本文主要是介绍python3搜狐新闻时政板块 标题+内容+图片+对应http 实现二级爬取 并存入MongoDB数据库 附源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、需求分析项目描述
- 1. 实现搜狐新闻爬取
- 2.进行二级爬取
- 3.存入MongoDB
- 4. 导出数据为csv文件
- 二、 实现过程
- 1. 获取url
- 三、爬取新闻名称及其超链接
- 五、爬取文章内容及图片
- 四、连接并存入MongoDB
- 实现代码
- 运行结果
- 五、总代码
- 注意:
一、需求分析项目描述
1. 实现搜狐新闻爬取
在搜狐新闻网页中的时政分类下,爬取新闻标题以及对应的url,如下图
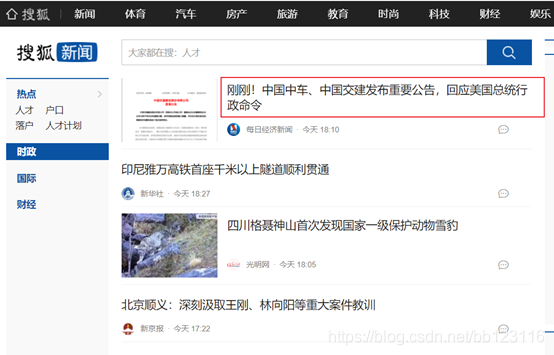
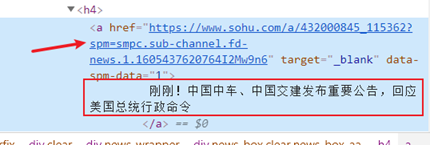
2.进行二级爬取
进入对应的url爬取相应的新闻内容及图片
3.存入MongoDB
将所有的标题、对应的url、文章内容、图片存到MongoDB下wb_bigdata数据库的news表格中
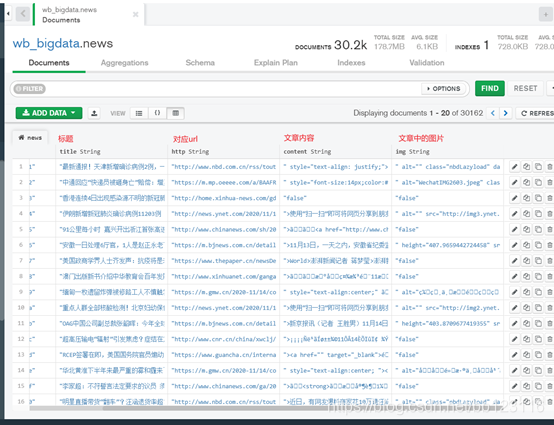
4. 导出数据为csv文件
二、 实现过程
1. 获取url
观察发现,搜狐新闻页面属于动态页面
但是F12——network——XHR下并没有文件所以不能从这里找
从ALL中发现该文件中有想要找的内容
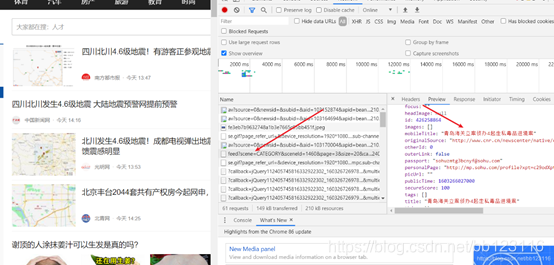
发现该文件属于js文件
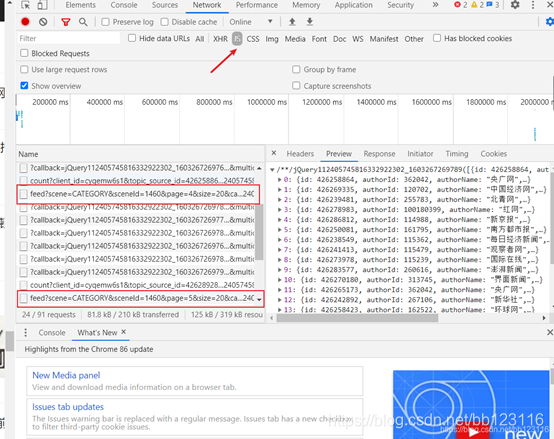
观察四个feed开头的文件的url规律

page变化 callback变化无规律 最后的数字每页+8 将callback去掉发现对网页内容无影响
所以最终的page获取 采用字符串拼接的形式
三、爬取新闻名称及其超链接
本次用正则表达式获取
实现代码:
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'自己的cookie'}res=requests.get(url,headers=headers)soup=BeautifulSoup(res.text,'lxml')news=re.findall('"mobileTitle":"(.*?)",',str(soup))herf=re.findall('"originalSource":"(.*?)"',str(soup))news_dic=dict(zip(news,herf))#把标题和链接储存到字典for k,v in news_dic.items():news_dictall[k]=v #每一页的字典合并return(news_dictall)#返回总字典五、爬取文章内容及图片
由于搜狐新闻有的新闻的页面分布不同,及不能笼统的通过css定位或者class标签、xpath等定位
但所有内容都在
标签下
所以用正则来提取内容和图片信息
def url_content(url):#爬取内容headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'itssohu=true; BAIDU_SSP_lcr=https://news.hao123.com/wangzhi; IPLOC=CN3300; SUV=201021142102FD7T; reqtype=pc; gidinf=x099980109ee124d51195e802000a3aab2e8ca7bf7da; t=1603261548713; jv=78160d8250d5ed3e3248758eeacbc62e-kuzhE2gk1603261903982; ppinf=2|1603261904|1604471504|bG9naW5pZDowOnx1c2VyaWQ6Mjg6MTMxODgwMjEyODc2ODQzODI3MkBzb2h1LmNvbXxzZXJ2aWNldXNlOjMwOjAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMHxjcnQ6MTA6MjAyMC0xMC0yMXxlbXQ6MTowfGFwcGlkOjY6MTE2MDA1fHRydXN0OjE6MXxwYXJ0bmVyaWQ6MTowfHJlbGF0aW9uOjA6fHV1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1bmlxbmFtZTowOnw; pprdig=L2Psu-NwDR2a1BZITLwhlxdvI2OrHzl6jqQlF3zP4z70gqsyYxXmf5dCZGuhPFZ-XWWE5mflwnCHURGUQaB5cxxf8HKpzVIbqTJJ3_TNhPgpDMMQdFo64Cqoay43UxanOZJc4-9dcAE6GU3PIufRjmHw_LApBXLN7sOMUodmfYE; ppmdig=1603261913000000cfdc2813caf37424544d67b1ffee4770'}res=requests.get(url,headers=headers)#soup=BeautifulSoup(res.text,'lxml')'''html1 = etree.HTML(res.text)html_data=html1.xpath('//*[@id="mp-editor"]/p/text()')html_data2=''.join(html_data)'''soup=BeautifulSoup(res.text,'lxml')news=re.findall('<p([\S\s].*?)</p>',str(soup))news2=''.join(news)news_fin = re.sub(r'><img.*?/>>', ' ', news2)return news_fin
def url_img(url):#爬取图片headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'itssohu=true; BAIDU_SSP_lcr=https://news.hao123.com/wangzhi; IPLOC=CN3300; SUV=201021142102FD7T; reqtype=pc; gidinf=x099980109ee124d51195e802000a3aab2e8ca7bf7da; t=1603261548713; jv=78160d8250d5ed3e3248758eeacbc62e-kuzhE2gk1603261903982; ppinf=2|1603261904|1604471504|bG9naW5pZDowOnx1c2VyaWQ6Mjg6MTMxODgwMjEyODc2ODQzODI3MkBzb2h1LmNvbXxzZXJ2aWNldXNlOjMwOjAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMHxjcnQ6MTA6MjAyMC0xMC0yMXxlbXQ6MTowfGFwcGlkOjY6MTE2MDA1fHRydXN0OjE6MXxwYXJ0bmVyaWQ6MTowfHJlbGF0aW9uOjA6fHV1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1bmlxbmFtZTowOnw; pprdig=L2Psu-NwDR2a1BZITLwhlxdvI2OrHzl6jqQlF3zP4z70gqsyYxXmf5dCZGuhPFZ-XWWE5mflwnCHURGUQaB5cxxf8HKpzVIbqTJJ3_TNhPgpDMMQdFo64Cqoay43UxanOZJc4-9dcAE6GU3PIufRjmHw_LApBXLN7sOMUodmfYE; ppmdig=1603261913000000cfdc2813caf37424544d67b1ffee4770'}res=requests.get(url,headers=headers)soup=BeautifulSoup(res.text,'lxml')news=re.findall('<p([\S\s].*?)</p>',str(soup))news2=''.join(news)img=re.findall('><img(.*?)/>',news2)img_fin=' '.join(img)
return img_fin四、连接并存入MongoDB
我这里用的是MongoDBcompass可视化界面。MongoDB的下载安装及打开方式不做详解,安装好后必须先从cmd下打开MongoDB并保持cmd界面开启状态,然后连接到MongoDBcompass
先创建好数据库和news表格用于存放要爬取的数据
实现代码
def w_mongodb(results):myclient = pymongo.MongoClient('mongodb://127.0.0.1:27017')#链接到MongoDBmydb = myclient["wb_bigdata"]#链接到数据库mycol = mydb["news"]#连接到表for result in results:myset = [result]mycol.insert_many(myset)#写入
print("成功")
写入MongoDB较难的是它的写入格式,试了许多都不行,我只会用迭代器yeild的方式才可以成功存入
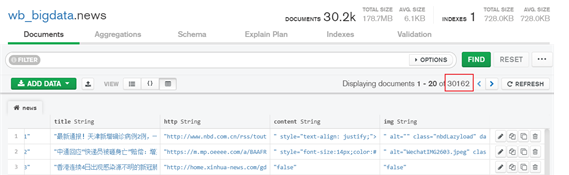
运行结果
所有的时政类新闻爬下来只有三千多条
我这里三万多条做了点小弊为了交作业哈 嘿嘿
五、总代码
import requests
from bs4 import BeautifulSoup
import jieba
from gensim.corpora.dictionary import Dictionary
import re
import jieba.analyse as ana
import pymongo
from pymongo import MongoClient
from lxml import etreedef getdata(p):
#——————————这里还有许多其余类的一级页面url——————————#news_all=[]news_dictall={}#for p in range(1,10):p2=1603263206992+p*8 #时政url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=1460&page='+str(p)+'&size=20&_='+str(p2)#p2=1605362952041+p*8#国际#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=1461&page='+str(p)+'&size=20&_='+str(p2)#p2=1605364376221+p*8#财经#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=1463&page='+str(p)+'&size=20&_='+str(p2)#p2=1605365229867+p*8#人才#url='https://v2.sohu.com/public-api/feed?scene=TAG&sceneId=77953&page='+str(p)+'&size=20&_='+str(p2)#p2=1605365922371+p*8#户口#url='https://v2.sohu.com/public-api/feed?scene=TAG&sceneId=77955&page='+str(p)+'&size=20&_='+str(p2)#p2=1605407205739+p*8#url='https://v2.sohu.com/public-api/feed?scene=TAG&sceneId=77954&page='+str(p)+'&size=20&_='+str(p2)#p2=1605407927805+p*8#url='https://v2.sohu.com/public-api/feed?scene=TAG&sceneId=77591&page='+str(p)+'&size=20&_='+str(p2)#p2=1605407158357+p*8#url='http://v2.sohu.com/public-api/feed?scene=CHANNEL&sceneId=40&page='+str(p)+'&size=20&_='+str(p2)#p2=1605410343014+p*8#互联网#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=911&page='+str(p)+'&size=20&_='+str(p2)#p2=1605410610877+p*8#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=934&page='+str(p)+'&size=20&_='+str(p2)#p2=1605410902210+p*8#智能#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=882&page='+str(p)+'&size=20&_='+str(p2)#p2=1605411842723+p*8#生活#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=913&page='+str(p)+'&size=20&_='+str(p2)#p2=1605411923855+p*8#科学#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=881&page='+str(p)+'&size=20&_='+str(p2)#p2=1605411953479+p*8#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=880&page='+str(p)+'&size=20&_='+str(p2)#p2=1605411974784+p*8#url='https://v2.sohu.com/public-api/feed?scene=CATEGORY&sceneId=936&page='+str(p)+'&size=20&_='+str(p2)headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'itssohu=true; BAIDU_SSP_lcr=https://news.hao123.com/wangzhi; IPLOC=CN3300; SUV=201021142102FD7T; reqtype=pc; gidinf=x099980109ee124d51195e802000a3aab2e8ca7bf7da; t=1603261548713; jv=78160d8250d5ed3e3248758eeacbc62e-kuzhE2gk1603261903982; ppinf=2|1603261904|1604471504|bG9naW5pZDowOnx1c2VyaWQ6Mjg6MTMxODgwMjEyODc2ODQzODI3MkBzb2h1LmNvbXxzZXJ2aWNldXNlOjMwOjAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMHxjcnQ6MTA6MjAyMC0xMC0yMXxlbXQ6MTowfGFwcGlkOjY6MTE2MDA1fHRydXN0OjE6MXxwYXJ0bmVyaWQ6MTowfHJlbGF0aW9uOjA6fHV1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1bmlxbmFtZTowOnw; pprdig=L2Psu-NwDR2a1BZITLwhlxdvI2OrHzl6jqQlF3zP4z70gqsyYxXmf5dCZGuhPFZ-XWWE5mflwnCHURGUQaB5cxxf8HKpzVIbqTJJ3_TNhPgpDMMQdFo64Cqoay43UxanOZJc4-9dcAE6GU3PIufRjmHw_LApBXLN7sOMUodmfYE; ppmdig=1603261913000000cfdc2813caf37424544d67b1ffee4770'}res=requests.get(url,headers=headers)soup=BeautifulSoup(res.text,'lxml')news=re.findall('"mobileTitle":"(.*?)",',str(soup))herf=re.findall('"originalSource":"(.*?)"',str(soup))news_dic=dict(zip(news,herf))#把标题和链接储存到字典for k,v in news_dic.items():news_dictall[k]=v #每一页的字典合并return(news_dictall)#返回总字典
def ifsim(p):#将数据以迭代器的方式存入字典news_dic=getdata(p)#——————下面注释掉的是用于主题爬取的————————如果需要进行主题爬取只需要修改if v:为if commwords>0: 并把注释取消(还有主函数中topicwords的注释取消)即可'''news_dicfin={}ana.set_stop_words('D:\作业\python\文本挖掘\数据集\新闻数据集\data\stopwords.txt') # 输入停用词'''for k,v in news_dic.items():'''word_list=ana.extract_tags(k,topK=50,withWeight=False) #去除停用词+词频分析#word_lil.append(word_list)word_lil=[] for i in word_list:word_lil.append([i])#将分词转化为list in list 形式以便传入dictionaryword_dic=Dictionary(word_lil)#转化为dictionary词典形式 以便分析d=dict(word_dic.items())docwords=set(d.values())#相关度计算commwords=topicwords.intersection(docwords)#取交集'''if v:#交集>0符合条件的存入最终的字典try:#因为这里有的url不能直接打开会报错,为了避免爬虫停止,用try except抛出异常content=url_content(v)#print(content)img=url_img(v)news_dicfin={'title':k,'http':v,'content':content,'img':img}yield news_dicfin#print(news_dicfin)''' except:print("跳过")
def url_content(url):#爬取二级页面的内容headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'itssohu=true; BAIDU_SSP_lcr=https://news.hao123.com/wangzhi; IPLOC=CN3300; SUV=201021142102FD7T; reqtype=pc; gidinf=x099980109ee124d51195e802000a3aab2e8ca7bf7da; t=1603261548713; jv=78160d8250d5ed3e3248758eeacbc62e-kuzhE2gk1603261903982; ppinf=2|1603261904|1604471504|bG9naW5pZDowOnx1c2VyaWQ6Mjg6MTMxODgwMjEyODc2ODQzODI3MkBzb2h1LmNvbXxzZXJ2aWNldXNlOjMwOjAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMHxjcnQ6MTA6MjAyMC0xMC0yMXxlbXQ6MTowfGFwcGlkOjY6MTE2MDA1fHRydXN0OjE6MXxwYXJ0bmVyaWQ6MTowfHJlbGF0aW9uOjA6fHV1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1bmlxbmFtZTowOnw; pprdig=L2Psu-NwDR2a1BZITLwhlxdvI2OrHzl6jqQlF3zP4z70gqsyYxXmf5dCZGuhPFZ-XWWE5mflwnCHURGUQaB5cxxf8HKpzVIbqTJJ3_TNhPgpDMMQdFo64Cqoay43UxanOZJc4-9dcAE6GU3PIufRjmHw_LApBXLN7sOMUodmfYE; ppmdig=1603261913000000cfdc2813caf37424544d67b1ffee4770'}res=requests.get(url,headers=headers)#soup=BeautifulSoup(res.text,'lxml')soup=BeautifulSoup(res.text,'lxml')news=re.findall('<p([\S\s].*?)</p>',str(soup))news2=''.join(news)news_fin = re.sub(r'><img.*?/>>', ' ', news2)return news_fin
def url_img(url):#爬取二级页面图片headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36','cookie':'itssohu=true; BAIDU_SSP_lcr=https://news.hao123.com/wangzhi; IPLOC=CN3300; SUV=201021142102FD7T; reqtype=pc; gidinf=x099980109ee124d51195e802000a3aab2e8ca7bf7da; t=1603261548713; jv=78160d8250d5ed3e3248758eeacbc62e-kuzhE2gk1603261903982; ppinf=2|1603261904|1604471504|bG9naW5pZDowOnx1c2VyaWQ6Mjg6MTMxODgwMjEyODc2ODQzODI3MkBzb2h1LmNvbXxzZXJ2aWNldXNlOjMwOjAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMDAwMHxjcnQ6MTA6MjAyMC0xMC0yMXxlbXQ6MTowfGFwcGlkOjY6MTE2MDA1fHRydXN0OjE6MXxwYXJ0bmVyaWQ6MTowfHJlbGF0aW9uOjA6fHV1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1aWQ6MTY6czExZjVhZTI2NTJiNmM3Nnx1bmlxbmFtZTowOnw; pprdig=L2Psu-NwDR2a1BZITLwhlxdvI2OrHzl6jqQlF3zP4z70gqsyYxXmf5dCZGuhPFZ-XWWE5mflwnCHURGUQaB5cxxf8HKpzVIbqTJJ3_TNhPgpDMMQdFo64Cqoay43UxanOZJc4-9dcAE6GU3PIufRjmHw_LApBXLN7sOMUodmfYE; ppmdig=1603261913000000cfdc2813caf37424544d67b1ffee4770'}res=requests.get(url,headers=headers)soup=BeautifulSoup(res.text,'lxml')news=re.findall('<p([\S\s].*?)</p>',str(soup))news2=''.join(news)img=re.findall('><img(.*?)/>',news2)img_fin=' '.join(img)return img_fin
def w_mongodb(results):myclient = pymongo.MongoClient('mongodb://127.0.0.1:27017')#链接到MongoDBmydb = myclient["wb_bigdata"]#链接到数据库mycol = mydb["news"]#连接到表for result in results:myset = [result]mycol.insert_many(myset)print("成功")if __name__=='__main__':for p in range(1,5000):#topicwords={"疫情","新冠","肺炎","确诊","病例","阳性","疫苗","疾控"}#topicwords={"省","违法","犯罪","非法","作恶","案例","案件","司法","公安","警察","禁止","民政","刑事","民事","处罚","法律","身亡","省委","谴责","安全","袭击","关停"}sim=ifsim(p)w_mongodb(sim)
注意:
在输入MongoDB中使用了try catch,因为爬取二级页面url时,发现有的url不完整,用爬虫打开就会报错停止,为了防止这样的情况发生,使用try-catch抛出异常,并输出跳过,最终的输出结果就是 :
有“成功”和“跳过”两种,并且在爬取完所有内容后会疯狂输出成功——需要手动停止。
这篇关于python3搜狐新闻时政板块 标题+内容+图片+对应http 实现二级爬取 并存入MongoDB数据库 附源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







