本文主要是介绍学习教授LLM逻辑推理11.19,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习教授LLM逻辑推理
- 摘要
- 1 引言
- 2前言
- 2.1事件关系提取
- 2.2 演绎推理
- 3 揭示逻辑推理中的LLMS
- 3.1 LLM如何执行任务
- 3.1.1数据源
- 3.1.2实验装置
- 3.1.3 分析
- 3.2 LLM如何执行抽象多跳推理?
- 3.2.1数据来源
- 3.2.2 实验装置。
- 3.2.3 分析。
- 4 逻辑推理教学
- 4.1 LLM的上下文学习
- 4.2 基于生成的方法
- 4.2.1 结果
- 4.3 基于检索的方法
- 4.3.1主要结果
- 4.3.2消融研究
- 4.4 基于预训练的方法
- 4.4.1 预培训细节
- 4.4.2结果
- 4.4.3案例研究

摘要
大型语言模型(LLM)由于其卓越的语言生成能力和极强的泛化能力而受到学术界和工业界的极大关注。然而,当前的LLM仍然会输出不可靠的内容,由于其固有的问题(例如,幻觉)。为了更好地解开这个问题,在本文中,我们进行了深入的调查,系统地探讨LLM在逻辑推理的能力。更详细地说,我们首先调查LLM在逻辑推理的不同任务上的缺陷,包括事件关系提取和演绎推理。我们的研究表明,LLM在解决具有严格推理的任务时表现不佳,甚至会产生反事实的答案,这需要我们迭代地改进。因此,我们全面探索不同的策略,赋予LLM逻辑推理能力,从而使他们能够在不同的场景中生成逻辑上更一致的答案。基于我们的方法,我们还贡献了一个综合数据集(LLM-LR),涉及多跳推理的评估和预训练。通过对不同任务的大量定量和定性分析,验证了逻辑教学的有效性和必要性,为今后运用逻辑教学解决实际任务提供了借鉴。
1 引言
最近,大型语言模型(LLM)在许多不同的下游任务中取得了令人难以置信的进展,如GPT-3、ChatGPT和Llama。这些模型通常在过滤的网络数据和精选的高质量语料库(例如,社交媒体对话、书籍或技术出版物)的组合上进行培训。研究表明,LLM的涌现能力可以显示出很有前途的推理能力,而精选过程对于产生它们的零概率泛化能力是必要的。
尽管取得了这些显著的成就,但目前的LLM在流畅和可靠地生成高质量内容方面仍然存在一些问题。一个好的内容生成器应该产生逻辑上一致的答案,这些答案对于给定或先前的约束是合理的。然而,在处理需要严格逻辑推理的实际任务时,LLM有时会输出反事实。如图1所示,ChatGPT预测事件“FIRE”和“collapsed”之间的时间和因果关系是“simultaneous”和“cause”。根据先前的逻辑约束,即使在阅读上下文之前,我们也可以很容易地断言预测并不完全正确,因为在语义方面,“simultaneous”和“cause”相互冲突。一些著作将这些现象归因于其固有的缺陷(如幻觉、不忠),然而,如何理清并提高LLMS在这些任务中的能力仍然是一个悬而未决的问题。

为了深入了解LLMS在逻辑推理方面的不足并探索相应的解决方案,本文从多个维度对LLMS在解决推理任务方面进行了深入的研究。我们首先在两个实际场景中对LLMS的性能进行了评估,包括事件关系提取和演绎推理任务,两者都需要严格的推理能力来推断。
我们的实验结果表明:
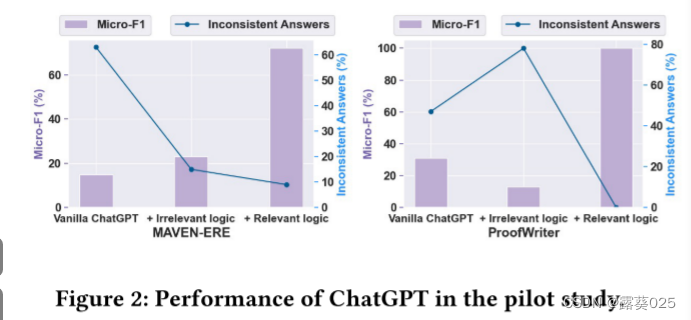
- 1)即使是最先进的LLM仍然会产生大量不一致的答案,例如,如图2所示,在MAVEN-ERE 数据集上来自ChatGPT的超过60%的答案在逻辑上是不一致的;
- 2)思想链(CoT)提示,如“让我们一步一步思考”可以刺激LLM的推理能力。然而,一些固有的问题(例如,幻觉、不忠实)将导致这种生成的基本原理不可靠或不一致;
- 3)向LLM提供相关逻辑提高了性能,但是注入不相关逻辑会引起结果的波动。因此,如何获得相关逻辑并将其信息注入LLM是一个重要的问题,值得进一步探索;
- 4)为了验证LLM用于更复杂推理的能力,我们提供了一个合成数据集(即,LLM-LR)进行评估,这涉及逻辑推理的多跳。LLM-LR是通过在我们收集的逻辑约束上应用逻辑编程自动构建的,它可以提供具有任意跳数的逻辑推理实例。结果表明,随着逻辑跳数的增加(2 ~ 10跳),LLM很难输出正确答案,逻辑不一致答案的比例稳步上升。这表明,当推理变得更加抽象和复杂时,LLM的表现会更差。
因此,如何缓解上述问题,使LLM具有更强大的逻辑推理能力是我们的论文的关键点。
基于这些发现,我们提出了一系列的解决方案,教LLM生成具有更好的逻辑一致性的答案。本文根据逻辑习得的途径,将LLM逻辑推理教学分为三种不同的教学模式:
- 1)生成型教学模式,它鼓励LLM在CoT提示的启发下自己生成推理原理。在这个范例下,我们发现,将逻辑约束纳入LLM指令将带来实质性的改进,但所生成的理由的不确定性也可能带来一些偏见,导致不正确的后续答案;
- 2)基于检索的方法,提供我们手动设计的逻辑约束,然后检索相关内容并将其添加到LLM指令。这种方法确保了逻辑约束的正确性,并显着提高了性能,但需要一些手工制作的工程;
- 3)基于预训练的方法,使用我们之前介绍的策展数据集LLM-LR来训练LLM执行复杂的逻辑推理。预训练数据集由6776个实例组成,包含2 ~ 5跳的逻辑推理。这种策略固有地将逻辑编码在模型参数中,同时还需要额外的训练时间。
因此,如何选择最合适的策略可以是一个权衡的基础上的实际情况。
此外,基于上述框架,我们还对不同的任务进行了大量的定量和定性分析,以验证逻辑教学的有效性,并为未来的工作提供启示:
- 1)我们研究了是否在获得结果之前或之后添加逻辑约束,并发现直接将约束传递给LLM比根据结果添加后处理操作更有效;
- 2)与使用更多演示的设置相比,将逻辑约束纳入提示可以用更少的演示实现更好的性能。这一现象进一步表明,它是重要的,教导LLM平衡演示和逻辑约束;
- 3)受益于LLM强大的交互能力,我们可以进一步提高性能,通过迭代检索增强多轮会话。然而,当有太多的迭代时,LLM可能会有过度思考的问题-更多无用和冗余的信息会干扰它们的预测;
- 4)当在LLM-LR上训练时,LLM(如LlaMA 2-13B)可以实现更好的性能,甚至超过更大的LLM(例如,ChatGPT,175 B),这验证了我们策划的数据集的有效性。
总体而言,我们的论文的贡献可以总结如下:
- 我们提供了一个深入的调查,目前的LLM在解决实际任务的逻辑不一致的问题,并指出LLM在利用逻辑的不足。
- 为了提高LLM生成的内容的可靠性,我们提出了几种解决方案来整合相关逻辑。基于我们的方法,我们构建了一个合成数据集(LLM-LR)涉及多跳推理。通过利用LLM-LR,我们赋予专门的LLM逻辑推理能力,这增强了LLM生成逻辑上更一致的答案。
- 不同任务的实验结果与定量和定性分析验证了我们的调查在赋予LLM逻辑推理能力方面的重要性。
2前言
在本节中,我们首先介绍本文主要探讨的两个任务。
2.1事件关系提取
事件关系提取(ERE)旨在识别关系(即,共指、时间、因果和子事件)。传统上,它可以被公式化为多标签分类问题,为每个关系类型确定一个标签。与其他常见任务相比,ERE任务应该更多地考虑事件关系之间的逻辑约束(例如,图1中的约束),并保证预测应符合这些约束,以避免反事实。因此,我们需要在预测过程中严格考虑每个事件对之间的逻辑约束。为了更好地评估能力的LLM的ERE任务,我们制定了逻辑一致性评估。
逻辑一致性在理解事件之间的关系中起着至关重要的作用。为了评估逻辑一致性,我们收集了一个全面的集合,包括两个事件之间所有关系的11个逻辑约束,如表4所示。基于这些逻辑约束,我们引入逻辑不一致性度量(即,LI)测量LLM在ERE任务上的能力。具体地,对于LLM的答案,逻辑不一致性被计算为冲突数量的比率(即,与给定逻辑约束冲突的答案)到组合总数(即,每两个关系的所有组合)。为了更好地说明逻辑不一致性的计算,这里我们介绍一个例子(如图1所示):如果LLM输出两个事件之间的关系为 “NO_COREFERENCE,SIMULTANEOUS,CAUSE,NO_SUBEVENT” 。
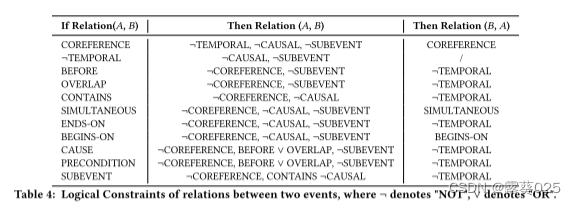

其中,基于我们已经定义的逻辑约束,“SIMULTANEOUS”和“CAUSE”被确定为相互冲突,导致一个单一的冲突。现在,关于组合的总数:对于每对事件,我们有4种类型的关系(共指,时间,因果和子事件关系)要确定。这些关系之间的总组合使用组合公式计算:4 *(4−1)/2 = 6。因此,两个事件之间的关系有6种可能的组合。因此,该示例中的逻辑不一致性被计算为LI = 1/6(或大约16.7%)。显然,给定逻辑约束,可以设计算法来自动检测冲突并计算逻辑不一致的值。总的来说,直观地说,逻辑不一致性的值越小,LLM可以产生的自洽和合理的答案就越多。有关此任务的更多描述见附录A。
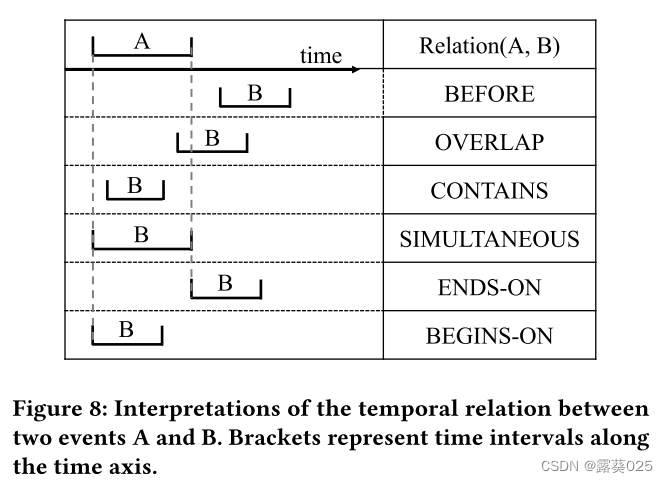
2.2 演绎推理
演绎推理通常从已知的事实和规则开始,然后迭代地进行新的推理,直到所需的陈述可以被证实或反驳。为了保证这些推理的准确性,演绎推理的每一步都必须遵守已知的逻辑约束(规则)。更具体地说,演绎推理中的逻辑约束通常是针对个别情况的,而不是像ERE任务中那样普遍适用。因此,在进行演绎推理时,必须根据每个例子的不同情况和已知事实评估和应用逻辑约束,以得出准确的结论。对于演绎推理的逻辑不一致性的计算,我们需要人工统计LLM产生的与已知事实或规则不一致的推理过程的数量,然后计算比例。
3 揭示逻辑推理中的LLMS
在本节中,我们进行了一项试点研究,以调查当前LLM在推理任务中的表现以及逻辑如何使LLM受益。
3.1 LLM如何执行任务
3.1.1数据源
我们对MAVENERE 和ProofWriter 进行手动评估。MAVEN-ERE是用于ERE任务的统一大规模数据集,该任务需要识别四种类型的关系。ProofWriter是演绎逻辑推理常用的数据集,其中每个示例是一对(问题,目标),标签选自{已证明,已反驳,未知}。为了采用我们的调查,我们随机选择100个样本(50个来自MAVEN-ERE和50个来自ProofWriter)。
3.1.2实验装置
我们的实验是作为一个多轮对话零样本推理,利用LLM的互动能力。给定一个任务输入(X),我们还编写一个描述任务的提示(T),并让LLM通过回答给定的查询来生成输出(Y)。我们还在预测生成的每个答案之前添加“Let’s think step by step”,这是一个简单但有效的技巧,可以改善LLM的零样本推理。我们采用ChatGPT作为主干,并在以下三个设置下手动检查其生成的基本原理:
- 基本版LLM(即,ChatGPT)没有任何附加信息;
- LLM(即,ChatGPT)加上最相关的(即ground truth)逻辑;
- LLM(即,ChatGPT)加上不相关的逻辑约束。提示符示例可以在图10- 13中找到。
"ground truth"指的是某个问题或命题的真实、准确的答案或陈述。在逻辑推理和推断过程中,"ground truth"是作为参考标准或基准的真实情况。LLM可以根据提供的信息和推理规则生成推断结果,然后将其与"ground truth"进行比较以评估其准确性。
3.1.3 分析
如图2所示,我们可视化了micro-F1和ChatGPT生成的逻辑不一致答案的比例。我们发现,无论是在MAVEN-ERE还是ProofWriter上,Vanilla ChatGPT总是以低micro-F1分数和高不一致值(例如,15%microF1和63% MAVEN-ERE上的不一致答案),这表明LLM在解决复杂推理任务时存在不足。为了深入研究这一问题,我们从以下两个方面进行分析。
逻辑一致性和模型性能之间的关系是什么?
从图2中,我们发现:
1)当添加相关逻辑时,模型直接在MAVEN-ERE和ProofWriter上获得了显著的改进;
2)当添加一些无关逻辑时,结果显示出一些波动(MAVEN-ERE的提升和ProofWriter的退化)。这意味着在没有任何约束的情况下直接添加逻辑会带来一定的不确定性;
3)通常,较高的逻辑不一致对应于较差的micro-F1,然而,纠正逻辑不一致并不一定会导致micro-F1的相同程度的增加。一般来说,一个直观的观察是,将相关的逻辑纳入LLM指令将非常有助于解决推理任务因此,挑战在于如何获得这些相关逻辑以及如何将它们用于LLM。
LLM通常会犯哪些类型的错误?
为了深入了解基础版LLM在逻辑推理中遇到的失败,我们还对此进行了详细的错误分析。在这里,我们将错误类型分为两个方面:
-
- 约束不正确(CE):与真实的逻辑约束相比,LLM生成的基本原理是错误的(CE1),不完整的(CE2)或冗余的(CE3)。
-
- 对推理过程(FE)不忠:LLM没有正确使用约束。我们在FE上定义两种类型的错误,即,i)错误的开始,LLM从一个不相关的事实开始,或者专注于正确答案的不正确观点(FE1)。ii)错误的过程,LLM从一个适当的点开始,但在推理过程中出错(FE2)。注释者被要求查看ChatGPT生成的100个预测并标记错误类型。

图3中的结果表明:
- 对推理过程(FE)不忠:LLM没有正确使用约束。我们在FE上定义两种类型的错误,即,i)错误的开始,LLM从一个不相关的事实开始,或者专注于正确答案的不正确观点(FE1)。ii)错误的过程,LLM从一个适当的点开始,但在推理过程中出错(FE2)。注释者被要求查看ChatGPT生成的100个预测并标记错误类型。
- 1)Vanilla ChatGPT产生的约束质量不够高,这限制了其后续推理能力。
- 2)通过对相关逻辑约束的描述,保证了约束的正确性,从而提高了ChatGPT生成质量的忠实性。
3.2 LLM如何执行抽象多跳推理?
基于上述分析,我们可以确认LLM在解决复杂推理任务方面的不足以及引入逻辑约束的有效性。然而,我们也想探索LLM如何在更具挑战性的环境中表现出来。
3.2.1数据来源
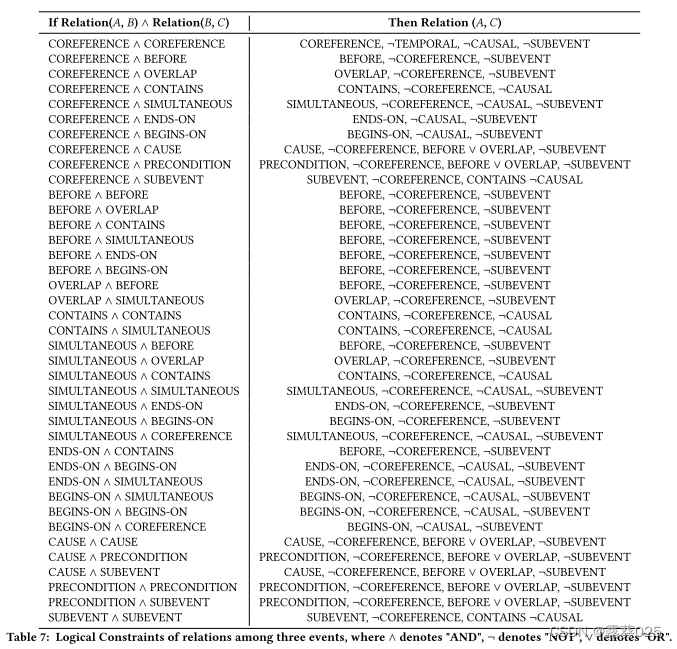
考虑到现有数据集缺乏多跳实例,我们构建了一个合成数据集(LLM-LR)来评估LLM执行多跳推理的能力。具体来说,我们首先为三个事件之间的所有高阶关系收集39个额外的逻辑约束,如表7所示。该集合基于传递依赖性(即,一个事件可以通过中间事件影响另一个事件)。例如,BEFORE(A,B)∧ BEFORE(B,C)→ BEFORE(A,C)表示"如果事件A在事件B之前发生, 并且事件B在事件C之前发生,那么事件A在事件C之前发生。" 因此,我们得到了一个包含总共50个逻辑约束的综合集合(沿着我们在2.1节中介绍的两个事件之间的11个约束)。
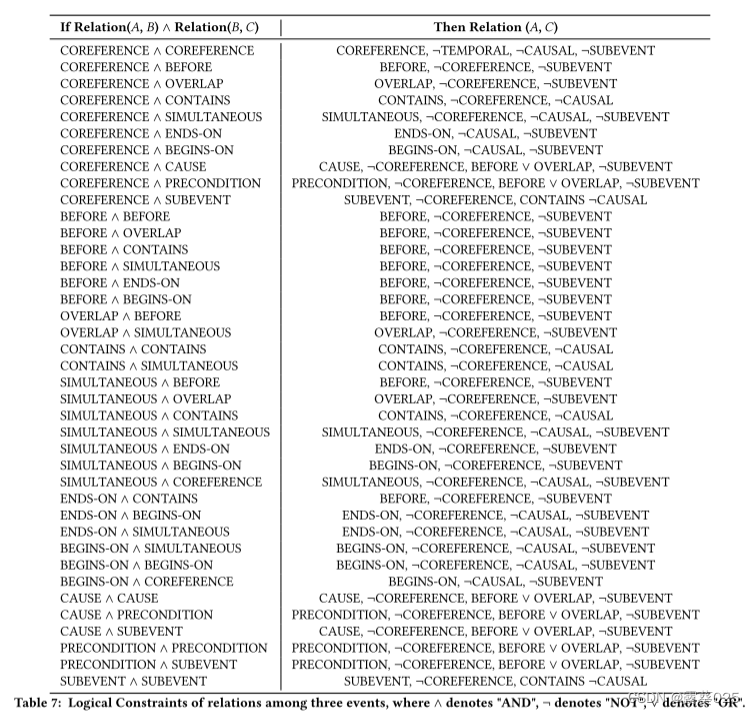
随着事件数量的进一步增加(即,>3),涉及到更复杂的交互,此时手动列出所有约束是低效的。为了解决这个问题,我们引入了逻辑编程,通过输入已知的约束和关系来自动生成新的事件关系。我们采用了基于前向和后向链接规则的方法,利用Prolog作为我们逻辑编程方法的基础。例如,当处理涉及四个事件(A,B,C,D)的时间关系时,给定已知的关系:“BEFORE(A,B) ∧ SIMULTANEOUS(B,C)∧ OVERTANEOUS(C,D)",我们的逻辑编程方法可以根据表7中的约束条件推导出"BEFORE(C , D)"的结论。
然后,我们提供一个任务描述,并使用给定的关系作为输入案例,让LLM推理事件之间的关系(A,D),即一个3跳查询。我们可以使用表6中提供的描述文本将符号表示转换为自然语言形式。

我们的逻辑引擎推导出的结论将作为地面真理检查LLM的答案。伪代码可以在附录D.1(如下)中找到,提示示例在图14中。


3.2.2 实验装置。
为了评估,我们为每个2 ~ 10跳推理随机生成50个样本。除了ChatGPT的三个变体(gpt-turbo,text-davinci-003和gpt 4)之外,我们还使用了另外两个开源LLM(Vicuna 13 B-v1.31和Llama 2 - 13 B)进行评估。注意:
1)对于2跳推理(即,三个事件之间的高阶关系),只有39个样本。
2)我们的方法允许扩展的推理路径,但我们报告的结果清晰,由于长度限制的LLM,仅覆盖2至10跳。
3.2.3 分析。
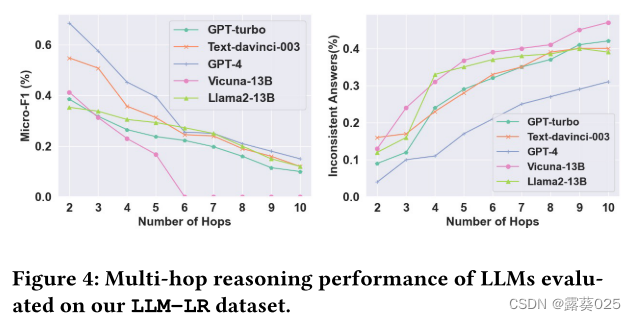
如图4所示,我们可视化了micro-F1和LLM生成的逻辑不一致答案的比例。我们可以看到:
1)当跳数相对较小时(即,2 ~ 15跳),GPT-4的性能与其他机型相比表现突出。
2)随着跳数的增加,所有LLM的性能变差,当推理变得越来越复杂,逻辑不一致的答案的比例逐渐增加。其中,维库纳-13 B在6跳后完全失效,无法输出任何正确答案。这进一步说明了LLM逻辑推理教学的必要性。
4 逻辑推理教学
基于上述分析,我们期望探索如何增强LLM的逻辑推理能力。因此,在本节中,我们首先介绍我们在4.1节中使用的推理跟踪技术,然后提出三种不同的方法来指导LLM生成具有更好逻辑一致性的答案(4.2节至4.4节)。
4.1 LLM的上下文学习
我们通过上下文学习(ICL)部署LLM用于事件关系提取和演绎推理任务。给定一个任务输入(𝑋),我们还编写一个𝑇描述该任务的prompt(),然后进一步提供几个演示𝐷= {𝐷𝑖}|𝐷|𝑖=1 . ,其中,Di=(Xi,Yi)用于少量学习。然后,LLM通过完成提示(Y=M(T, D, X))生成输出(Y),其中M表示LLM。在这样的设置中,LLM可以遵循所提供的演示的结构,以输出预期的答案格式,用于随后的自动评估。此外,整个过程不需要任何梯度更新,允许LLM在没有大量训练数据的情况下生成预测。
比较模型。
我们选择ChatGPT的三个变体(gptturbo、text-davinci-003和gpt 4)、维库纳-13 B-v1.3和Llama 2 - 13 B作为主要实验LLM进行评估。我们还提供了两个微调RoberTa-大基线(一次样本和完全微调)进行比较。RoBERTalarge的培训详情见附录B.2。
数据集构建。
我们的主要实验在MAVEN-ERE,Cause-TimeBank和ProofWriter上进行了评估。对于ERE任务,我们专注于两个事件之间的关系,并在句子水平上进行抽样。两个事件中没有任何关系的样本将被排除。在这里,我们从MAVEN-ERE的测试集中随机抽取了500个例子,从Cause-TimeBank的测试集中随机抽取了100个例子作为我们的测试平台。对于演绎推理任务,我们使用ProofWriter的OWA子集,它被分为五个部分,每个部分分别需要0,1,2,3和5跳的推理。我们评估最难的5跳子集。为了降低计算成本,我们在测试集中随机抽取200个样本,并确保标签分布的平衡。其他详细信息见附录B.1。
评价我们采用平均micro-F1分数作为评估指标,并报告了ERE数据集上的逻辑不一致性(定义见第2.1节)。报告值由三次运行的结果平均,以减少随机波动。
4.2 基于生成的方法
基于生成的方法意味着我们让LLM通过使用一次性ICL的形式生成逻辑。在这里,我们研究了三种变体:
(1) 基础版ICL:它利用由任务描述,演示和输入案例组成的常见提示。
(2) 基础版ICL加CoT:其首先通过使用思想链作为遵循给定演示的风格的中间推理步骤来引导基本原理,然后输出答案。这里的逻辑不涉及逻辑约束的内容。
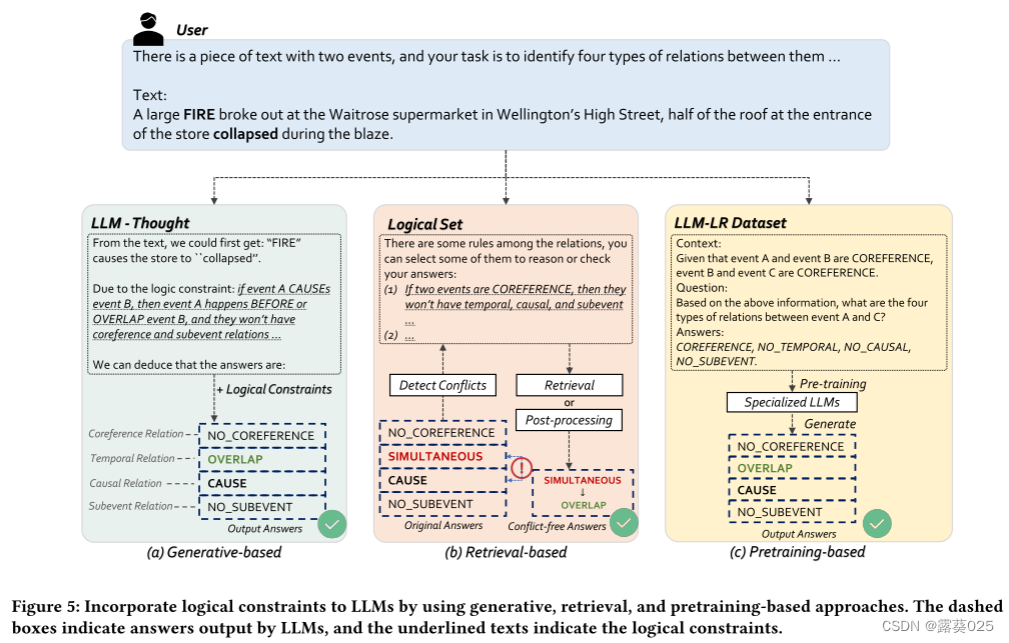
(3) CoT与自我生成的逻辑约束:它教导LLM基于CoT生成和利用逻辑约束(图5(a))。具体地说,它将首先提取明显的关系/事实,并根据提取的关系/事实产生相关的逻辑约束,然后我们执行LLM推断其余的关系/事实的基础上的约束和已知的关系/事实。提示示例见附录H.2。
4.2.1 结果
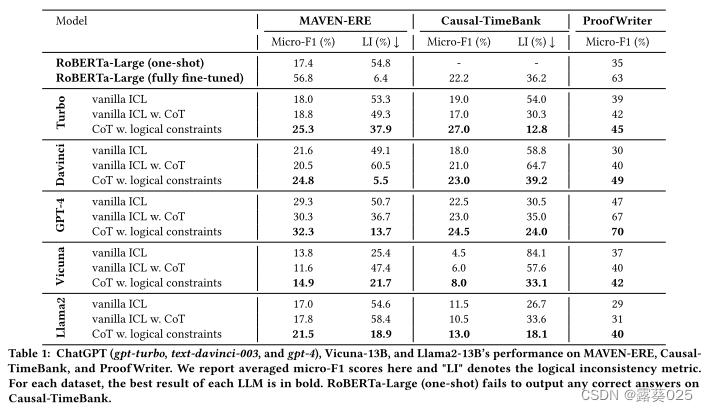
从表1中,我们可以观察到:
- 与较小的语言模型(SLM,即,Roberta-large),基础版LLM在两个任务下的泛化能力单杆设置是显着的,但仍然有一个完全微调基线的差距。
- 直接使用CoT来推断逻辑对ERE任务没有太大帮助,一个可能的原因是固有的问题可能导致LLM在精确的原理生成中失败(即,逻辑不一致的高比率)。在附录E中,我们给予了一个案例研究。
- 当使用基于生成的方法来鼓励LLM在推理过程中产生逻辑约束时,LLM可以显着提高它们在这两个任务上的性能。值得一提的是,GPT-4(CoT w.逻辑约束)甚至可以超过Proofwriter数据集上完全微调的基线。
4.3 基于检索的方法
虽然基于生成的方法使模型能够自动生成和利用逻辑,但LLM的预测通常是不确定和不准确的。因此,我们还提供了基于检索的方法,旨在从我们预定义的约束中获得相关的逻辑(图5(b))。我们主要利用收集到的逻辑约束条件在ERE任务上进行实验。具体来说,我们将2.1节中收集的11个约束作为检索集,我们的解决方案包括:
(1) 带所有逻辑约束:直接将集合中的所有11个逻辑约束相加。
(2) 与检索的逻辑约束:这意味着我们首先检测逻辑上不一致的答案的基础上预测的LLM,然后检索相应的信息,如果我们发现任何冲突。最后,我们将其添加到LLM指令中,并让LLM重新生成答案。详见附录C.1。
(3) 后处理:该算法首先得到LLM的答案,然后根据约束条件自动生成逻辑上一致的候选项,并随机选择其中一个作为最终答案。这种方法确保不存在逻辑冲突(LI = 0%)。详情请参见附录C.2。
4.3.1主要结果
从表2中,我们可以观察到:
1)当使用基于检索的方法来获得逻辑约束并将其并入LLM指令时,LLM的答案的逻辑不一致性大大降低,并且两个任务的整体性能进一步提高。
2)虽然我们的后处理保证了没有逻辑冲突(导致LI为0%),但它可能会严重影响整个生成的质量。一方面,由于随机选择,后处理答案的语义可能远离地面事实。另一方面,每个案例的候选集的大小也会影响性能。在后处理阶段,它可能还需要更多的操作,我们将其作为未来的工作。
4.3.2消融研究
我们在本小节中使用ChatGPT(gpt-turbo)进行消融研究。示威根据以前的经验,我们还将演示添加到提示符中,以研究当与不同数量的演示组合时,逻辑约束将如何影响。在这里,我们从{1,5,10,20}中选择不同数量的演示样本。试验在香草Turbo Davinci GPT-4维库纳美洲驼2号上进行ICL和ICL加上所有逻辑约束。从图6中我们可以观察到:1)当演示次数从1次增加到5次时,我们可以观察到明显的改善,但是当继续增加演示次数时,后续的改善是有限的(例如,≥ 10); 2)在LLM指令中添加逻辑约束可以提供稳定的改进,特别是在更多演示的情况下。3)将逻辑约束与较少数量的演示结合的性能甚至可以超过仅具有较大数量的演示的提示的性能(例如,在MAVEN-ERE w.逻辑约束占25.7%,超过10个无约束演示。逻辑限制,24.5%)。这表明告诉LLM“什么”(演示)和“如何”(逻辑约束)是很重要的。总体而言,这些研究进一步证实了使用逻辑约束解决推理任务的优点。迭代检索。考虑到LLM在交互方面的突出能力,我们进一步探讨是否可以在多话轮对话中引入逻辑约束(提示设计见附录H.3)。在这里,我们采用一种基于检索的方法来迭代地合并逻辑约束,结果如图6所示。我们发现,答案的逻辑不一致性会随着迭代次数的增加而逐渐减少,但总体微观F1似乎相对稳定。我们猜测造成这种现象的主要原因是LLM的过度思考,因为虽然它可以带来更多的推理原理,但在多次迭代时可能会产生正确但更无用或更丰富的信息。总的来说,用逻辑指导LLM有利于对话,但如何支持更长的信息仍然具有挑战性。
4.4 基于预训练的方法
虽然基于检索的方法保证了逻辑约束的正确性,但它仍然需要与外部集合不断交互.因此,我们提供了一种基于预训练的方法来将逻辑约束嵌入LLM本身。我们使用3.2节中介绍的逻辑编程方法自动生成6776个包含所有2 ~ 5跳推理数据的实例。考虑到LLM的计算复杂度和长度限制,我们在这里不生成更长的跳数进行训练。数据集统计数据见表5。然后,我们训练LLM基于策展数据集LLM-LR执行复杂的逻辑推理。最后,我们用训练好的LLM进行推理。训练数据的示例可以在图5(c)或图14中看到。
4.4.1 预培训细节
我们采用维库纳-13 B-v1.3和Llama 213 B作为基础模型,并采用LoRA [14]技术。在预训练期间,仅优化LoRA参数。其他详细信息见附录G。
4.4.2结果
如表3所示,我们发现:1)一旦在LLM-LR上训练,LlaMA 2 - 13 B和维库纳-13 B的性能与表1和表2相比有了很大的提高,特别是在没有逻辑约束的基线上。2)LlaMA 2 - 13 B-PT的性能甚至可以超过一些更大的LLM(例如,vanilla ChatGPT,175 B),这进一步验证了在解决推理任务时使用逻辑教学LLM的重要性。
4.4.3案例研究
在图7中,我们对Llama 2 - 13 B在预训练前后对相同输入的回答进行了案例研究。从图7中我们可以看到,LlaMA 2 - 13 B-PT在LLM-LR上进行预训练后可以输出正确的答案,这验证了我们的预训练方法的有效性。

这篇关于学习教授LLM逻辑推理11.19的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









