本文主要是介绍从零开始搭建Unity机器学习环境—Chapter1:常用训练参数解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Unity官方机器学习官方库(ML-Agents)组件为游戏开发者及研究人员提供了一整套易集成、所见即所得的机器学习框架。在Unity环境中,Agent智能体的学习、训练参数主要通过yaml文件进行配置,如图1所示。本文将对ML-Agents所涉及到的机器学习配置参数进行简单介绍,水平有限,如有错误敬请见谅。Github原文链接详见文章末尾。
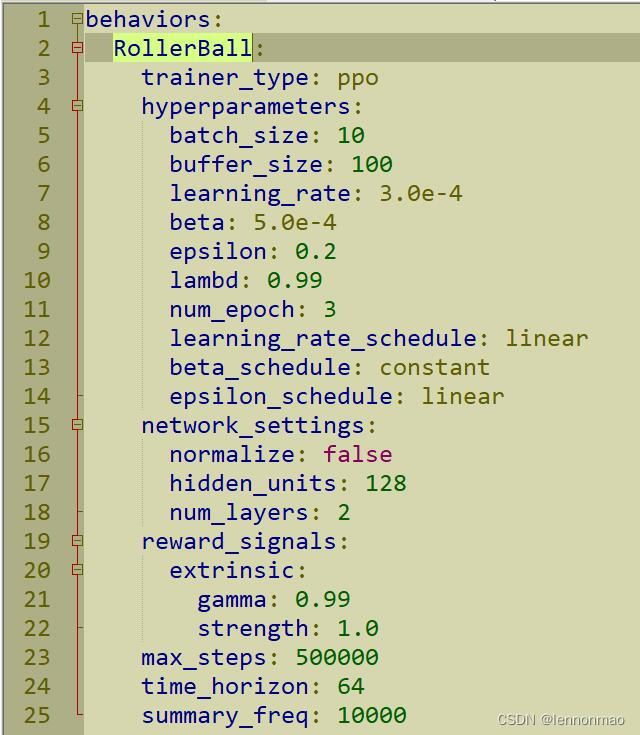
常用训练配置参数(Common Trainer Configurations)
1.1 trainer_type:训练器类型,默认为ppo,另有sac及poca可选。
1.2 summary_freq:默认为50000,定义每次生成、显示训练统计数据之间需要收集的训练结果数量。该参数也决定了 Tensorboard 中图表的粒度(注:ML-Agents训练进度可通过cmd窗口查看,后续将详细介绍)。
1.3 time_horizon:介于32 ~ 2048,默认为64。将Agent添加到经验缓冲区之前,所必须经历的训练步的数量。当在场景(用户自定义的训练场景,episode)结束之前达到此限制时,将使用价值估计来预测智能体当前状态的总体预期奖励。因此,该参数在偏差较小但方差较高的估计(长期)和偏差较大但变化较小的估计(短期)之间进行权衡。 在场景中经常有奖励的情况下,或者场景非常大的情况下,建议选较小的数字。通常, 这个数字应该足够大,以捕获Agent动作序列中的所有重要行为。
1.4 max_steps:介于5E5 ~ 1E7,默认5E5。在场景中结束训练之前,必须在场景中(如果并行使用多个,则为在所有环境中)进行的仿真步数。
1.5 keep_checkpoints:默认为5,要保留的模型检查点的最大数量。 在checkpoint_interval选项指定的步数之后保存检查点。 一旦达到最大检查点数,保存新检查点时将删除最旧的检查点。
1.6 checkpoint_interval:Trainer在每个检查点之间收集的经验数量。在删除旧的检查点之前,最多保存keep_checkpoints个检查点(注:1.5中已经提到,这两部分顺序换一下更合理)。每个检查点都将.onnx 文件保存在 results/ 文件夹中(注:如果顺利进行训练,则路径为ProjectName/results/...)。
1.7 init_path:从既有的模型初始化Trainer,默认为空(不可用)。之前的运行模型应该使用与当前运行的模型使用相同的Trainer配置,并使用相同版本的 ML-Agents 保存。ML-Agents不同版本之间的差异往往会导致Editor报错,应谨慎使用。
1.8 threaded:在更新模型时允许环境步进,默认为false。 这可能会导致训练加速,尤其是在使用 sac时。为获得最佳性能,请在使用自玩游戏时将设置保留为 false。
1.9 hyperparameters -> learning_rate:梯度下降的初始学习率,介于1E-5 ~ 1E-3,默认为3E-4。 对应于每个梯度下降更新步骤的强度。 如果训练不稳定并且奖励不会持续增加,则通常应该减少此值。
1.10 hyperparameters -> batch_size:梯度下降每次迭代的经验数。应确保该值总是比 buffer_size小几倍。 在使用连续动作的情况下,该值应该很大(≈1000s),若只使用离散动作,该值应该更小(≈10s)。常用取值范围:Continuous - PPO,512 ~ 5120;Continuous - SAC,128 ~ 1024;Discrete, PPO & SAC,32 ~ 512。
1.11.1 hyperparameters -> buffer_size (PPO):在更新策略模型之前要收集的经验数量,介于2048 ~ 409600,默认值10240。对应于在我们对模型进行任何学习或更新之前至少应该收集的经验数量。 这应该比 batch_size 大几倍(1.10中已经提到)。较大的 buffer_size对应于更稳定的训练更新。
1.11.2 hyperparameters -> buffer_size(SAC):经验缓冲区的最大大小,介于50000 ~ 1000000,默认值为50000。以便 SAC 可以从旧经验和新经验中学习。
1.12.1 hyperparameters -> learning_rate_schedule(PPO):确定学习率如何随时间变化,默认值为linear。对于 PPO而言,将学习率衰减至到 max_steps能够使学习更稳定地收敛。 但是,对于某些特殊情况(如训练时间未知),可以禁用此功能。
1.12.2 hyperparameters -> learning_rate_schedule(SAC):确定学习率如何随时间变化,默认值为constant。对于 SAC而言,建议保持学习率不变,以便Agent可以继续学习,直到其 Q 函数自然收敛。注:linear表示learning_rate在学习过程中线性衰减,在 max_steps 处达到 0,而若选择 constant ,在整个训练过程中learning_rate恒定。
1.13 network_settings -> hidden_units:神经网络隐藏层中的单元数,介于32 ~ 512,默认值为128。对应于神经网络的每个全连接层中有多少个单元。 对于正确操作是观察输入的直接组合的简单问题,应设置较小数值。 对于动作是观察变量之间非常复杂的相互作用的问题,应设置较大数值。
1.14 network_settings -> num_layers:神经网络中隐藏层的数量,介于 1 ~ 3 ,默认值为2。对应于观察输入后或视觉观察的CNN 编码后存在多少隐藏层。对于简单的问题,较少的层数可能训练得更快、更有效。对于更复杂的控制问题,则需要更多的层。
1.15 network_settings -> normalize:是否对向量观察输入应用归一化,默认值为false。 这种归一化基于矢量观察的运行平均值和方差。 归一化在具有复杂连续控制问题的情况下可能很有帮助,但对于更简单的离散控制问题可能适得其反。
1.16 network_settings -> vis_encode_type:用于编码视觉观察的编码器类型,默认值为simple。simple使用由两个卷积层组成的简单编码器,nature_cnn使用由Mnih等人提出的CNN实现,由三个卷积层组成,resnet 使用由三个堆叠层组成的IMPALA Resnet,每个层有两个残差块,形成比其他两个更大的网络。match3 是一个较小的CNN(Gudmundsoon 等人提出),可以捕获更精细的空间关系,并针对棋盘游戏进行了优化。fully_connected 使用单个完全连接的密集层作为编码器,没有任何卷积层。由于卷积核的大小,每种编码器类型可以处理的最小观察大小限制(simple:20x20,nature_cnn:36x36,resnet:15 x 15,match3:5x5)。 fully_connected 没有卷积层,因此没有大小限制,但由于它的表示能力较小,因此应该为非常小的输入保留。应注意的是,使用具有非常大的视觉输入的match3 CNN可能会导致大量的观察编码,从而可能会减慢训练速度或导致内存问题。
1.17 network_settings -> conditioning_type:使用目标观察的策略的条件类型,默认值为hyper。none将目标观察视为常规观察,hyper(默认值)使用带有目标观察的超网络作为输入来生成策略的一些权重。应注意的是,当选择 hyper 时,网络的参数数量会大大增加,因此建议同时减少hidden_units的数量。
Github参考:ml-agents/Training-Configuration-File.md at release_19_docs · Unity-Technologies/ml-agents · GitHub
这篇关于从零开始搭建Unity机器学习环境—Chapter1:常用训练参数解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






