本文主要是介绍SQL必知会(二)-SQL查询篇(7)-使用函数处理数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第8课、使用函数处理数据
表8-1 DBMS 函数的差异
| 函数 | 语法 |
|---|---|
| 提取字符串的组成 | DB2、Oracle、PostgreSQL 和 SQLite 使用 SUBSTR();MariaDB、Mysql 和 SQL Server 使用 SUBSTRING() |
| 数据类型转换 | Oracle 使用多个函数,每种类型的转换有一个函数;DB2 和 PostgreSQL 使用CAST(); MariaDB、MySQL 和 SQL Server 使用 CONVERT() |
| 取当前日期 | DB2 和 PostgreSQL 使用 CURRENT_DATE;MariaDB 和 MySQL 使用 CURDATE();Oracle 使用 SYSDATE;SQL Server 使用 GETDATE();SQLite 使用 DATE() |
缺点: 因为有些数据库使用 SQL 函数有差异,所以难以对 SQL 进行移植。
| 1)文本处理函数 |
需求:把 vend_name 字段的值转换为大写,并且新值命名为 vend_name_upcase。
SELECT vend_name, UPPER(VEND_NAME) AS vend_name_upcase
FROM Vendors
ORDER BY vend_name;
输出结果:

表8-2 常用的文本处理函数
| 函数 | 说明 |
|---|---|
| LEFT(或使用字符串函数) | 返回字符串左边的字符 |
| LENGTH()(也使用 DATLENGTH() 或 LEN()) | 返回字符串的长度 |
| LOWER() | 将字符串转换为小写 |
| LTRIM() | 去掉字符串左边的空格 |
| RIGHT() (或使用子字符串函数) | 返回字符串右边的字符 |
| RTRIM() | 去掉字符串右边的空格 |
| SUBSTR() 或 SUBSTRING() | 提取字符串的组成部分 |
| SOUNDEX() | 返回字符串的 SOUNDEX 值 |
| UPPER() | 将字符串转换为大写 |
| 1.2)文本处理函数: SOUNDEX() 函数 |
需求:Custmers 表中有一个顾客 Kids Place,其联系名为 Michelle Green。但是如果这是错误的输入,此联系名实际上应该是 Michael Green。
-- 不使用 SOUNDEX 函数:
SELECT cust_name, cust_contact
FROM Customers
Where cust_contact = 'Michael Green';
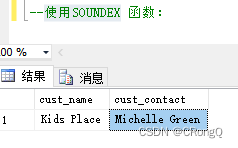
-- 由于数据库中没有 Michael Green,所以结果查询不到这个 Michael Green。-- 使用 SOUNDEX 函数:
SELECT cust_name, cust_contact
FROM Customers
WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green');
-- 虽然数据库中没有 Michael,但是输出跟其发音相似的文本串 Michelle Green
输出结果:
| 2)日期和时间处理函数 |
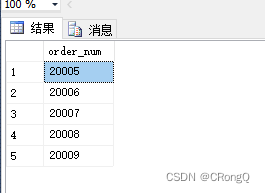
需求:检索 2020 年的所有订单。
SELECT order_num
FROM Orders
WHERE DATEPART(yy, order_date) = 2020;-- 使用 PostgreSQL:
SELECT order_num
FROM Orders
WHERE DATE_PART('year', order_date) = 2020;-- 使用 Oracle:
SELECT order_num
FROM Orders
WHERE EXTRACT(year FROM order_date) = 2020;-- 其他数据库的区别用法,以后需要时就了解一下,暂时不做这个笔记了。
输出结果:
数值处理函数
表8-3 常用数值处理函数
| 函数 | 说明 |
|---|---|
| ABS() | 返回一个数的绝对值 |
| COS() | 返回一个角度的余弦 |
| EXP() | 返回一个数的指数值 |
| PI() | 返回圆周率 Π 的值 |
| SIN() | 返回一个角度的正弦 |
| SQRT() | 返回一个数的平方根 |
| TAN() | 返回一个角度的正切 |
这篇关于SQL必知会(二)-SQL查询篇(7)-使用函数处理数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





