本文主要是介绍rasa train nlu详解:1.2-_train_graph()函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文使用《使用ResponseSelector实现校园招聘FAQ机器人》中的例子,主要详解介绍_train_graph()函数中变量的具体值。
一.rasa/model_training.py/_train_graph()函数
_train_graph()函数实现,如下所示:
def _train_graph(file_importer: TrainingDataImporter,training_type: TrainingType,output_path: Text,fixed_model_name: Text,model_to_finetune: Optional[Union[Text, Path]] = None,force_full_training: bool = False,dry_run: bool = False,**kwargs: Any,
) -> TrainingResult:if model_to_finetune: # 如果有模型微调model_to_finetune = rasa.model.get_model_for_finetuning(model_to_finetune) # 获取模型微调if not model_to_finetune: # 如果没有模型微调rasa.shared.utils.cli.print_error_and_exit( # 打印错误并退出f"No model for finetuning found. Please make sure to either " # 没有找到微调模型。请确保f"specify a path to a previous model or to have a finetunable " # 要么指定一个以前模型的路径,要么有一个可微调的f"model within the directory '{output_path}'." # 在目录'{output_path}'中的模型。)rasa.shared.utils.common.mark_as_experimental_feature( # 标记为实验性功能"Incremental Training feature" # 增量训练功能)is_finetuning = model_to_finetune is not None # 如果有模型微调config = file_importer.get_config() # 获取配置recipe = Recipe.recipe_for_name(config.get("recipe")) # 获取配方config, _missing_keys, _configured_keys = recipe.auto_configure( # 自动配置file_importer.get_config_file_for_auto_config(), # 获取自动配置的配置文件config, # 配置training_type, # 训练类型)model_configuration = recipe.graph_config_for_recipe( # 配方的graph配置config, # 配置kwargs, # 关键字参数training_type=training_type, # 训练类型is_finetuning=is_finetuning, # 是否微调)rasa.engine.validation.validate(model_configuration) # 验证tempdir_name = rasa.utils.common.get_temp_dir_name() # 获取临时目录名称# Use `TempDirectoryPath` instead of `tempfile.TemporaryDirectory` as this leads to errors on Windows when the context manager tries to delete an already deleted temporary directory (e.g. https://bugs.python.org/issue29982)# 翻译:使用TempDirectoryPath而不是tempfile.TemporaryDirectory,因为当上下文管理器尝试删除已删除的临时目录时,这会导致Windows上的错误(例如https://bugs.python.org/issue29982)with rasa.utils.common.TempDirectoryPath(tempdir_name) as temp_model_dir: # 临时模型目录model_storage = _create_model_storage( # 创建模型存储is_finetuning, model_to_finetune, Path(temp_model_dir) # 是否微调,模型微调,临时模型目录)cache = LocalTrainingCache() # 本地训练缓存trainer = GraphTrainer(model_storage, cache, DaskGraphRunner) # Graph训练器if dry_run: # dry运行fingerprint_status = trainer.fingerprint( # fingerprint状态model_configuration.train_schema, file_importer # 模型配置的训练模式,文件导入器)return _dry_run_result(fingerprint_status, force_full_training) # 返回dry运行结果model_name = _determine_model_name(fixed_model_name, training_type) # 确定模型名称full_model_path = Path(output_path, model_name) # 完整的模型路径with telemetry.track_model_training( # 跟踪模型训练file_importer, model_type=training_type.model_type # 文件导入器,模型类型):trainer.train( # 训练model_configuration, # 模型配置file_importer, # 文件导入器full_model_path, # 完整的模型路径force_retraining=force_full_training, # 强制重新训练is_finetuning=is_finetuning, # 是否微调)rasa.shared.utils.cli.print_success( # 打印成功f"Your Rasa model is trained and saved at '{full_model_path}'." # Rasa模型已经训练并保存在'{full_model_path}'。)return TrainingResult(str(full_model_path), 0) # 训练结果
1.传递来的形参数据
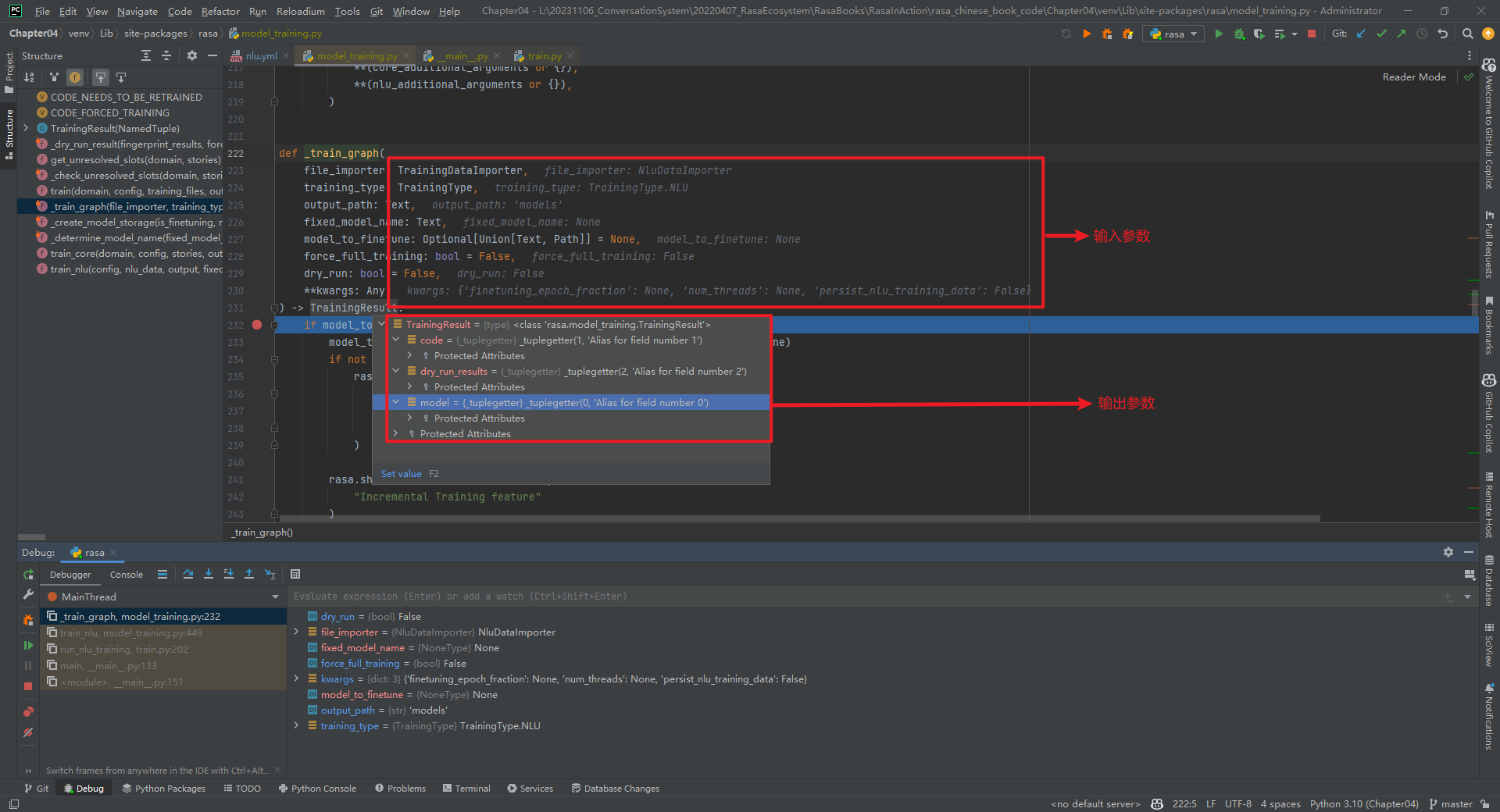
2._train_graph()函数组成
该函数主要由3个方法组成,如下所示:
- model_configuration = recipe.graph_config_for_recipe(*)
- trainer = GraphTrainer(model_storage, cache, DaskGraphRunner)
- trainer.train(model_configuration, file_importer, full_model_path, force_retraining, is_finetuning)
二._train_graph()函数中的方法
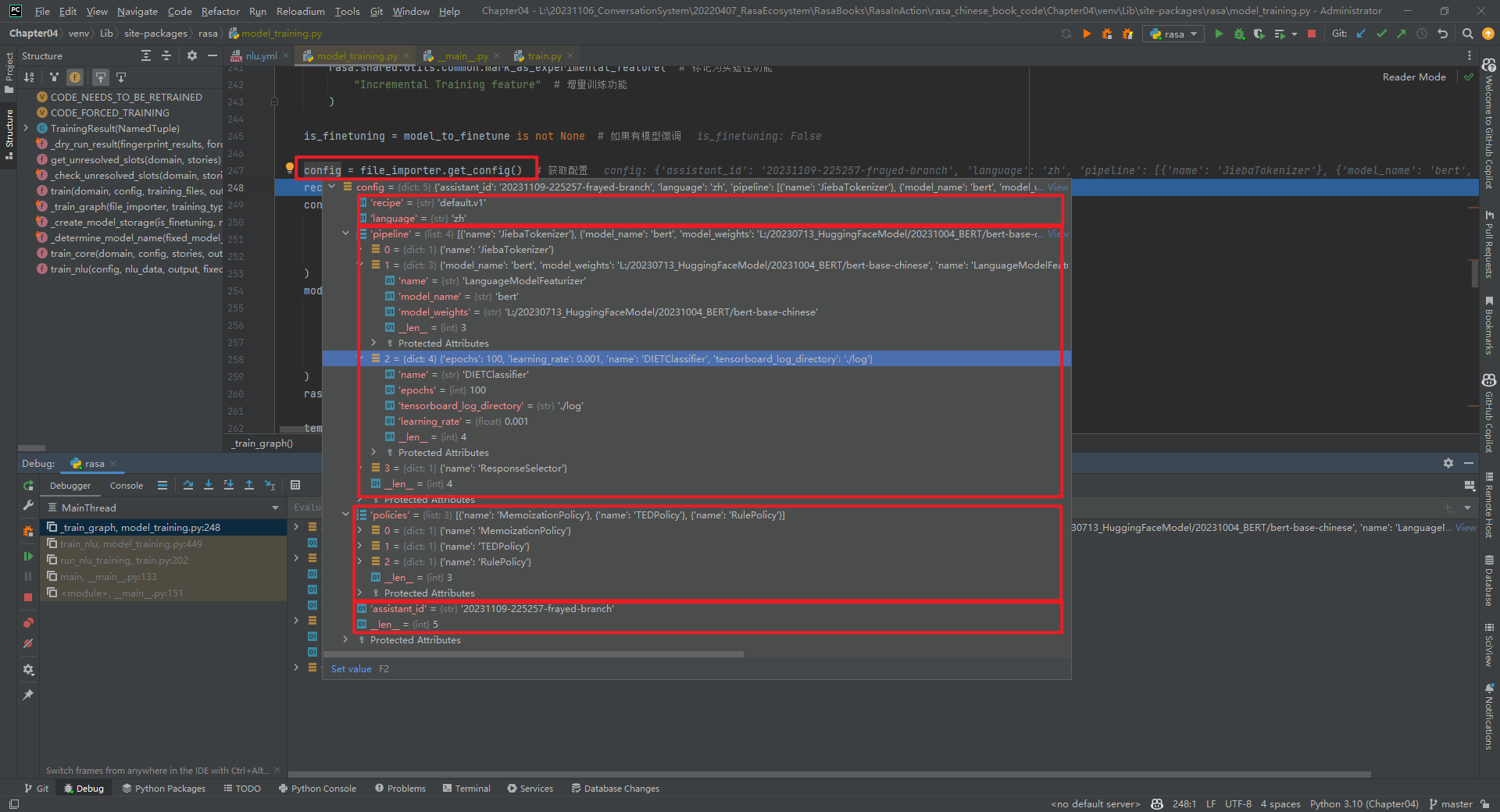
1.file_importer.get_config()
将config.yml文件转化为dict类型,如下所示:
2.Recipe.recipe_for_name(config.get(“recipe”))
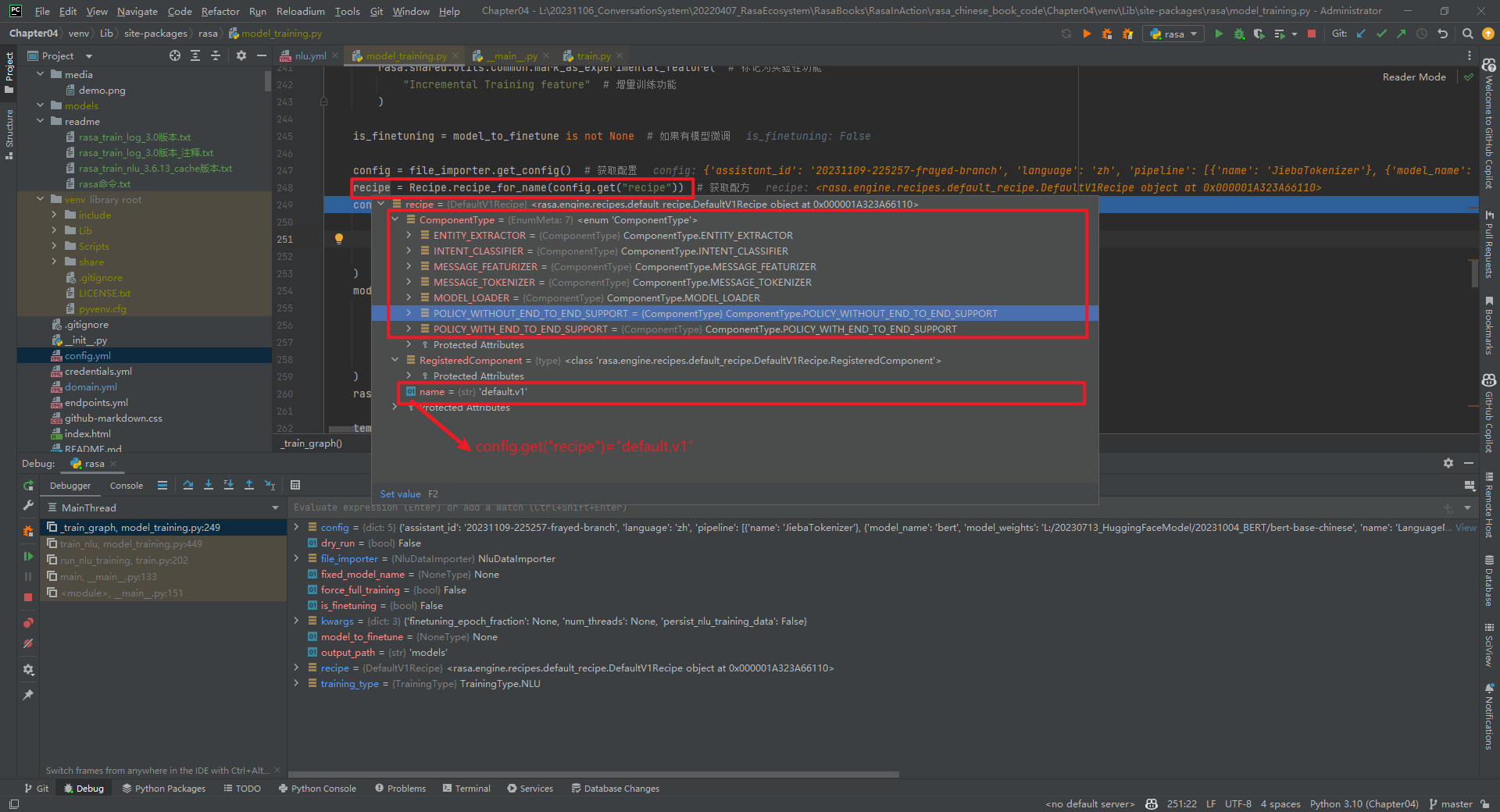
(1)ENTITY_EXTRACTOR = ComponentType.ENTITY_EXTRACTOR
实体抽取器。
(2)INTENT_CLASSIFIER = ComponentType.INTENT_CLASSIFIER
意图分类器。
(3)MESSAGE_FEATURIZER = ComponentType.MESSAGE_FEATURIZER
消息特征化。
(4)MESSAGE_TOKENIZER = ComponentType.MESSAGE_TOKENIZER
消息Tokenizer。
(5)MODEL_LOADER = ComponentType.MODEL_LOADER
模型加载器。
(6)POLICY_WITHOUT_END_TO_END_SUPPORT = ComponentType.POLICY_WITHOUT_END_TO_END_SUPPORT
非端到端策略支持。
(7)POLICY_WITH_END_TO_END_SUPPORT = ComponentType.POLICY_WITH_END_TO_END_SUPPORT
端到端策略支持。
3.model_configuration = recipe.graph_config_for_recipe(*)
model_configuration.train_schema和model_configuration.predict_schema的数据类型都是GraphSchema类对象,分别表示在训练和预测时所需要的SchemaNode,以及SchemaNode在GraphSchema中的依赖关系。
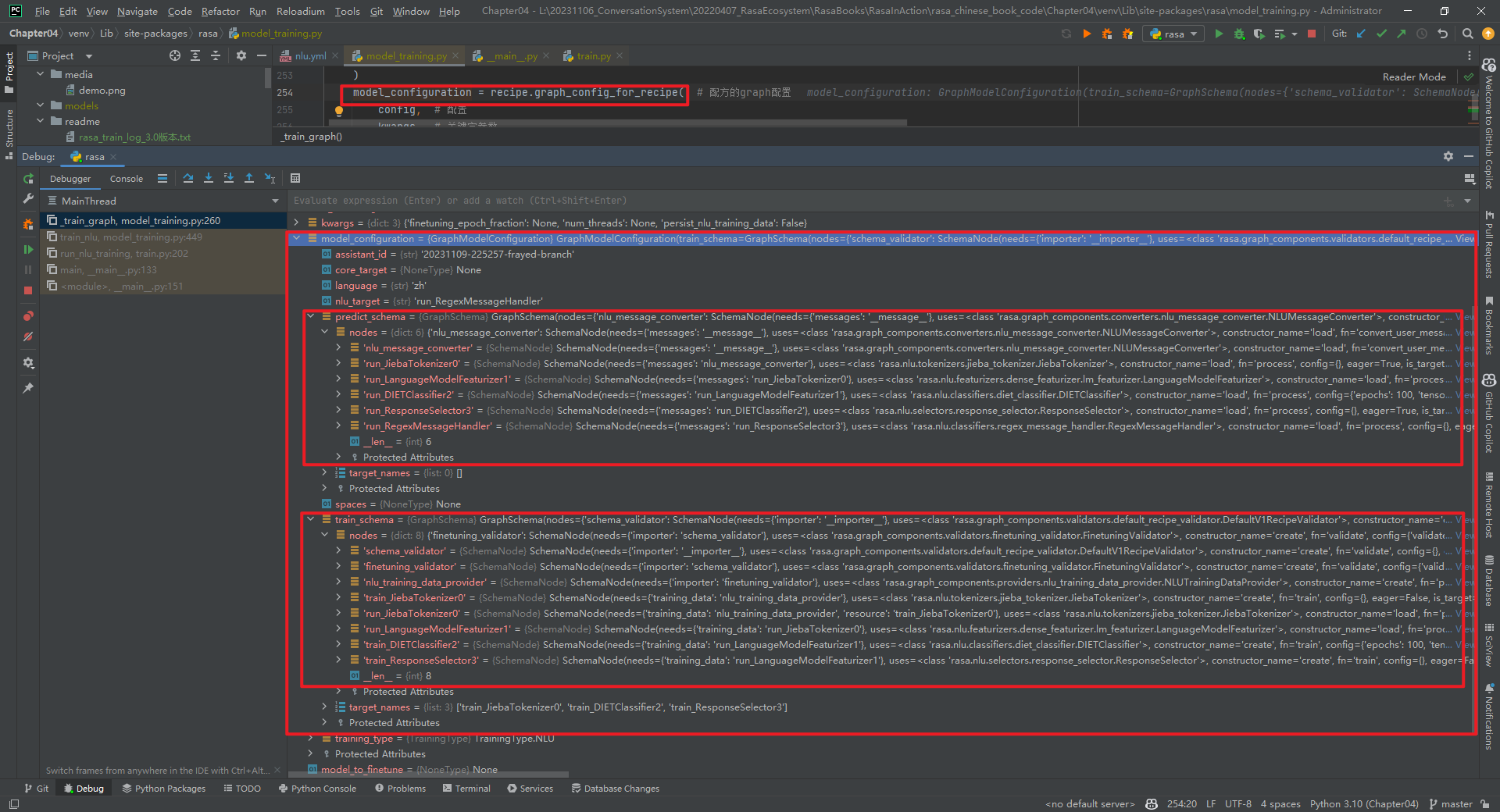
(1)model_configuration.train_schema
- schema_validator:rasa.graph_components.validators.default_recipe_validator.DefaultV1RecipeValidator类中的validate方法
- finetuning_validator:rasa.graph_components.validators.finetuning_validator.FinetuningValidator类中的validate方法
- nlu_training_data_provider:rasa.graph_components.providers.nlu_training_data_provider.NLUTrainingDataProvider类中的provide方法
- train_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的train方法
- run_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的process_training_data方法
- run_LanguageModelFeaturizer1:rasa.nlu.featurizers.dense_featurizer.lm_featurizer.LanguageModelFeaturizer类中的process_training_data方法
- train_DIETClassifier2:rasa.nlu.classifiers.diet_classifier.DIETClassifier类中的train方法
- train_ResponseSelector3:rasa.nlu.selectors.response_selector.ResponseSelector类中的train方法
说明:ResponseSelector类继承自DIETClassifier类。
(2)model_configuration.predict_schema
- nlu_message_converter:rasa.graph_components.converters.nlu_message_converter.NLUMessageConverter类中的convert_user_message方法
- run_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的process方法
- run_LanguageModelFeaturizer1:rasa.nlu.featurizers.dense_featurizer.lm_featurizer.LanguageModelFeaturizer类中的process方法
- run_DIETClassifier2:rasa.nlu.classifiers.diet_classifier.DIETClassifier类中的process方法
- run_ResponseSelector3:rasa.nlu.selectors.response_selector.ResponseSelector类中的process方法
- run_RegexMessageHandler:rasa.nlu.classifiers.regex_message_handler.RegexMessageHandler类中的process方法
4.tempdir_name
‘C:\Users\ADMINI~1\AppData\Local\Temp\tmpg0v179ea’
5.trainer = GraphTrainer(*)和trainer.train(*)
这里执行的代码是rasa/engine/training/graph_trainer.py中GraphTrainer类的train()方法,实现功能为训练和打包模型并返回预测graph运行程序。
6.Rasa中GraphComponent的子类

参考文献:
[1]https://github.com/RasaHQ/rasa
[2]rasa 3.2.10 NLU模块的训练:https://zhuanlan.zhihu.com/p/574935615
[3]rasa.engine.graph:https://rasa.com/docs/rasa/next/reference/rasa/engine/graph/
这篇关于rasa train nlu详解:1.2-_train_graph()函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





