本文主要是介绍目标检测系列:yolov2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
yolov1虽然速度很快,但是其精确度和对小物体的敏感程度有待提高,所以提出了yolov2,在yolov1 的基础之上弥补了一些不足。
下图就是在yolov1基础之上的改进,一点点详细研究

1. batch norm 批量标准化。
批量归一化导致收敛的显着改善,而不需要其他形式的正则化。通过在YOLO中的所有卷积层上添加批量归一化,我们在mAP中获得超过2%的改进效果。批量规范化也有助于规范模型。使用批次标准化,我们可以从模型中dropout,而不会过度拟合。
batch norm已经成为了一个防止过拟合,加速训练的一个利器,关于bn层的详解,可以参考之前写的一个博客batch norm
2. 高分辨率分类器。
所有最先进的检测方法使用ImageNet预训练分类器。从AlexNet开始,大多数分类器对小于256×256的输入图像进行操作[8]。原来的YOLO在224×224分辨率上训练分类器网络,并将分辨率增加到448以用于检测。这意味着网络必须同时切换到学习目标检测并调整到新的输入分辨率。对于YOLOv2,我们首先在分辨率为448×448的分辨率下对ImageNet上的10个epoch进行微调。这种网络时间可以在较高分辨率输入上调整滤波器。然后我们在检测时微调所得到的网络。这种高分辨率分类网络使我们增加了近4%的mAP。
总结:由此当然也会带来一个问题,只管来看,图片分辨率越高,识别结果越好,但是同时处理的速度肯定会变慢,更加占用资源
3. 使用anchor boxes
之前的yolov1产生默认框的方式非常粗糙,只是简单的在每个grid上生成两个默认boxes,这个默认框肯定非常不好,丢失了好多信息,于是yolov2中,借鉴了faster rcnn的anchor思想,在每个grid上产生九中不同尺寸的boxes,并且和yolov1不同的是,yolov1的输入是224x224,经过五次步长为2的卷积后,最后一层的特征图是224/32=7,7x7的,在每个grid产生2个boxes,一共才7x7x2=96个推荐的默认boxes,显然这是不充足的,而在yolov2中,输入是416,经过五次步长为2的卷积后,最后一层的特征图是13x13,然后在每个grid产生9个boxes,于是每张图片产生,13x13x9=1521个默认的boxes,这个显然是够用的,而且由于每个格子产生的boxes大小不一,一定程度减轻了yolov1对小物体识别不好的问题。
总结和yolov1相比归纳为两点:
- 输入图片有224x224变成416x416
- 每个grid由yolov1的2个boxes变成了9个boxes
4. 使用聚类产生默认框尺寸
由上面可知,yolov2在每个grid产生9个尺寸的默认boxes,那么就不由得想到一个问题,这九个默认boxes怎么来的,在ssd中,这九个boxes的尺寸是按照一个公式得到的,在这里就分析那个公式了,因为在我看来,那个公式只是为了让论文更加高大上,并没有什么卵用,可以用一句话代替,由作者经验可得,实在没什么道理,什么样子的默认boxes才好?这个得针对数据集来说,比如voc2007中的物体偏大,那么这个九种尺寸应该稍微大点,而mscoco中物体略微偏小,那么这九个尺寸应该偏小才对,于是yolov2作者想到个办法,针对不同的数据集进行聚类分析,得到九种最贴近实际情况的默认boxes,这个非常有道理 。
我们知道,聚类迭代的过程,每个样本找与其距离最近的一个中心,但是这个聚类问题的距离应该怎么计算呢?作者给出了如下距离计算方式

而实验的结果更加说明了问题。经过试验后的结果更加说明了问题,实验评判好坏的标准没看懂是什么,不过问题不打,当他是个得分,结果说明聚类只要五个默认boxes就可以和anchor boxes的九个相比较,而当聚类中心为九个时,远远地甩开anchor boxes。

总结:这一部分算是作者为数不多的创新,没有借鉴别人的,而且单纯凭感觉来看,这样的结果应该也会挺好。
5.直接位置预测
这个应该说不是创新,而是延续了yolov1对位置坐标预测的方式,盗用一下别人的图, t x , t y , t h , t w t_x,t_y,t_h,t_w tx,ty,th,tw是我们要预测的值 σ ( t x ) , σ ( t x ) \sigma(t_x),\sigma(t_x) σ(tx),σ(tx)的作用是使其大小在[0,1]之间,也就是说中心要落在这个grid当中,在每个grid有五个默认boxes,而针对每个boxes预测五个值 t x , t y , t h , t w , t o t_x,t_y,t_h,t_w,t_o tx,ty,th,tw,to最后一个是说这个boxes有没有物体,也就是confidence,置信度的预测。
总结:关于这个地方和yolov1有个很不一样的地方,yolov1有个缺点,每个grid可以预测两个boxes,但是每个grid只能有一个物体,也就是说,关于物体分类,yolov1是以grid为单位的,而yolov2不是这样,可以有多个物体落入同一个grid,是按照boxes为单位进行预测的

6.Fine-Grained Features
这部分是借鉴SSD的思想,但是只借鉴一部分,SSD认为WxH越小,即低分辨率的特征图,预测的物体应该越大,而高分辨率的特征图拥有更多小物体的特征信息,于是想办法把高分辨率的特征图和低分辨率的结合起来,也就是说将26x26的特征图和13x13的特征图融合起来,融合链接是在通道进行链接的,方法也很简单,首先将26x26的特征图用步长为2的filter卷积一下,然后在通道连接。
总结:没什么创新点,只是借鉴SSD,还借鉴的不彻底,yolov3这部分要好很多
7 多尺度训练
顾名思义,可以用不同尺度的图片进行训练。原来的YOLO网络使用固定的448 * 448的图片作为输入,现在加入anchor boxes后,输入变成了416 * 416。目前的网络只用到了卷积层和池化层,那么就可以进行动态调整(意思是可检测任意大小图片)。作者希望YOLOv2具有不同尺寸图片的鲁棒性,因此在训练的时候也考虑了这一点。
不同于固定输入网络的图片尺寸的方法,作者在几次迭代后就会微调网络。没经过10次训练(10 epoch),就会随机选择新的图片尺寸。YOLO网络使用的降采样参数为32,那么就使用32的倍数进行尺度池化{320,352,…,608}。最终最小的尺寸为320 * 320,最大的尺寸为608 * 608。接着按照输入尺寸调整网络进行训练。
这种机制使得网络可以更好地预测不同尺寸的图片,意味着同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。
在小尺寸图片检测中,YOLOv2成绩很好,输入为228 * 228的时候,帧率达到90FPS,mAP几乎和Faster R-CNN的水准相同。使得其在低性能GPU、高帧率视频、多路视频场景中更加适用。
8 做了更多的实验
我只想说一个字,kao,这也算创新点?这是实验结果,看这个结果是不是觉得怎么yolov2的精度这么高,速度这么快,居然比faster rcnn还好。速度快我承认,但是不能无脑说精度高,比什么faster rcnn还好,因为你要注意输入图片的大小,yolov2的高精度很大一部分原因是图片的高分辨率原因,直观来看,图片分辨率越高,对实验结果越好,有一点不得不说,虽然图片变大了,但是速度还是很快,这个毋庸置疑,其实如果目标检测的很多应用都要求实时性,二阶段的方法精度是高,但是速度太慢这导致工业上很难应用二阶段方法,虽然一阶段方法精度稍低一点(现在都差不太多),但是速度快很多,可以达到实时,而且实现也更简单,所以说,我更加看好一阶段方法。
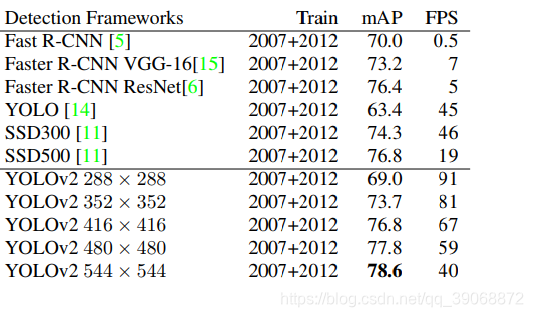
速度更快
由上面表可以看出来,不吹不黑yolov2的速度还是很快的,很明显这个肯定是网络架构的问题,大多数检测网络有赖于VGG-16作为特征提取部分,VGG-16的确是一个强大而准确的分类网络,但是复杂度有些冗余。224 * 224的图片进行一次前向传播,其卷积层就需要多达306.9亿次浮点数运算。
YOLOv2使用的是基于Googlenet的定制网络,比VGG-16更快,一次前向传播仅需85.2亿次运算。可是它的精度要略低于VGG-16,单张224 * 224取前五个预测概率的对比成绩为88%和90%,计算次数是vgg16的四分之一左右,而精度低了接近10%这其实非常可以接受了。
总结:这给我们提了个醒,在以后看目标检测文章时,如果速度非常快,大部分原因都是网络架构的更轻便,计算次数少
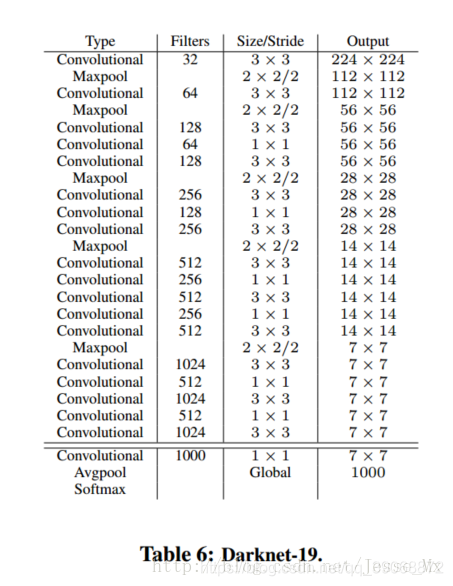
上图是yolov2的的主体网络框架,Darknet-19,之所以是19,是因为一共有19次卷积层,当然这里的卷及结构都是conv+bn+relu的结构,也就是说要考虑batch norm。
总结
yolov2的主体还是沿用了yolov1的 ,只是将ssd和faster rcnn的很多优点拿了过来,并加了为数不多的创新,最关键的地方是做了大量实验,看看完全是作者新提出的想法:
- 提出darknet-19网络架构,相比于vgg16大量降低了计算量,保证了一阶段方法的速度
- 提出了利用聚合的方法给出默认框的尺寸
- 多尺度进行训练(faster rcnn有没有给忘了,再看再说)
要是没看错的话完全自助创新的好像只有这些,剩下的就是将别人的(faster rcnn,ssd)和自己的之前的(yolov1)进行融合,最重要进行实验调参数,得出的实验结果不错,可以发论文了!
这篇关于目标检测系列:yolov2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









