本文主要是介绍【miniQMT实盘量化4】获取实时行情数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
上篇,我们介绍了如何获取历史数据,有了历史数据,我们可以进行分析和回测。但,下一步,我们更需要的是实时数据,只有能有效的监控实时行情数据,才能让我们变成市场上的“千里眼,顺风耳”。
接口汇总
与获取实时数据相关的接口,有以下几个
xtdata.get_full_tick()
xtdata.subscribe_whole_quote()
xtdata.subscribe_quote()
xtdata.unsubscribe_quote()
后文逐一展开说明。
实时行情 vs 历史行情
我们先探讨一下什么是实时行情,其实,实时,无非就是很近的历史,我们希望这个时间越近越好。获取到的最新行情的时间越接近他产生的时间,那就更多的获得了优先决策权。虽然几秒或者几百毫秒,对于人类而言微乎其微,但对于计算机来讲,可以做很多事。
订阅 vs 获取
熟悉编程设计模式的朋友,对“订阅”这个概念,不会陌生,但也有可能一部分非专业的朋友不太了解,我这里通俗易懂解释一下。
普通获取数据的接口,调用成功一次,会返回一次数据结果。那想想我们获取实时数据的场景,我们需要持续、不停的获取某一数据的最新值,那我就要持续轮询调用这个接口才能完成,对吧,比如,一秒调用一次。但这里存在一个问题,你也不知道最新数据是何时来的,假如若是最新数据0.5秒之后就已经更新了呢,那我们就浪费了0.5秒的机会,对吧。
而对于订阅模式的接口来讲,一旦这个接口被订阅成功,在之后的时间里,它会主动的给你推送数据最新数据,一般这种接口都会有一个callback函数作为参数,每次最新数据来的时候,该callback函数就会被调用一次(后面我们会结合具体例子演示)。这样,我们就降低了获取数据的延时性,数据会第一时间返回到我们的程序中。
那对应于本文要阐述的接口,get_full_tick就是普通获取接口,而subscribe_quote和subscribe_whole_quote就是订阅接口。另外,对于订阅接口,往往需要一个取消订阅的接口来解除订阅,不然数据将会一直推送,unsubscribe_quote的作用就是这个。
get_full_tick
这是全推数据的主动获取接口,所谓全推数据,就是当前时间最新的市场横截面数据。
这里没什么复杂的,只有一个参数,就是传入代码的数组,返回值是一个以股票代码为key的字典,对应的值就是该股票最新的tick数据。如果是非交易时间,这里返回了上一个交易日最后一个tick数据。
注意,此接口是不能传period参数,返回的数据默认是最新的tick周期数据。
from xtquant import xtdatares = xtdata.get_full_tick(['600519.SH'])res['600519.SH']

subscribe_whole_quote(推荐)
这是订阅全推数据的接口,与get_full_tick功能类似,只是模式不同,此接口采用订阅模式。
from xtquant import xtdatadef on_data (datas):print(datas)seq = xtdata.subscribe_whole_quote(code_list=['600519.SH'], callback=on_data)xtdata.run()
这里的xtdata.run()并不一定是必须的,这行代码只是为了阻塞该段代码一直处于运行状态,由于我们是订阅模式的接口,只要不取消订阅,就会一直返回数据。所以让程序处于一直运行状态比较好。
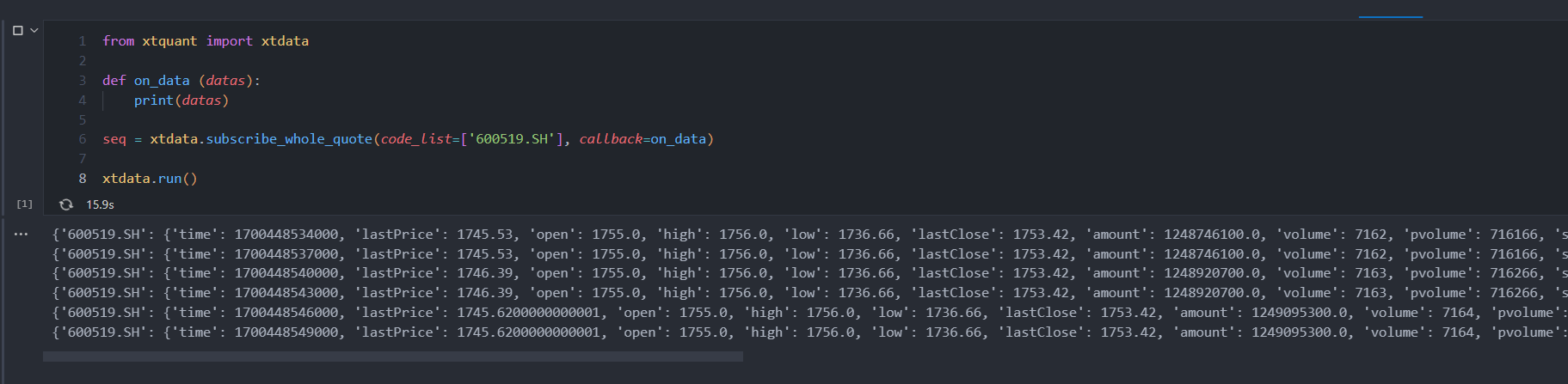
可以看到,on_data方法会被一直调用,每次都返回最新的tick。此接口只有两个参数code_list和callback,callback传入一个方法,具体的返回数据在这个方法中处理,落实到我们的例子中,就是on_data方法。
下面,我们再测试一下订阅的返回时间和速度,为代码解析返回数据的时间戳,并与当前系统时间做对比
from xtquant import xtdata
from datetime import datetime
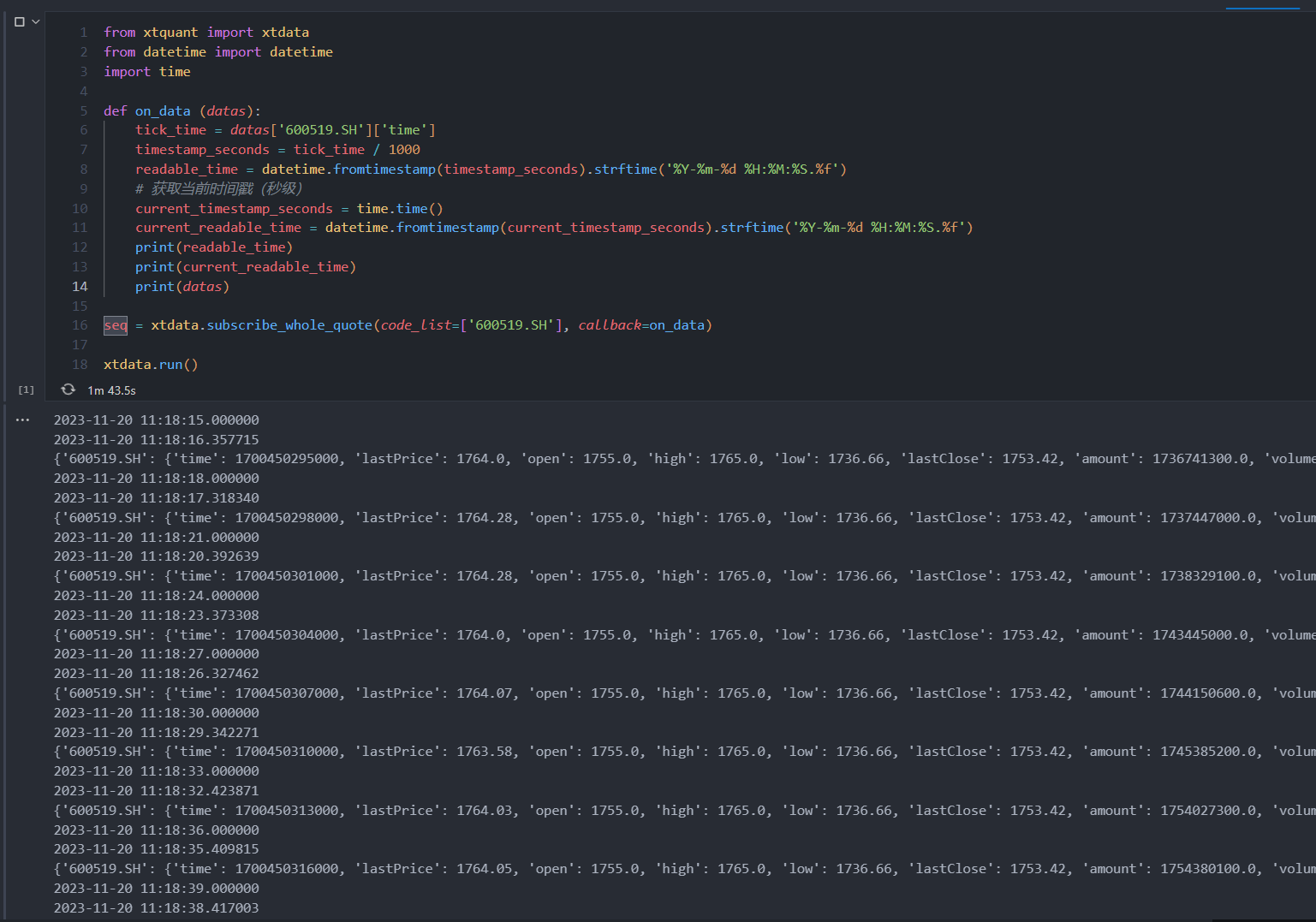
import timedef on_data (datas):tick_time = datas['600519.SH']['time']timestamp_seconds = tick_time / 1000readable_time = datetime.fromtimestamp(timestamp_seconds).strftime('%Y-%m-%d %H:%M:%S.%f')# 获取当前时间戳(秒级)current_timestamp_seconds = time.time()current_readable_time = datetime.fromtimestamp(current_timestamp_seconds).strftime('%Y-%m-%d %H:%M:%S.%f')print(readable_time)print(current_readable_time)print(datas)seq = xtdata.subscribe_whole_quote(code_list=['600519.SH'], callback=on_data)xtdata.run()
根据下面的结果,我们可以得知:
1、该数据每三秒返回一次,也就是每三秒产生一个tick,这就是目前实时数据的最小时间单位。
2、返回的时间戳时间解析后,是大于系统时间的,大致是大个0.5~0.6秒之间,我认为这个时间戳应该是做了提前处理,以保证获取到数据的时间与系统时间接近。
subscribe_quote
这是,单股订阅接口。最大的特点是,每次订阅只能传入一只股票代码,且该接口具有period参数,可以不止获取tick级别的数据。
from xtquant import xtdata
from datetime import datetime
import timedef on_data (datas):tick_time = datas['600519.SH'][0]['time']timestamp_seconds = tick_time / 1000readable_time = datetime.fromtimestamp(timestamp_seconds).strftime('%Y-%m-%d %H:%M:%S.%f')# 获取当前时间戳(秒级)current_timestamp_seconds = time.time()current_readable_time = datetime.fromtimestamp(current_timestamp_seconds).strftime('%Y-%m-%d %H:%M:%S.%f')print(readable_time)print(current_readable_time)print(datas)seq = xtdata.subscribe_quote(stock_code='600519.SH', period='tick', callback=on_data)xtdata.run()
可以看到,返回结果与subscribe_whole_quote区别不大,只是值多了一层数组。
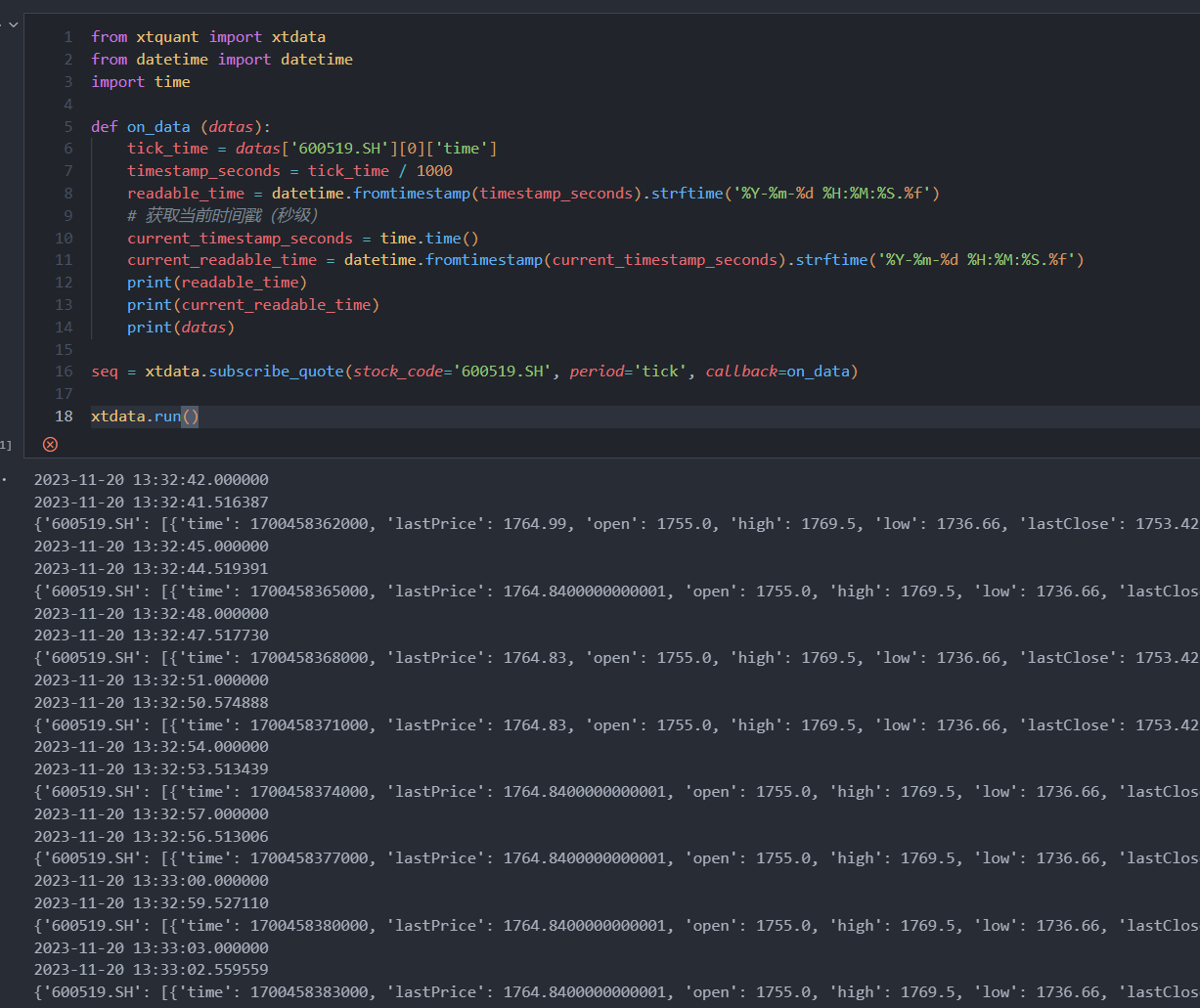
这个接口可以将peroid设为1m,1h,1d等,但其订阅频率依旧是三秒一次,比如,当订阅1m也就是分钟线时,会每三秒返回当前分钟线的最新值,也就是分钟线的收盘价会不停变化。
另外,根据迅投官方的声明,这个单股订阅的接口不宜订阅过多,性能上也不如全推订阅。

所以,个人建议订阅实时数据时,最好还是使用全推订阅接口。如果想监听分钟线、小时线、或日线这种频率较低的数据,完全可以用轮询获取最新历史数据的方法,来代替。
unsubscribe_quote
这是取消订阅的接口,其实也是相当重要,订阅模式的接口,不同于普通接口,一旦订阅成功,就会有一个进程一直在监听并返回数据,当不在需要订阅时,需要显示的调用取消订阅接口,才能停止此次订阅。若大量调用订阅且不及时取消时,可能会造成大量的CPU和内存占用。
from xtquant import xtdata
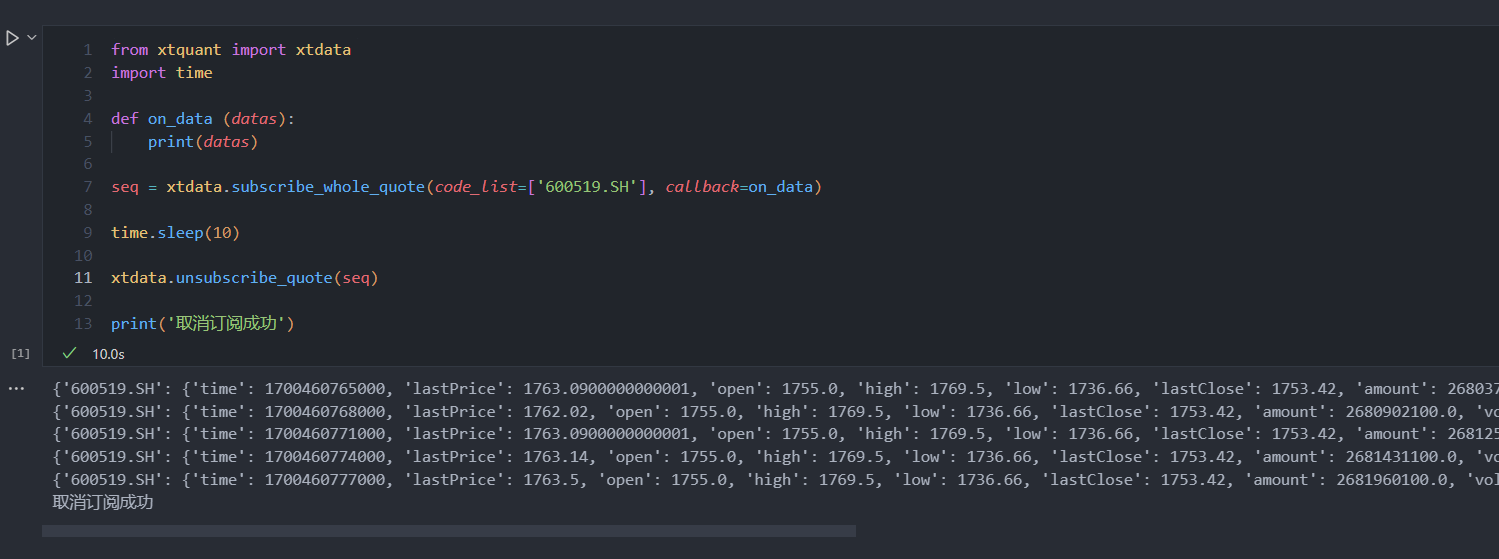
import timedef on_data (datas):print(datas)seq = xtdata.subscribe_whole_quote(code_list=['600519.SH'], callback=on_data)time.sleep(10)xtdata.unsubscribe_quote(seq)print('取消订阅成功')
在本例中,我们首先调用全推订阅接口,该接口会返回一个订阅号seq,然后我们阻塞程序10秒钟,10秒钟后取消订阅。可以看到下图,程序运行10秒后终止,且订阅也被取消。
在实际使用中,可以根据自己的需要,在适合的时机调用unsubscribe_quote,比如程序终止前,或者有GUI的应用,也可以设计一个按钮负责取消订阅。
交易时间段内使用
需要注意的是,本文提到的两个订阅接口,在非交易时间都是无法触发callback的,也就是说,在使用或者测试这两个接口时,要选在开盘时间内,盘后在测试实时数据接口,是比较困难的。
总结
关于如何获取实时数据的内容,就讨论到这里。实时数据,是做量化实盘交易的数据基础,一个稳定,好用的实时数据源,可以更好的帮我们实现实盘量化策略。
miniQMT在这个功能上提供了实时订阅的模式,功能相对来说比较完善。
miniQMT具体开通方法及要求,可以参看《QMT开通规则分享》
这篇关于【miniQMT实盘量化4】获取实时行情数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





