本文主要是介绍下厨房网站月度最佳栏目菜谱数据获取及分析PLus,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概要
源数据获取
写Python代码爬取数据
Scala介绍与数据处理
1.Sacla介绍
2.Scala数据处理流程
数据可视化
最终大屏效果
小结
概要
本文的主题是获取下厨房网站月度最佳栏目近十年数据,最终进行数据清洗、处理后生成所需的数据库表,最终进行数据可视化。用到的技术栈有Python网络爬虫、数据分析、Scala引擎、Flask框架等,其中会重点讲解使用Scala数据处理的过程,其他步骤则是一笔带过。
源数据获取
- 首先是源数据地址,网站来源于下厨房 (xiachufang.com),查看网站情况如下:
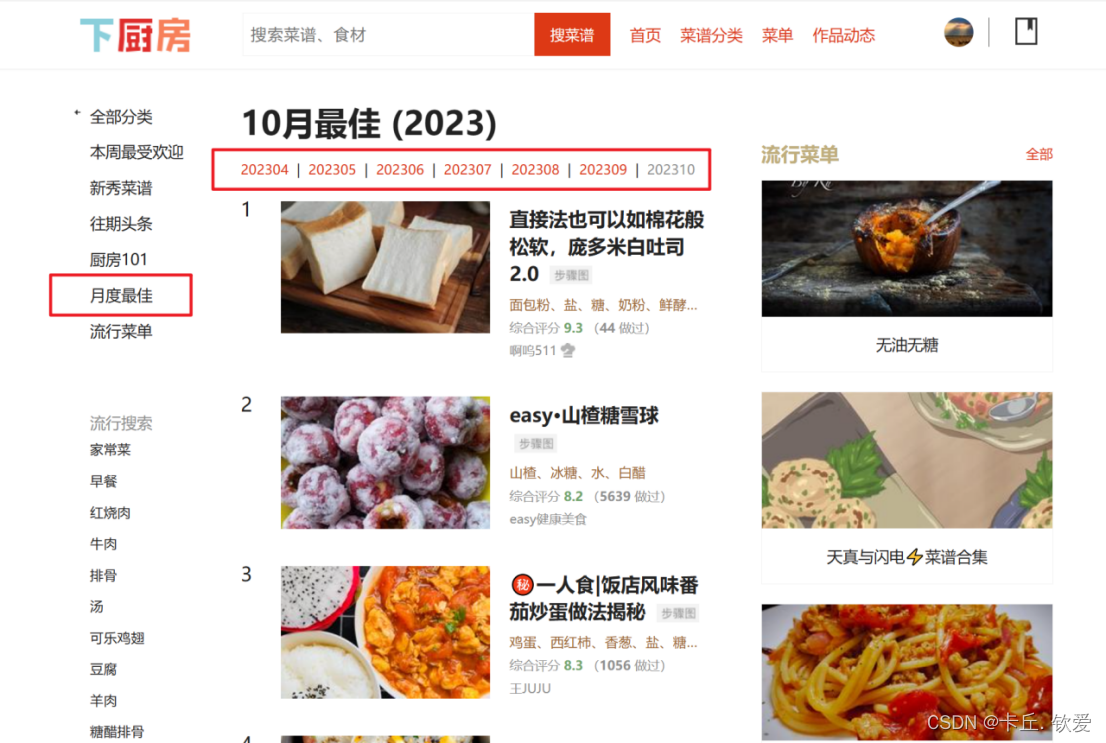
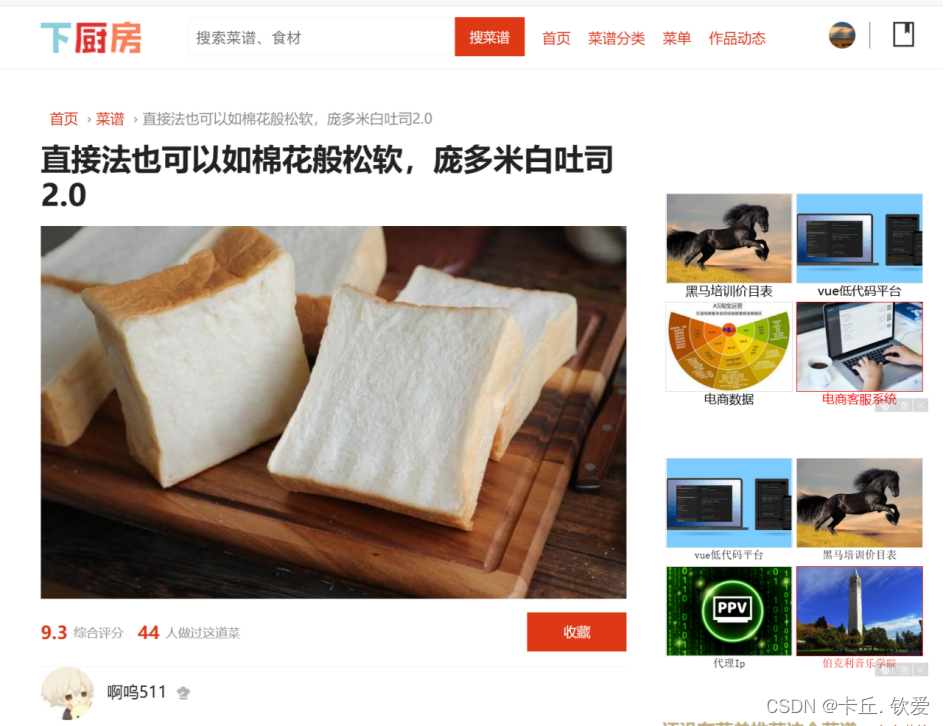

可以看见,本次的数据源是下厨房网站里面的月度最佳栏目,该栏目有2011年3月到至今2023年10月的连续数据,其中每个月有50道当月最受欢迎菜品,每个菜谱点进去后,不仅有菜名、详细用料等,还贴出具体步骤。
-
写Python代码爬取数据
如图,利用所学知识,编写爬虫代码对网站进行解析并爬取数据,最后经过简单处理后存储至MySQL数据库并另存为csv表格留档,本次只获取了2015年5月至2023年10月近10年的数据

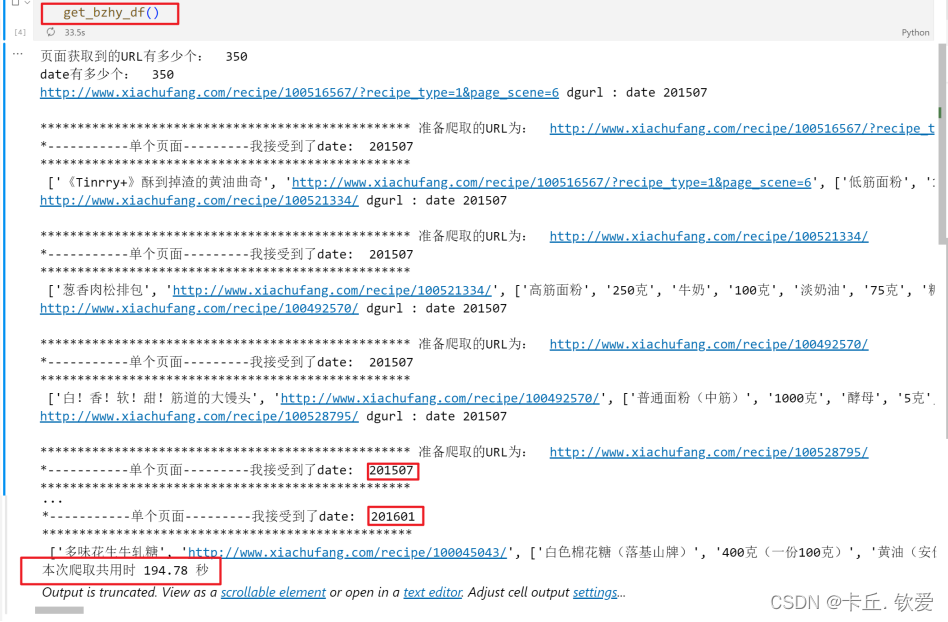
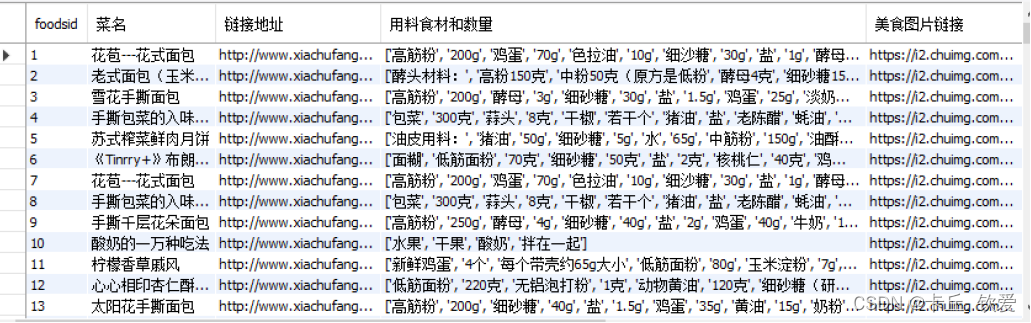

可以看见获取的数据总共有十个字段,有菜名、链接、做法等信息,其中foods_id、收藏人数、最佳年月字段是整型,其余字段都是文本类型
Scala介绍与数据处理
1.Sacla介绍
Scala是一种通用的编程语言,它结合了面向对象编程和函数式编程的特点,并且在大数据处理领域被广泛使用。
Scala最初于2003年由Martin Odersky教授开发,并于2004年首次发布。Scala在Java虚拟机(JVM)上运行,可以与Java互操作,并且可以直接使用Java的库和工具。
Scala的主要特点包括:
静态类型系统:Scala是一种静态类型的语言,这意味着在编译时会进行类型检查,减少运行时错误。
面向对象和函数式编程:Scala支持面向对象编程,可以使用类、继承和多态等概念。同时,Scala也支持函数式编程,提供了高阶函数、匿名函数和不可变数据结构等特性。
表达力强大:Scala具有强大而灵活的语法,可以用更少的代码实现复杂的任务。它提供了模式匹配、高级类型推断和代数数据类型等功能,使编程变得更加简洁和易读。
并发编程支持:Scala内置了并发编程库,提供了可以简化并发编程的抽象和工具。其中,最著名的是Akka框架,它提供了基于消息传递的并发模型。
在大数据处理领域,Scala通常与Apache Spark搭配使用。Spark是一个快速、通用的大数据处理引擎,Scala是其主要支持的编程语言之一。借助Scala的强大特性和Spark的分布式计算能力,开发人员可以编写高效、可扩展的大数据处理应用程序。
总而言之,Scala是一种强大的编程语言,特别适用于大数据处理和并发编程。它结合了面向对象和函数式编程的优点,并且在大数据处理领域有着广泛的应用和影响。
2.Scala数据处理流程
现在数据库已经有了源数据,接下来就是进行数据处理了。这里我选择的技术是Scala引擎,不熟悉的小伙伴可以上网查看该技术的语法格式和注意事项,我就不进行过多描述,直接进行代码解读。首先,要明确处理的目标和步骤,通过查看数据,我设立了5个指标,附上指标说明和代码:
- 代码前文:mysql_da是数据库源数据,de_Data是根据菜名去重后的数据
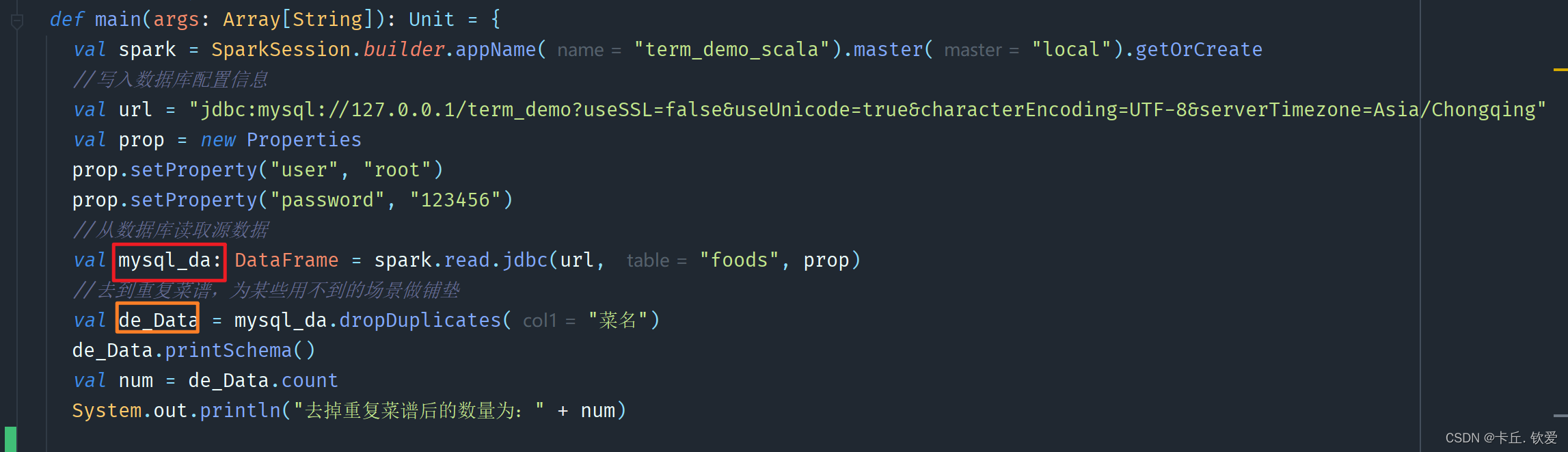
- 1 作者菜谱及收藏总量
这里对去重后的数据,根据作者id进行分组,然后聚合行数即为菜品数量、聚合收藏人数即为中收藏数量,最后调用write方法将处理后的数据存储到新的数据表和Hadoop集群的hdfs组件
//1 查询数据源里面属于一个作者的菜品和总收藏量有多少,保存前100个作者,存储下来val num_foods = de_Data.groupBy("作者id").agg(functions.count("*").alias("菜品数量"),functions.sum("收藏人数").alias("总收藏数量")).sort(functions.desc("菜品数量")).limit(100)//打印看看结果是否出来num_foods.show();System.out.println("*************菜谱数量top100*********")//存储至本地数据库num_foods.write.mode(SaveMode.Overwrite).jdbc(url, "foods_num", prop)//存储到hdfsnum_foods.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_num")
- 2 历年收藏Top10
- 首先,对最佳年月字段进行处理,将其转换为年份,并创建临时视图"foods_with_year"。
- 接着,使用SQL语句查询不同年份中收藏人数最多的前10道菜,并生成临时视图"year_tab1"。
- 最后,从临时视图"year_tab1"中选取字段,并按年份升序、收藏人数降序排序,并展示前100行结果。
- 将结果数据保存至本地数据库和HDFS中。
//2 查询数据里面不同年份最多收藏人数的前10菜品// 将最佳年月字段转换为年份System.out.println("做到第二题了")val de_year = de_Data.withColumnRenamed("收藏人数", "sl")de_year.createOrReplaceTempView("foods")spark.sql("SELECT *, CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) as year FROM foods").createOrReplaceTempView("foods_with_year")// 查询不同年份中收藏人数最多的前10道菜val year = spark.sql("SELECT * FROM (SELECT *, row_number() " +"OVER (PARTITION BY year ORDER BY sl desc ) AS rank_no FROM foods_with_year ) tmp WHERE rank_no <= 10 ")//分两步进行sql查询,第一步是开窗函数进行分组统计,第二步是根据年份和收藏人数排序year.createOrReplaceTempView("year_tab1")val foods_year = spark.sql("select `year`, `菜名`,`用料食材和数量`, `链接地址`, `作者id`, `sl`,`rank_no` " +"from year_tab1 order by `year` asc, `sl` desc")foods_year.show(100, false)//存储至本地数据库foods_year.write.mode(SaveMode.Overwrite).jdbc(url, "foods_year", prop)//存储到hdfsfoods_year.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_year")
- 3 历年收藏Top10
首先,根据创建时间添加了一个名为“季节”的字段,根据不同的月份范围为每个菜品添加上了对应的季节信息,然后修改了字段名为“season”以方便后续处理。
使用窗口函数,在每个季节内按收藏人数进行降序排名,并取出每个季节收藏数量排名前5的菜品,将结果存储在名为“data_jj1”的DataFrame中。
将结果数据分别保存至本地数据库和HDFS中。在保存至本地数据库时,使用了覆盖的保存模式。
//3 根据创建时间再添加一个字段:季节,比如3-5月是春季,6-8是夏季~//根据季节来进行分组计数,计算出每个季节收藏数量排名前5的菜品// 添加季节字段var data_jj = de_Data.withColumn("季节", functions.when(month(col("创建时间")).between(3, 5), "春季").when(month(col("创建时间")).between(6, 8), "夏季").when(month(col("创建时间")).between(9, 11), "秋季").otherwise("冬季"))// 把季节改成英文方便开窗函数运行data_jj = data_jj.withColumnRenamed("季节", "season")data_jj = data_jj.withColumnRenamed("收藏人数", "sl")data_jj.createTempView("data_jj")val windowSpec = Window.partitionBy("season").orderBy(functions.desc("sl"))val data_jj1 = data_jj.withColumn("rank_no", row_number.over(windowSpec)).orderBy(expr("CASE season " +"WHEN '春季' THEN 1 " +"WHEN '夏季' THEN 2 " +"WHEN '秋季' THEN 3 " +"WHEN '冬季' THEN 4 " +"ELSE 5 " + "END"), col("rank_no")).filter(col("rank_no").leq(5))System.out.println("*************每个季节收藏数量排名前5的菜品*********")// 将数据存储到本地数据库和hdfs集群//保存模式为覆盖data_jj1.write.mode(SaveMode.Overwrite).jdbc(url, "foods_season", prop)//存储到hdfsdata_jj.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_season")
- 4 历年收藏Top10
- 将数据加载到临时视图"ws_data"中,以便后续查询操作。
- 使用SQL语句进行查询,按照年份对每个作者的收藏数量进行汇总,并按收藏数量降序排名。取每年收藏数量前3的作者和总收藏量数据,将结果保存在名为"foods_with_year"的临时视图中。
- 从"foods_with_year"视图中查询结果并展示。
- 将结果数据保存至本地数据库,并使用覆盖的保存模式。
- 将结果数据保存至HDFS中,数据格式为parquet,并使用覆盖的保存模式。
//4每年收藏数量前3的作者和总收藏量mysql_da.createTempView("ws_data")spark.sql("SELECT `最佳年月`, `作者id`, `年收藏量`\n" +"FROM (\n" + " SELECT `最佳年月`, `作者id`, SUM(`收藏人数`) AS `年收藏量`,\n" +"ROW_NUMBER() OVER(PARTITION BY FLOOR(`最佳年月` / 100) ORDER BY Max(`收藏人数`) DESC) AS `排名`\n" + " " +"FROM ws_data\n" + " GROUP BY `最佳年月`, `作者id`\n" + ") AS subquery\n" + "WHERE `排名` <= 3\n" + "ORDER BY `最佳年月`,`排名`").createOrReplaceTempView("foods_with_year")val fsj = spark.sql("SELECT CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) as `年份` ,`作者id`, `年收藏量` FROM foods_with_year")fsj.show()//存储至本地数据库fsj.write.mode(SaveMode.Overwrite).jdbc(url, "foods_nszl", prop)//存储到hdfsfsj.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_nscl")
- 5 历年收藏Top10
- 将数据加载到临时视图"ws_data1"中,为后续查询做准备。
- 使用SQL语句查询每个最佳年月的作者的年收藏量,并按照排名进行排序,将结果保存在名为"foods_zly"的临时视图中。
- 从"foods_zly"视图中提取年份、作者ID和年收藏量的数据。
- 计算每年的总收藏人数增长趋势,包括计算增长率,并展示结果。
- 将结果数据保存至本地数据库中,并使用覆盖的保存模式。
- 将结果数据保存至HDFS中,数据格式为parquet,并使用覆盖的保存模式。
//5.每年的收藏率趋势mysql_da.createTempView("ws_data1")// 查询每个最佳年月的作者的年收藏量,并按照排名进行排序spark.sql("SELECT `最佳年月`, `作者id`, SUM(`收藏人数`) AS `年收藏量`,\n" + "" +"ROW_NUMBER() OVER(PARTITION BY FLOOR(`最佳年月` / 100) ORDER BY MAX(`收藏人数`) DESC) AS `排名`\n" +"FROM ws_data1\n" + "GROUP BY `最佳年月`, `作者id`\n" + "ORDER BY `最佳年月`,`排名`").createOrReplaceTempView("foods_zly")// 提取年份、作者ID和年收藏量val zzl = spark.sql("SELECT CAST(SUBSTRING(`最佳年月`, 1, 4) AS int) AS `年份`, `作者id`, `年收藏量` FROM foods_zly")// 计算每年的总收藏人数增长趋势var trend = zzl.groupBy("`年份`").agg(sum("`年收藏量`").as("总收藏人数")).orderBy("`年份`")// 计算增长率val windowSpec1 = Window.orderBy("年份")trend = trend.withColumn("前一年收藏人数", lag("`总收藏人数`", 1).over(windowSpec1)).withColumn("增长率",round(expr("(cast(`总收藏人数` as double) / cast(`前一年收藏人数` as double)) - 1"), 2)).drop("前一年收藏人数")trend.show()trend.write.mode(SaveMode.Overwrite).jdbc(url, "foods_zzl", prop)//存储到hdfstrend.write.format("parquet").option("header", "true").option("encoding", "UTF-8").mode("overwrite").save("hdfs://20210322045-master:9000/term_data/foods_zzl")查看处理后的数据
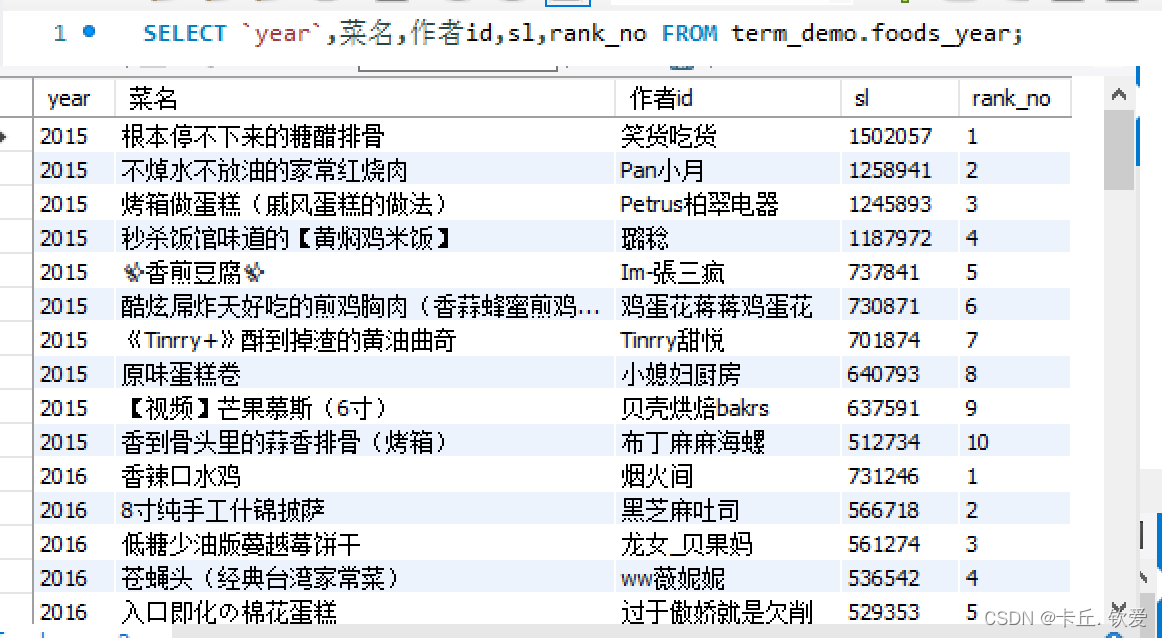
foods_year

foods_season
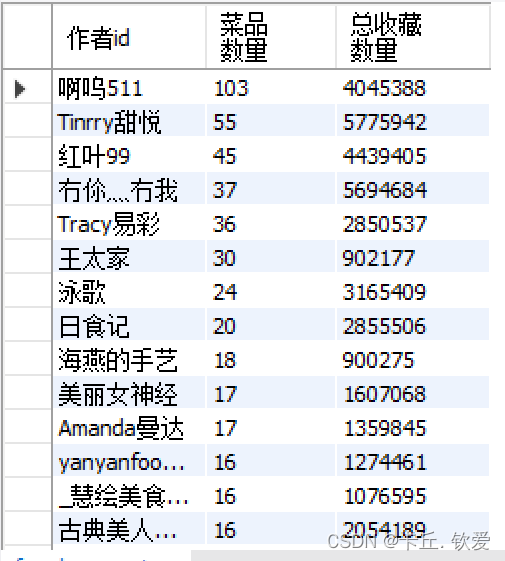
foods_num
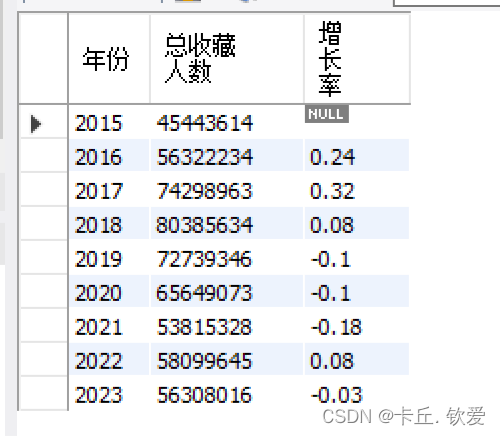
foods_zzl
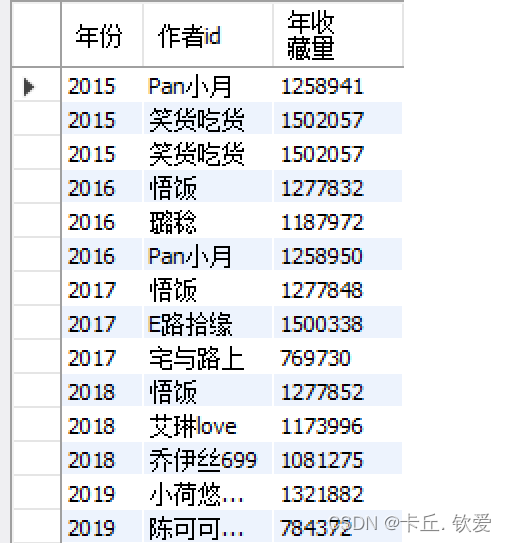
foods_nszl
数据可视化
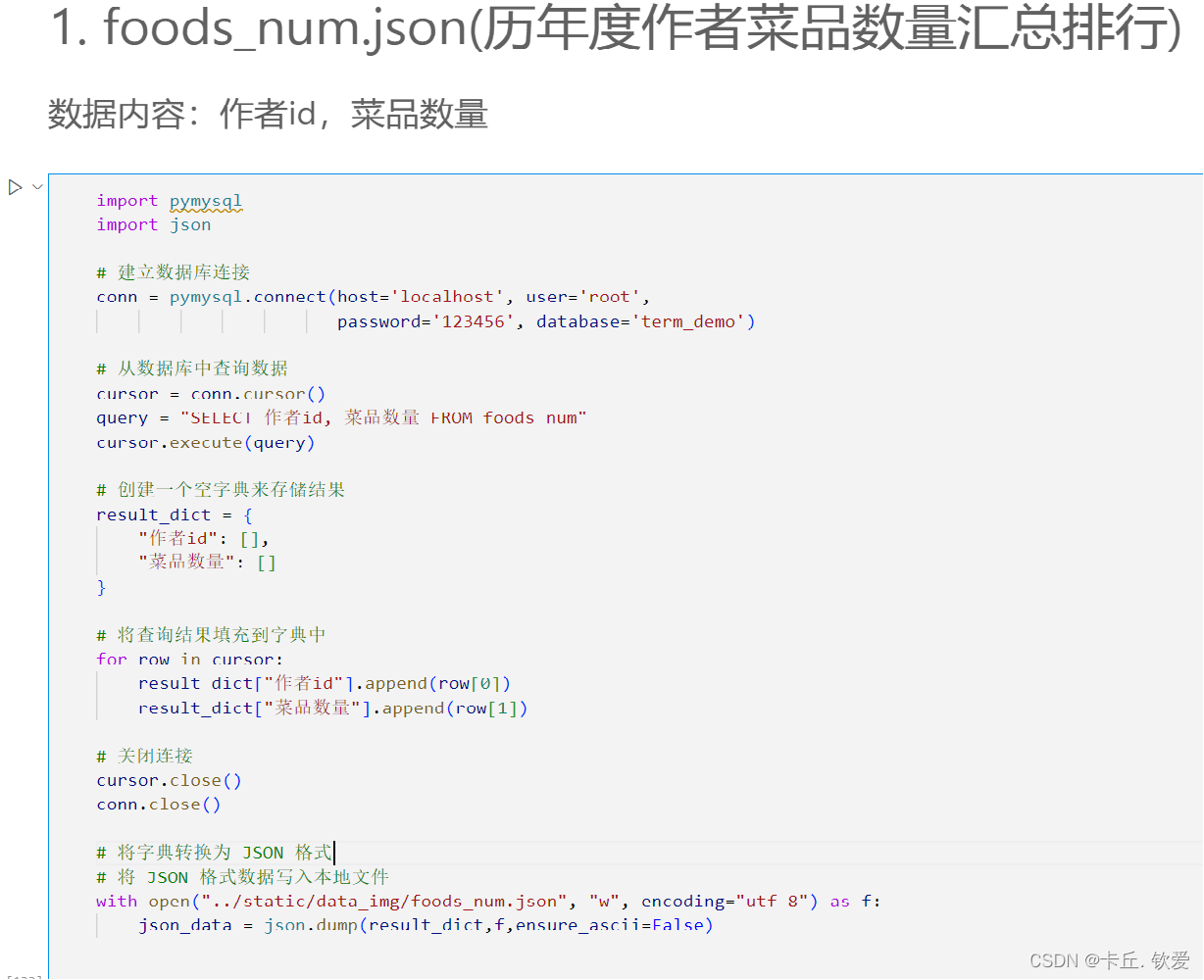
最后是数据可视化展示,用python将Spark处理存储到数据库的数据读取,并且将其加工成所需类型后转成json格式,供后面大屏读取用,下面是部分处理代码:

随后新建html文件,在里面添加各项依赖后,在<script>标签里面添加一下Echarts的配置项,并用Ajax技术读取刚才处理好的json文件传入给配置项后,即可在通过Flask框架在网页上渲染出数据大屏

最终大屏效果

小结
项目到这里就算是完成了,做的时候其实涉及到的技术栈还是蛮多的,虽然都不是很深,但是途中也遇到了各种各样的困难。特别是用Scala技术进行数据处理时,由于对语法的不熟悉报了很多错、还有数据库数据的格式和提取转换难点等问题。后面都一一解决了,
这次的项目让我得到了成长和提升,让我也对所学知识进行了学以致用,融会贯通。
最后感谢给我传授知识的广林哥、川哥等老师,祝你们家庭和睦,工作顺利。
这篇关于下厨房网站月度最佳栏目菜谱数据获取及分析PLus的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





