本文主要是介绍【数据结构】树与二叉树(十):二叉树的先序遍历(非递归算法NPO),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 5.2.1 二叉树
- 5.2.2 二叉树顺序存储
- 5.2.3 二叉树链接存储
- 5.2.4 二叉树的遍历
- 1-3 先序、中序、后序遍历递归实现及相关练习
- 后序遍历递归实现
- 4. 中序遍历非递归
- 5. 后序遍历非递归
- 6. 先序遍历非递归
- a. 算法NPO
- b. 算法解读
- c. 复杂度分析
- d.代码实现
- 5. 代码整合
5.2.1 二叉树
二叉树是一种常见的树状数据结构,它由结点的有限集合组成。一个二叉树要么是空集,被称为空二叉树,要么由一个根结点和两棵不相交的子树组成,分别称为左子树和右子树。每个结点最多有两个子结点,分别称为左子结点和右子结点。
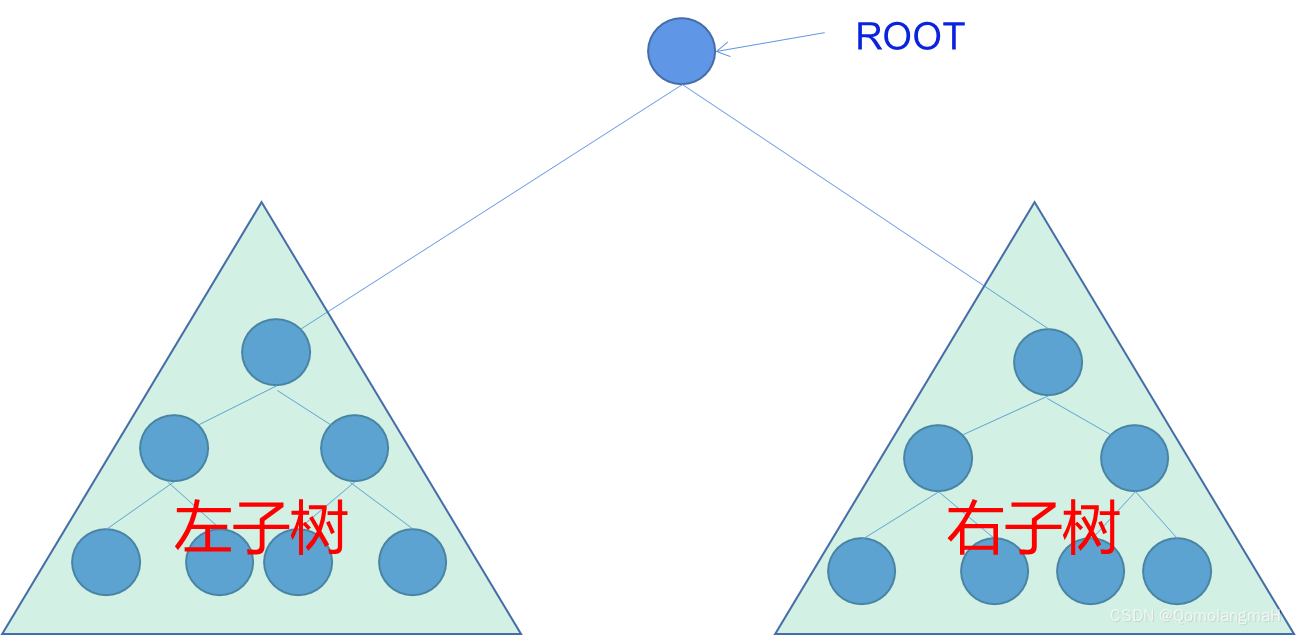
二叉树性质
引理5.1:二叉树中层数为i的结点至多有 2 i 2^i 2i个,其中 i ≥ 0 i \geq 0 i≥0。
引理5.2:高度为k的二叉树中至多有 2 k + 1 − 1 2^{k+1}-1 2k+1−1个结点,其中 k ≥ 0 k \geq 0 k≥0。
引理5.3:设T是由n个结点构成的二叉树,其中叶结点个数为 n 0 n_0 n0,度数为2的结点个数为 n 2 n_2 n2,则有 n 0 = n 2 + 1 n_0 = n_2 + 1 n0=n2+1。
- 详细证明过程见前文:【数据结构】树与二叉树(三):二叉树的定义、特点、性质及相关证明
满二叉树、完全二叉树定义、特点及相关证明
- 详细证明过程见前文:【数据结构】树与二叉树(四):满二叉树、完全二叉树及其性质
5.2.2 二叉树顺序存储
二叉树的顺序存储是指将二叉树中所有结点按层次顺序存放在一块地址连续的存储空间中,详见:
【数据结构】树与二叉树(五):二叉树的顺序存储(初始化,插入结点,获取父节点、左右子节点等)
5.2.3 二叉树链接存储
二叉树的链接存储系指二叉树诸结点被随机存放在内存空间中,结点之间的关系用指针说明。在链式存储中,每个二叉树结点都包含三个域:数据域(Data)、左指针域(Left)和右指针域(Right),用于存储结点的信息和指向子结点的指针,详见:
【数据结构】树与二叉树(六):二叉树的链式存储
5.2.4 二叉树的遍历
- 遍历(Traversal)是对二叉树中所有节点按照一定顺序进行访问的过程。
- 通过遍历,可以访问树中的每个节点,并按照特定的顺序对它们进行处理。
- 对二叉树的一次完整遍历,可给出树中结点的一种线性排序。
- 在二叉树中,常用的遍历方式有三种:先序遍历、中序遍历和后序遍历。
- 这三种遍历方式都可以递归地进行,它们的区别在于节点的访问顺序。
- 在实现遍历算法时,需要考虑递归终止条件和递归调用的顺序。
- 还可以使用迭代的方式来实现遍历算法,使用栈或队列等数据结构来辅助实现。
- 遍历是二叉树中基础而重要的操作,它为其他许多操作提供了基础,如搜索、插入、删除等。
1-3 先序、中序、后序遍历递归实现及相关练习
【数据结构】树与二叉树(七):二叉树的遍历(先序、中序、后序及其C语言实现)
后序遍历递归实现
void postOrderTraversal(struct Node* root) {if (root == NULL) {return;}// 递归遍历左子树postOrderTraversal(root->left);// 递归遍历右子树postOrderTraversal(root->right);// 访问根节点printf("%c ", root->data);
}4. 中序遍历非递归
【数据结构】树与二叉树(八):二叉树的中序遍历(非递归算法NIO)
5. 后序遍历非递归
【数据结构】树与二叉树(九):二叉树的后序遍历(非递归算法NPO)
6. 先序遍历非递归
a. 算法NPO

说明:该ADL语言算法流程为本人所写,不具备权威性,如有错误望忽视,请跳转至下文具体C语言实现部分。
b. 算法解读
算法NPO(t)利用了一个辅助堆栈S来遍历二叉树T的所有节点。
- 如果根节点t为空,则直接返回。
- 创建一个空堆栈S,并将根节点t和初始标记0入栈(S <= (t, 0))。
- 进入循环,只要堆栈S非空,执行以下步骤:
a. 从堆栈S中弹出栈顶元素,将其赋值给(p, i)。
b. 如果标记i为0,则表示节点p还未处理,打印节点p的值,并将左子节点入栈(S <= (Left§, 0)),然后将标记置为1(S <= (p, 1))。
c. 如果标记i为1,则表示节点p的左子树已处理完毕,将右子节点入栈(S <= (Right§, 0)),然后将标记置为2(S <= (p, 2))。
d. 如果标记i为2,则表示节点p的左右子树都已处理完毕,将节点p从堆栈S中弹出(S.pop())。 - 跳转到步骤3,继续循环,直到堆栈S为空。
c. 复杂度分析
设二叉树有n个结点。算法NPO中,每个结点的状态都是从0→1→2,每个状态都要经历1次入栈和1次出栈,即入栈和出栈各执行3n次,另外,每个结点都进行1次访问,即访问还要执行n次,因此,算法NPO的时间复杂度为O(n).
d.代码实现
void nonRecursiveInOrder(struct Node* root) {struct Node* stack[100]; // 辅助堆栈,用于模拟递归调用栈int top = -1; // 栈顶指针struct Node* current = root;while (current != NULL || top != -1) {// 将当前结点的左子结点入栈while (current != NULL) {stack[++top] = current;current = current->left;}// 弹出栈顶结点,并访问current = stack[top--];printf("%c ", current->data);// 处理右子结点current = current->right;}
}5. 代码整合
#include <stdio.h>
#include <stdlib.h>// 二叉树结点的定义
struct Node {char data;struct Node* left;struct Node* right;
};// 创建新结点
struct Node* createNode(char data) {struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));if (newNode == NULL) {printf("Memory allocation failed!\n");exit(1);}newNode->data = data;newNode->left = NULL;newNode->right = NULL;return newNode;
}// 先序遍历
void PreOrderTraversal(struct Node* root) {if (root == NULL) {return;}// 访问根节点printf("%c ", root->data);// 递归遍历左子树PreOrderTraversal(root->left);// 递归遍历右子树PreOrderTraversal(root->right);}// 非递归先序遍历
void nonRecursivePreOrder(struct Node* root) {if (root == NULL) {return;}struct Node* stack[100]; // 辅助堆栈,用于模拟递归调用栈int top = -1; // 栈顶指针stack[++top] = root;while (top != -1) {struct Node* current = stack[top--];printf("%c ", current->data);if (current->right != NULL) {stack[++top] = current->right;}if (current->left != NULL) {stack[++top] = current->left;}}
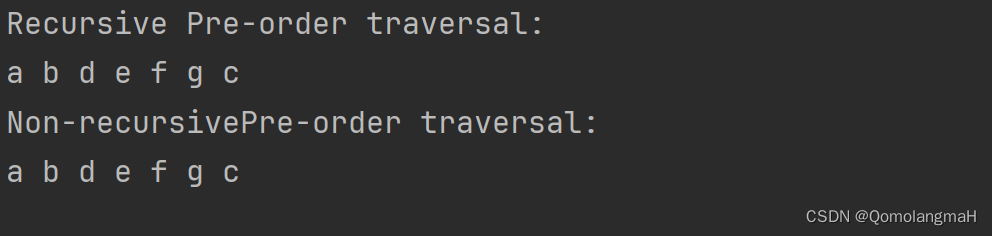
}int main() {// 创建一棵二叉树struct Node* root = createNode('a');root->left = createNode('b');root->right = createNode('c');root->left->left = createNode('d');root->left->right = createNode('e');root->left->right->left = createNode('f');root->left->right->right = createNode('g');// 递归先序序遍历二叉树printf("Recursive Pre-order traversal: \n");PreOrderTraversal(root);printf("\n");// 非递归先序遍历二叉树printf("Non-recursivePre-order traversal: \n");nonRecursivePreOrder(root);printf("\n");return 0;
}
这篇关于【数据结构】树与二叉树(十):二叉树的先序遍历(非递归算法NPO)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








