本文主要是介绍浙大计算机系录取分数线2019,重磅数据!浙大2019、2020年三位一体各专业初审入围分数线曝光!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2020年,浙江省高水平大学“三位一体”招生考试院校减少,北京大学、清华大学、中国科学技术大学均取消了在浙江省的“三位一体”综合评价招生计划。这样,浙江省高水平大学减少“三位一体”综合评价招生计划290人,取而代之的是“强基计划”和高考裸分录取。

(1)北京大学在浙江省裸分招生41人,增加了31人。强基计划录取64人。
(2)清华大学在浙江省裸分录取29人,增加了21人。强基计划录取70人。
(3)中国科学技术大学在浙江省录取70人,强基计划录取35人。

那么,浙江大学、上海交通大学、复旦大学等高水平大学三位一体综合评价入围分数线是多少呢?
我们以浙江大学为例,加以分析说明。
一、浙江大学2014-2020年“三位一体”综合评价招生计划
(1)2014年,招收100人。
(2)2015年,招收300人。
(3)2016年,招生400人。
(4)2017年,招生650人。
(5)2018年,招生700人。
(6)2019年,招生800人。
(7)2020年,招生850人。

二、浙江大学“三位一体”综合评价限制选科选考要求
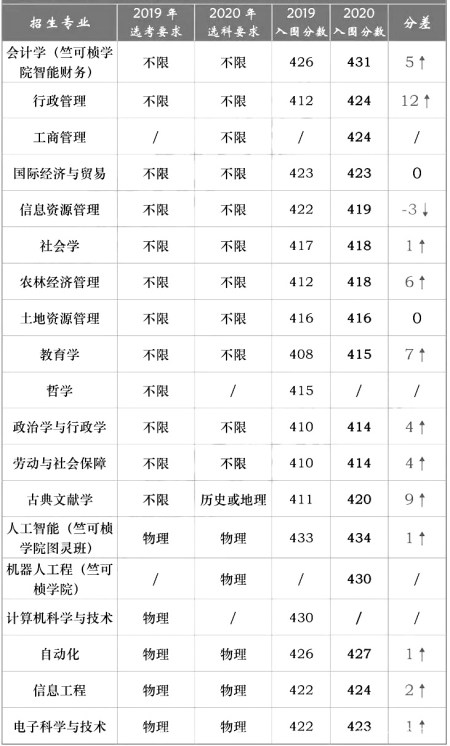
(1)不限制选科选考的专业,共11个。(详见下表)
(2)必须选物理学科的专业,共26个。(详见下表)
(3)限制选考历史或地理的,只有1个。(详见下表)
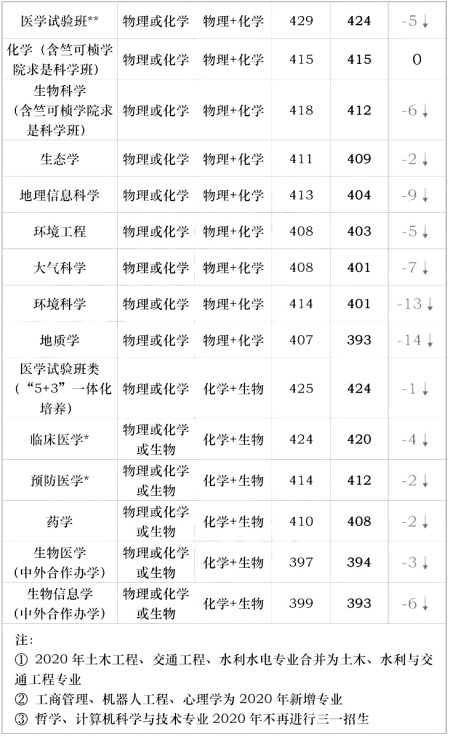
(4)限制选考物理+化学的,共15个。(详见下表)

三、浙江大学2020年“三位一体”综合评价初审入围分数线
浙江大学“三位一体”综合评价分数线以英语首考分数+三门选考首考的分数总分为依据(英语总分150分,三门选考共100分,共300分,满分450分。当年,北京大学、清华大学“三位一体”综合评价的最低入围分数线是430分,可见入围浙江大学并非易事)。
(1)在不限制选考的11个专业中,会计学(竺可桢学院智能财务)专业最高,431分。最低的是政治学与行政学,劳动与社会保障专业,414分。
(2)在26个必须选考物理的专业中,入围分数线最高的是人工智能专业,433分,计算机科学与技术专业,430分。不含中外合作办学专业,最低的是过程装备与控制工程专业,406分。
含中外合作办学专业,最低入围分数线是土木工程专业,398分。
(3)在必须选考物理+化学的15个专业中,入围分数线的是医学试验班专业,429分。不含中外合作办学专业,最低入围分数线的专业是地质学,407分。
含中外合作办学专业,入围分数线最低的专业是生物医学,397分。

四、录取浙江大学的基本途径简析

(1)分数线最低,“三位一体”综合评价招生,国家专项计划、地方专项计划、高校专项计划招生,分数线一般低于高考统一招生分数线。
(2)提前批,农林海洋专业,低于高考裸分。
(3)高考统一招生录取,2019年最低录取分数线是666分(位次号4700左右)。2020年是659分(5565名)。
(4)保送生,相对较难,文化课必须是五大学科奥林匹克竞赛国家集训队队员,才有资格。外语保送生,必须是浙江省杭州外国语学校的学生才行。
(5)高水平运动员,高水平运动队,高水平艺术团的成员,也有相当难度,没有一定的水平,只能作为旁观者。
作为2021、2022届考生,必须深入了解高水平大学“三位一体”综合评价招生计划和招生简章,以及近年来招生模式,笔试和面试试题,并把握机会,方有可能实现录取浙江大学的理想。
如果读者还有其他的问题和想法,请您留言。
祝愿莘莘学子金榜题名,录取心仪的大学和满意的专业!
这篇关于浙大计算机系录取分数线2019,重磅数据!浙大2019、2020年三位一体各专业初审入围分数线曝光!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









