本文主要是介绍NSSCTF之Misc篇刷题记录(15),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NSSCTF之Misc篇刷题记录(15)
- [GXYCTF 2019]SXMgdGhpcyBiYXNlPw==
- [GXYCTF 2019]佛系青年
- [GXYCTF 2019]gakki
- [suctf 2019]签到题
- [安洵杯 2019]吹着贝斯扫二维码
- [watevrCTF 2019]Evil Cuteness
- [RoarCTF 2019]黄金6年
- [EIS 2019]misc1
- [GWCTF 2019]huyao (频域盲水印)
- [HBNIS 2019]Doc是什么鬼
- [HBNIS 2019]爱因斯坦
NSSCTF平台:https://www.nssctf.cn/
[GXYCTF 2019]SXMgdGhpcyBiYXNlPw==
考点:Base64 隐写
直接看大佬 wp就好 我写不来 要是有python2 运行不然报错的!
# base64隐写
import base64def get_diff(s1, s2):base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'res = 0for i in range(len(s2)):if s1[i] != s2[i]:return abs(base64chars.index(s1[i]) - base64chars.index(s2[i]))return resdef b64_stego_decode():file = open("flag.txt", "rb")x = '' # x即bin_strlines = file.readlines()for line in lines:l = str(line, encoding="utf-8")stego = l.replace('\n', '')realtext = base64.b64decode(l)realtext = str(base64.b64encode(realtext), encoding="utf-8")diff = get_diff(stego, realtext) # diff为隐写字串与实际字串的二进制差值n = stego.count('=')if diff:x += bin(diff)[2:].zfill(n * 2)else:x += '0' * n * 2i = 0flag = ''while i < len(x):if int(x[i:i + 8], 2):flag += chr(int(x[i:i + 8], 2))i += 8print(flag)if __name__ == '__main__':b64_stego_decode()
NSSCTF{fazhazhenhaoting}
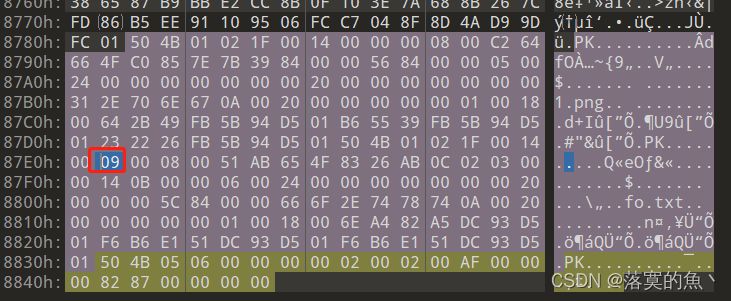
[GXYCTF 2019]佛系青年


图片放入010 发现存在伪加密09改为00

在线与禅论佛:https://ctf.bugku.com/tool/todousharp
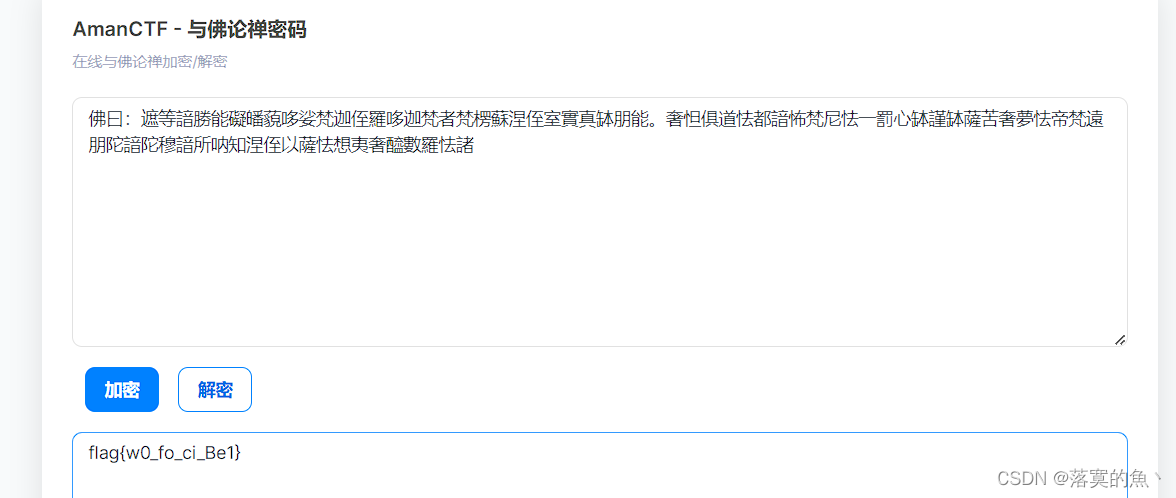
NSSCTF{w0_fo_ci_Be1}
[GXYCTF 2019]gakki
考点:字频统计
得到一张图片 binwalk -e 分离 然后使用ARCHPR爆破得到密码:8864
发现一段很长的字符串 想到了字频统计统计里面字符的次数 然后排序 上脚本。

# -*- coding:utf-8 -*-
#Author: mochu7
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*()_+- =\\{\\}[]"
strings = open('./flag.txt').read()result = {}
for i in alphabet:counts = strings.count(i)i = '{0}'.format(i)result[i] = countsres = sorted(result.items(),key=lambda item:item[1],reverse=True)
for data in res:print(data)for i in res:flag = str(i[0])print(flag[0],end="")
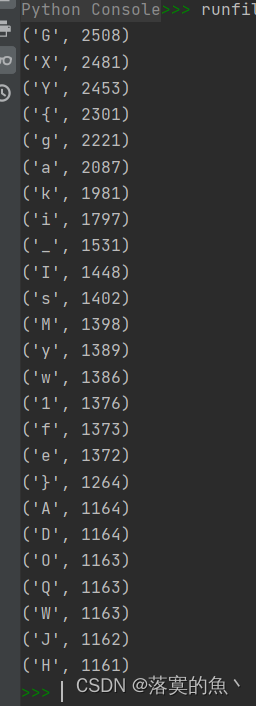
NSSCTF{gaki_IsMyw1fe}
[suctf 2019]签到题
在线Base64转图片:https://tool.jisuapi.com/base642pic.html

NSSCTF{fffffffffT4nk}
[安洵杯 2019]吹着贝斯扫二维码
发现很多文件没后缀放入010发现都是jpg文件 ren 批量加后缀 ren * *.jpg 我只能说很神奇!!


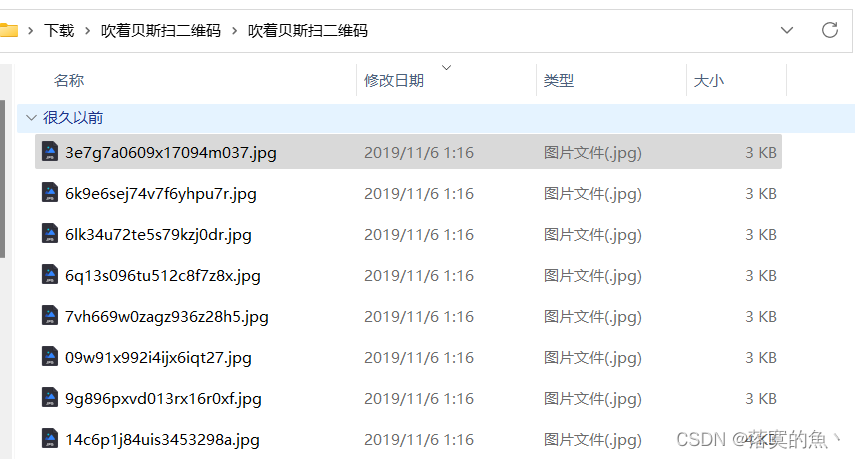
别忘了把flag.jpg改回zip 因为这个命令是改全部的 找个脚本拼一下 不然要累死你
import os
from PIL import Image#目录路径
dir_name = r"./"
#获取目录下文件名列表
dir_list = os.listdir('./')
#print(dir_list)#从列表中依次读取文件
for file in dir_list:if '.jpg' in file:f=open(file ,'rb')n1 = str(f.read())n2 = n1[-3:] #经过测试发现这里要读取最后3个字节,因为最后还有一个多余的字节,不知道是不是转字符串的原因导致在末尾多了一个字符#print(file) #输出文件内容#print(n2)f.close() #先关闭文件才能重命名,否则会报`文件被占用`错误os.rename(file,n2+'.jpg') #重命名文件
85->64->85->13->16->32 扫码得到的信息 base全家桶呗 直接随波一下
最终密码为:ThisIsSecret!233 打开压缩包 ok得到flag。
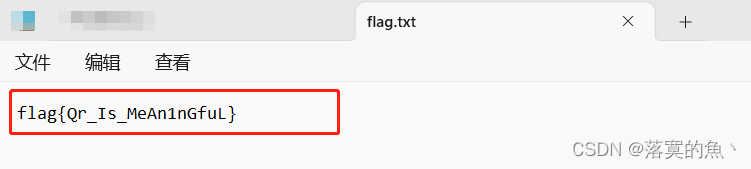
NSSCTF{Qr_Is_MeAn1nGfuL}
[watevrCTF 2019]Evil Cuteness
直接binwalk -e 分离 打开就是flag 送分题

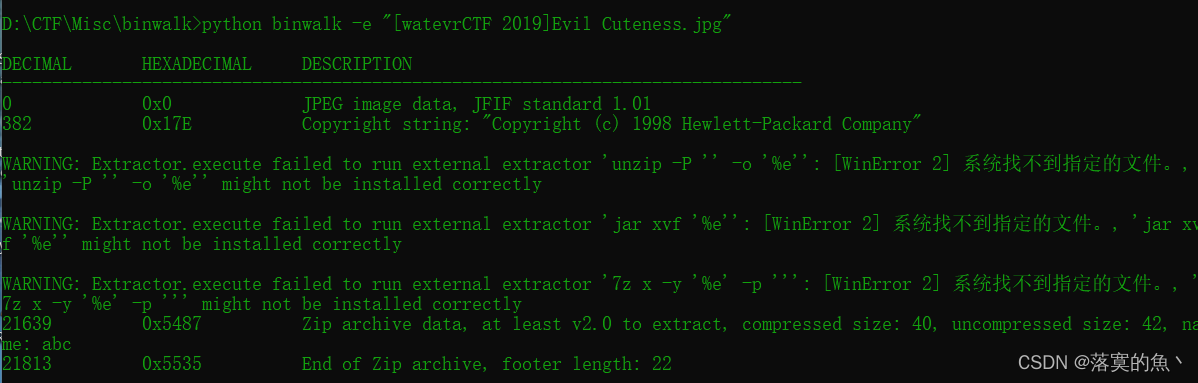
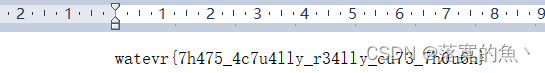
NSSCTF{7h475_4c7u4lly_r34lly_cu73_7h0u6h}
[RoarCTF 2019]黄金6年
mp4文件 直接010看其实里面有二维码肉眼可以看 就是麻烦
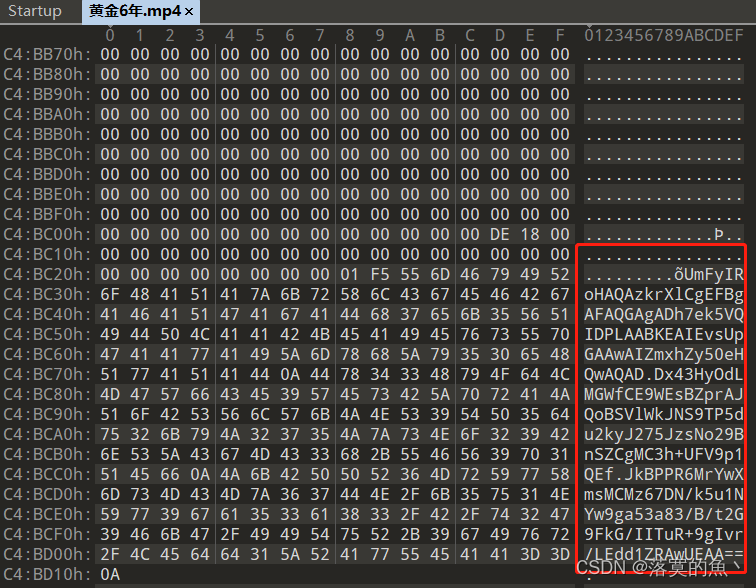
在线Base64:https://base64.us/
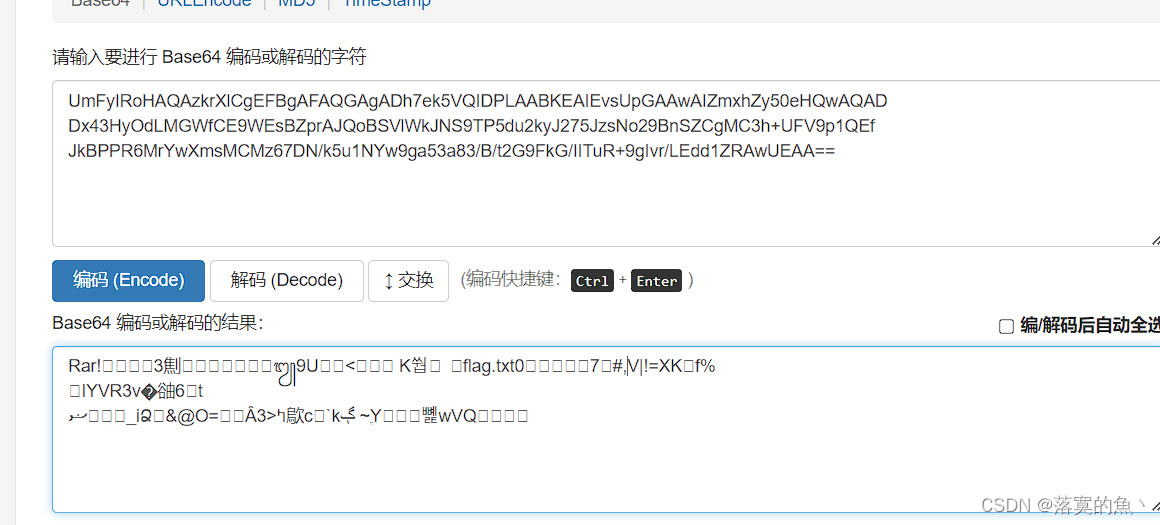
发现是rar特征 直接脚本转为rar文件 然后是加密的
import base64
code="UmFyIRoHAQAzkrXlCgEFBgAFAQGAgADh7ek5VQIDPLAABKEAIEvsUpGAAwAIZmxhZy50eHQwAQADDx43HyOdLMGWfCE9WEsBZprAJQoBSVlWkJNS9TP5du2kyJ275JzsNo29BnSZCgMC3h+UFV9p1QEfJkBPPR6MrYwXmsMCMz67DN/k5u1NYw9ga53a83/B/t2G9FkG/IITuR+9gIvr/LEdd1ZRAwUEAA=="
r=base64.b64decode(code)
test_file=open("test.rar","wb")
test_file.write(r)
test_file.close()

密码爆破了没结果 这里学习个新工具Kinovea将二维码全部提取 QR扫
以此类推最后拼接:iwantplayctf

NSSCTF{CTF-from-RuMen-to-RuYuan}
[EIS 2019]misc1
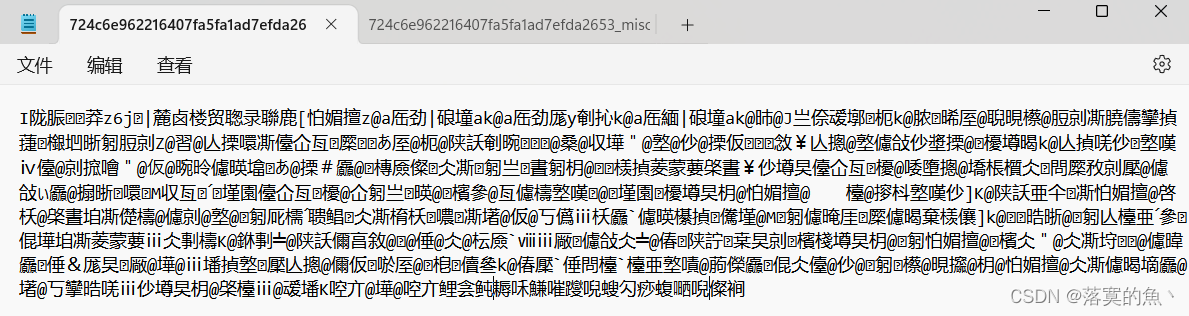
乱码使用word打开 初始编码会让你选择 这里不要使用默认 选其他可以看到flag。
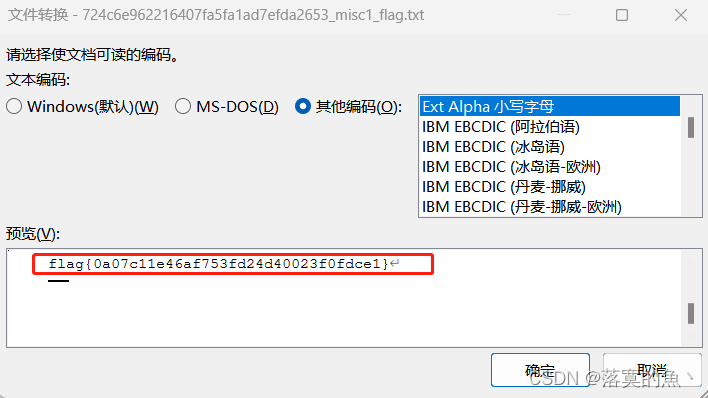
NSSCTF{0a07c11e46af753fd24d40023f0fdce1}
[GWCTF 2019]huyao (频域盲水印)
考点:频域盲水印
pip install opencv-python #安装库
# coding=utf-8
import cv2
import numpy as np
import random
import os
from argparse import ArgumentParser
ALPHA = 5
def build_parser():parser = ArgumentParser()parser.add_argument('--original', dest='ori', required=True)parser.add_argument('--image', dest='img', required=True)parser.add_argument('--result', dest='res', required=True)parser.add_argument('--alpha', dest='alpha', default=ALPHA)return parser
def main():parser = build_parser()options = parser.parse_args()ori = options.oriimg = options.imgres = options.resalpha = options.alphaif not os.path.isfile(ori):parser.error("original image %s does not exist." % ori)if not os.path.isfile(img):parser.error("image %s does not exist." % img)decode(ori, img, res, alpha)
def decode(ori_path, img_path, res_path, alpha):ori = cv2.imread(ori_path)img = cv2.imread(img_path)ori_f = np.fft.fft2(ori)img_f = np.fft.fft2(img)height, width = ori.shape[0], ori.shape[1]watermark = (ori_f - img_f) / alphawatermark = np.real(watermark)res = np.zeros(watermark.shape)random.seed(height + width)x = range(height / 2)y = range(width)random.shuffle(x)random.shuffle(y)for i in range(height / 2):for j in range(width):res[x[i]][y[j]] = watermark[i][j]cv2.imwrite(res_path, res, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
if __name__ == '__main__':main()
python3 BlindWaterMarkplus.py --original <original image file> --image <image file> --result <result file>
original 是输入原图, image是之后跟的是加入了水印的图, result是保存水印图片。
Github:https://github.com/kindred-adds/BlindWaterMarkplus

NSSCTF{BWM_1s_c00l}
[HBNIS 2019]Doc是什么鬼
放入010 看到xml格式 修改后缀zip 打开Flag.xml即是flag
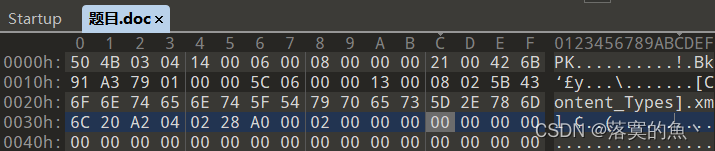
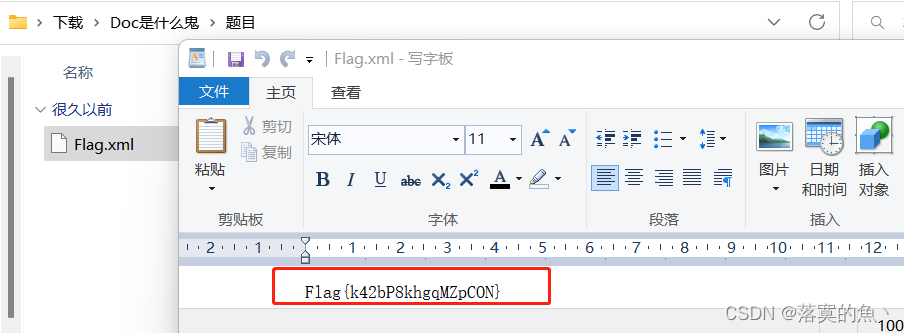
NSSCTF{k42bP8khgqMZpCON}
[HBNIS 2019]爱因斯坦
看到图片先想到看属性有没有利用信息 一般很少在属性(这里有 这个是解压密码)
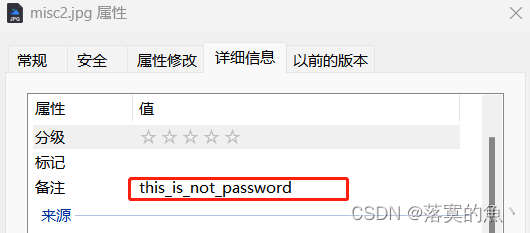
binwalk -e 分离 然后有个加密的txt 输入密码即可。
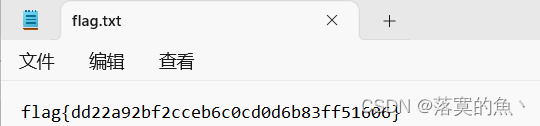
NSSCTF{dd22a92bf2cceb6c0cd0d6b83ff51606}
这篇关于NSSCTF之Misc篇刷题记录(15)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






