分析(一)——数据获取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目介绍:该项目适合学习的时候使用,因为项目比较小,主要目的对猎聘当中的各个岗位的数据的获取和简单的分析,从多个方面分析岗位之间的关系以及薪资的差异。
采用的技术有:
python爬虫:
hadoop:hdfs存储数据
hive on spark : 进行数据分析
sqoop: 将分析的结果传输到关系型数据库当中
superset:进行数据的可视化
首先是将数据从猎聘官网当中获取:

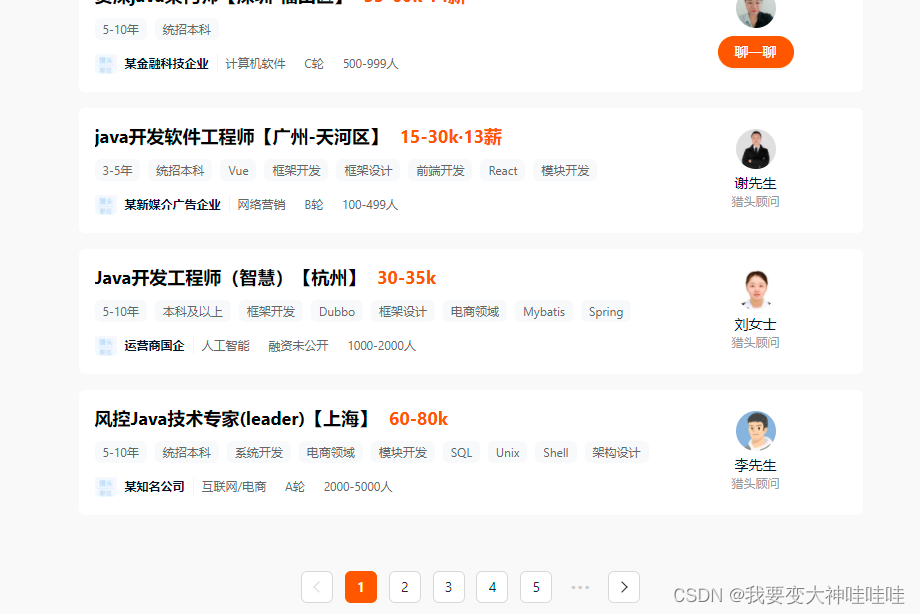
爬取技术一栏当中的似是一个岗位对应的数据。
先获得各个岗位的url,进行跳转,在每个网页当获取有用的信息:比如:岗位,地址,薪资,公司规模,要求掌握的技术,学历要求和经验要求,最后,对这一页的数据爬取完之后,进行跳转,通过find-element-by-xpath(),来锁定到下一页的链接上,跳转到下一页再进行数据的爬取,如此往复,从而,得到所有的想要的数据。
话不多说,代码实现为:
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import Options
from lxml import etree
import osdef share_brower():chrome_options = Options()# chrome_options.add_argument('--headless') # 来判断浏览器的前后台运行,有图形化可以更好的展现她的活动chrome_options.add_argument('--disable-gpu')path='C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'chrome_options.binary_location = pathbrower = webdriver.Chrome(chrome_options=chrome_options)return browerdef save(source, number, name1):tree = etree.HTML(source)position = tree.xpath('//ul/li//div[@class="job-title-box"]/div[1]/text()')addr = tree.xpath('//ul/li//div[@class="job-title-box"]/div[2]/span[2]/text()')salary = tree.xpath('//ul/li//div[@class="job-detail-header-box"]/span/text()')company = tree.xpath('//ul/li//div[@class="job-company-info-box"]/span/text()')scale = tree.xpath('//ul/li//div[@class="job-company-info-box"]/div[@class="company-tags-box ellipsis-1"]/span[last()]/text()')experience = tree.xpath('//ul/li//div[@class="job-labels-box"]/span[1]/text()')xueli = tree.xpath('//ul/li//div[@class="job-labels-box"]/span[2]/text()')keyword = tree.xpath('//ul/li//div[@class="job-labels-box"]/span/text()')mi = min(len(position), len(addr), len(salary), len(company), len(scale), len(xueli), len(experience))with open('./date/' + name1.strip() + "/" + str(number) + '.csv', 'w', encoding='utf-8') as fs:for l in range(mi):new = position[l] + ',' + addr[l] + ',' + salary[l] + ',' + company[l] + ',' + scale[l]+','+experience[l]+','+xueli[l]+'\t\n'fs.write(new)fs.close()with open('./keyword.txt', 'a', encoding='utf-8') as fs:ne = ''for i in keyword:ne = ne + i + ' 'fs.write(ne)fs.close()base_url = 'https://www.liepin.com'
brower = share_brower()
brower.get('https://www.liepin.com/it/')
brower.implicitly_wait(3)
page = brower.page_source
tree = etree.HTML(page)
name = tree.xpath('//ul[@class="sidebar float-left"]/li[1]//dd/a/text()')
url = tree.xpath('//ul[@class="sidebar float-left"]/li[1]//dd/a/@href')
for i in range(len(name)):if not os.path.exists('./date/'+name[i]):os.mkdir('./date/'+name[i]) #创建文件夹brower.get(base_url+url[i])brower.implicitly_wait(3)source = brower.page_sourcenumber = 1save(source, number, name[i])print(name[i])try:for j in range(9):element = brower.find_element_by_xpath('//div[@class="list-pagination-box"]//li[last()]/a')element.click()save(brower.page_source, number, name[i])number += 1except RuntimeError:print("*"*30+"有错误,但是可以执行的哦!!")continueelse:print("文件已经存在")os.rmdir('./date/'+name[i])continue
## //ul[@class="sidebar float-left"]/li[1]//dd/a/text() 相关职业
# //ul[@class="sidebar float-left"]/li[1]//dd/a/@href 对应的连接 每个连接底下都有十个页面 、爬取当中的数据
# 数据的存放 总共有49个类别的技术岗位 分别放在49个问价夹底下,文件夹以对应的职业命名 底下十个文件,每个文件表示每一页的数据
# ,文件的命名方式以1-10.csv ,保存的时候中间以逗号隔开,保存当当前的路径底下,然后爬取成功之后同意上传到大数据集
# 群的本地文件夹下面# //ul/li//div[@class="job-title-box"]/div[1]/text() 职位
# //ul/li//div[@class="job-title-box"]/div[2]/span[2]/text() 地址
# //ul/li//div[@class="job-detail-header-box"]/span/text() 薪资
# //ul/li//div[@class="job-company-info-box"]/span/text() 企业
# //ul/li//div[@class="job-company-info-box"]/div[@class="company-tags-box ellipsis-1"]
# /span[last()]/text() 公司规模
# //ul/li//div[@class="job-labels-box"]/span[1]/text() 工作经验
# //ul/li//div[@class="job-labels-box"]/span[2]/text() 招聘学历要求
# //ul/li//div[@class="job-labels-box"]/span/text() //用正则将数据的后序删除掉,或者在hadoop当中处理
# //div[@class="list-pagination-box"]//li[last()] 下一页的标签 循环九次brower.quit()
# 最后退出最后结果为:
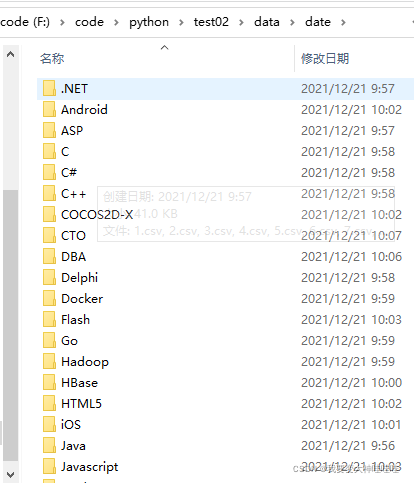
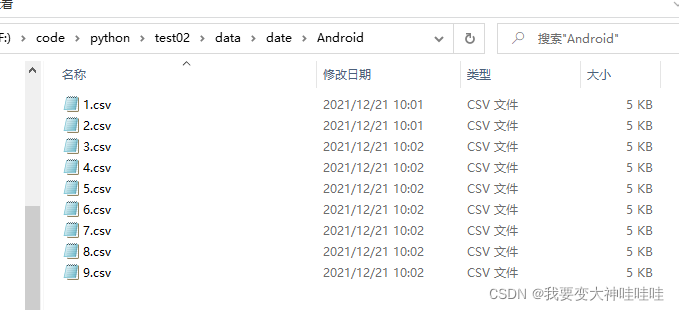

每一层和里面的数据保存形式,都如上所述,后序通过简单的mapreduce实现数据的处理,上传至hdfs当中,下期继续。。。。
这篇关于大数据项目:职务分析(一)——数据获取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





