本文主要是介绍以图搜视频的两篇短论文(Stanford),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Standford I2V数据集论文(见上篇博客)作者的两篇短文章
Real-time Query-by-Image Video Search System
EFFICIENT VIDEO SEARCH USING IMAGE QUERIES
看论文小记,写下备忘
论文引用(GB/T 7714)
Araujo A, Chen D, Vajda P, et al. Real-time query-by-image video search system[C]//Proceedings of the 22nd ACM international conference on Multimedia. ACM, 2014: 723-724.
Araujo A, Makar M, Chandrasekhar V, et al. Efficient video search using image queries[C]//Image Processing (ICIP), 2014 IEEE International Conference on. IEEE, 2014: 3082-3086.
Real-time Query-by-Image Video Search System
一个实时的以图搜视频的系统,看起来比较简单。
系统概览
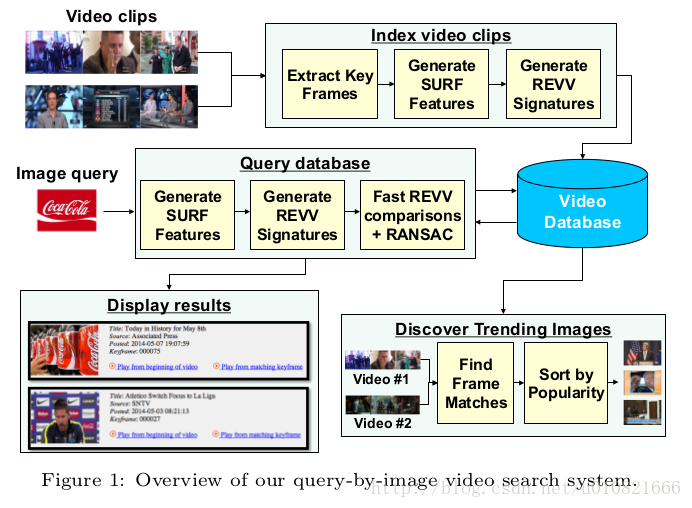
Index video clips 为视频片段建立索引
对于每一个视频的clip,一秒提取一帧关键帧,每个关键帧提取SURF特征然后聚合成一个REVV(Residual Enhanced Visual Vector)全局特征,使用REVV特征可以建立低内存开销的索引和进行快速检索。检索系统的内存限制可以容纳一百万个关键帧,大概可以为10天的新闻建立索引。
系统的速度:加载了30分钟新闻节目之后,系统平均需要花费15分钟来将视频分成独立的故事(每一个故事生成一个视频clip),也就是场景。然后需要花费5分钟的时间提取关键帧和生成REVV signatures。
内存开销:为一百万个关键帧建立索引需要500MB内存。
Query database
参考REVV论文中的比较特征的方法,然后生成一个最相似关键帧的列表。然后进行几何校验,使用RANSAC的方法,找到匹配对之间的仿射变换。
Discover trending images
将REVV和SURF特征匹配方法结合使用,跟上一步使用的方法差不多,平均每个视频要使用81秒。
EFFICIENT VIDEO SEARCH USING IMAGE QUERIES
提出了一种在同样的视频搜索质量情况下内存开销更小的方法。使用了CNN2h的数据集,有两个小时的CNN视频,实验前标注了139个搜索的结果—-平板播放视频,用手机从不同角度照下来的照片(会有实质性的几何和photometric光度测定?的变形),也有来源于网络的照片。视频一秒取10帧,共72000帧。
文章主要是讲减小内存开销,在检测每帧特征的时候提取关键点以及做追踪,暂时用不到,先不看了。
这篇关于以图搜视频的两篇短论文(Stanford)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!