本文主要是介绍[Hue|Hive]return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题
Hue(4.5)查询Hive(1.2.2)的Phoenix外部表运行一段时间之后会报错
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
或者报错
Error while compiling statement: FAILED: RuntimeException org.apache.hadoop.hive.ql.metadata.HiveException: Failed with exception org.apache.phoenix.exception.PhoenixIOException: Can't get the locationsorg.apache.hadoop.hive.serde2.SerDeException:
初步分析
以上第一种报错并没有显示真正的错误原因,可以从Hue的页面中看到真正的错误
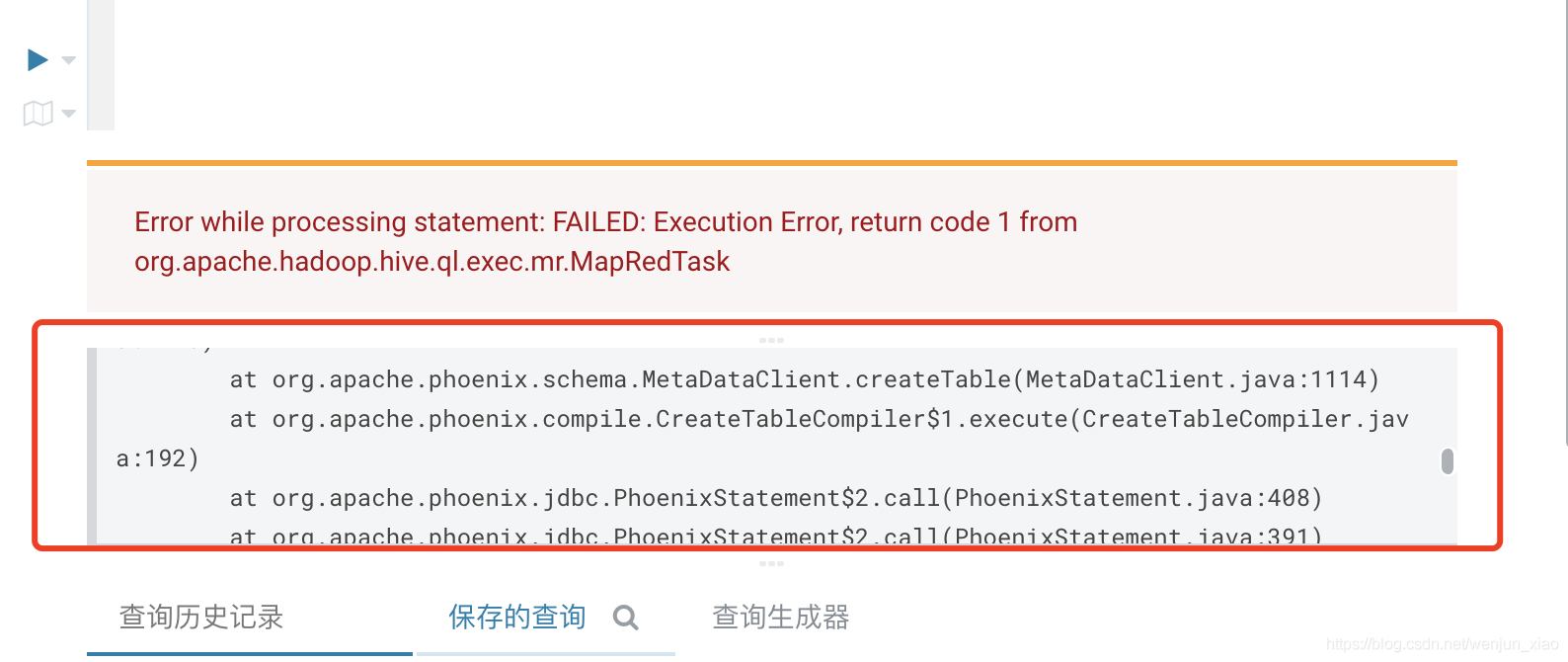
具体的错误信息如下:
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
DEBUG : Configuring job job_1589783756298_0002 with /tmp/hadoop-yarn/staging/admin/.staging/job_1589783756298_0002 as the submit dir
DEBUG : adding the following namenodes' delegation tokens:[hdfs://mycluster]
DEBUG : Creating splits at hdfs://mycluster/tmp/hadoop-yarn/staging/admin/.staging/job_1589783756298_0002
INFO : Cleaning up the staging area /tmp/hadoop-yarn/staging/admin/.staging/job_1589783756298_0002
ERROR : Job Submission failed with exception 'java.lang.RuntimeException(org.apache.phoenix.exception.PhoenixIOException: Can't get the locations)'
java.lang.RuntimeException: org.apache.phoenix.exception.PhoenixIOException: Can't get the locationsat org.apache.phoenix.hive.mapreduce.PhoenixInputFormat.getQueryPlan(PhoenixInputFormat.java:267)at org.apache.phoenix.hive.mapreduce.PhoenixInputFormat.getSplits(PhoenixInputFormat.java:131)at org.apache.hadoop.hive.ql.io.HiveInputFormat.addSplitsForGroup(HiveInputFormat.java:306)at org.apache.hadoop.hive.ql.io.HiveInputFormat.getSplits(HiveInputFormat.java:408)at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getCombineSplits(CombineHiveInputFormat.java:361)at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:571)at org.apache.hadoop.mapreduce.JobSubmitter.writeOldSplits(JobSubmitter.java:329)at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:321)at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:197)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1297)at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1294)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)at org.apache.hadoop.mapreduce.Job.submit(Job.java:1294)at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:432)at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:137)at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:160)at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:88)at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1676)at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1435)at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1218)at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1082)at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1077)at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:154)at org.apache.hive.service.cli.operation.SQLOperation.access$100(SQLOperation.java:71)at org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:206)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)at org.apache.hive.service.cli.operation.SQLOperation$1.run(SQLOperation.java:218)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.phoenix.exception.PhoenixIOException: Can't get the locationsat org.apache.phoenix.util.ServerUtil.parseServerException(ServerUtil.java:144)at org.apache.phoenix.query.ConnectionQueryServicesImpl.ensureTableCreated(ConnectionQueryServicesImpl.java:1197)at org.apache.phoenix.query.ConnectionQueryServicesImpl.createTable(ConnectionQueryServicesImpl.java:1491)at org.apache.phoenix.schema.MetaDataClient.createTableInternal(MetaDataClient.java:2725)at org.apache.phoenix.schema.MetaDataClient.createTable(MetaDataClient.java:1114)at org.apache.phoenix.compile.CreateTableCompiler$1.execute(CreateTableCompiler.java:192)at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:408)at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:391)at org.apache.phoenix.call.CallRunner.run(CallRunner.java:53)at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:390)at org.apache.phoenix.jdbc.PhoenixStatement.executeMutation(PhoenixStatement.java:378)at org.apache.phoenix.jdbc.PhoenixStatement.executeUpdate(PhoenixStatement.java:1806)at org.apache.phoenix.query.ConnectionQueryServicesImpl$12.call(ConnectionQueryServicesImpl.java:2538)at org.apache.phoenix.query.ConnectionQueryServicesImpl$12.call(ConnectionQueryServicesImpl.java:2499)at org.apache.phoenix.util.PhoenixContextExecutor.call(PhoenixContextExecutor.java:76)at org.apache.phoenix.query.ConnectionQueryServicesImpl.init(ConnectionQueryServicesImpl.java:2499)at org.apache.phoenix.jdbc.PhoenixDriver.getConnectionQueryServices(PhoenixDriver.java:269)at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver.createConnection(PhoenixEmbeddedDriver.java:151)at org.apache.phoenix.jdbc.PhoenixDriver.connect(PhoenixDriver.java:228)at java.sql.DriverManager.getConnection(DriverManager.java:664)at java.sql.DriverManager.getConnection(DriverManager.java:208)at org.apache.phoenix.hive.util.PhoenixConnectionUtil.getConnection(PhoenixConnectionUtil.java:98)at org.apache.phoenix.hive.util.PhoenixConnectionUtil.getInputConnection(PhoenixConnectionUtil.java:63)at org.apache.phoenix.hive.mapreduce.PhoenixInputFormat.getQueryPlan(PhoenixInputFormat.java:250)... 42 more
Caused by: org.apache.hadoop.hbase.client.RetriesExhaustedException: Can't get the locationsat org.apache.hadoop.hbase.client.RpcRetryingCallerWithReadReplicas.getRegionLocations(RpcRetryingCallerWithReadReplicas.java:319)at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:156)at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:60)at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:210)at org.apache.hadoop.hbase.client.ClientScanner.call(ClientScanner.java:327)at org.apache.hadoop.hbase.client.ClientScanner.nextScanner(ClientScanner.java:302)at org.apache.hadoop.hbase.client.ClientScanner.initializeScannerInConstruction(ClientScanner.java:167)at org.apache.hadoop.hbase.client.ClientScanner.<init>(ClientScanner.java:162)at org.apache.hadoop.hbase.client.HTable.getScanner(HTable.java:797)at org.apache.hadoop.hbase.MetaTableAccessor.fullScan(MetaTableAccessor.java:602)at org.apache.hadoop.hbase.MetaTableAccessor.tableExists(MetaTableAccessor.java:366)at org.apache.hadoop.hbase.client.HBaseAdmin.tableExists(HBaseAdmin.java:406)at org.apache.phoenix.query.ConnectionQueryServicesImpl.ensureTableCreated(ConnectionQueryServicesImpl.java:1097)... 64 more
可以看出是提交Job的时报错了,错误原因是
Job Submission failed with exception 'java.lang.RuntimeException(org.apache.phoenix.exception.PhoenixIOException: Can't get the locations)'
java.lang.RuntimeException: org.apache.phoenix.exception.PhoenixIOException: Can't get the locations
Hive日志里面没有任何日志信息,由于是Hive的外部Phoenix表,所以可能是hive上有问题,直接尝试使用pyhive连接hive进行查询
from pyhive import hive
conn = hive.Connection(host=host,port=10000,username='',database='default',auth='NONE')
cursor = conn.cursor()
cursor.execute('select * from ext_table limit 1')
重新启动Hive,并开启debug日志
hive --service hiveserver2 -hiveconf hive.root.logger=DEBUG,console
多次执行python脚本之后在hive的日志中可以看到如下
20/05/18 06:47:42 [HiveServer2-Handler-Pool: Thread-224-SendThread(172.100.0.11:2181)]: WARN zookeeper.ClientCnxn: Session 0x0 for server 172.100.0.11/172.100.0.11:2181, unexpected error, closing socket connection and attempting reconnect
java.io.IOException: Connection reset by peerat sun.nio.ch.FileDispatcherImpl.read0(Native Method)at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)at sun.nio.ch.IOUtil.read(IOUtil.java:192)at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:377)at org.apache.phoenix.shaded.org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:68)at org.apache.phoenix.shaded.org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)at org.apache.phoenix.shaded.org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
发现连接zookeeper被reset了,查看对应的zookeeper日志
2020-05-18 06:47:42,568 [myid:11] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@188] - Too many connections from /172.100.0.11 - max is 60
可以看到是因为zookeeper的连接(来自同一个IP的连接,并不是所有的连接)已经达到上限了。查看zookeeper的连接,hive所在机器到zookeeper的连接已经超过最大值了。
修改zookeeper最大连接数
针对以上错误提示,可以直接修改zookeeper的zoo.cfg
maxClientCnxns=500
检查外部表的phoenix.zookeeper.quorum
检查外部表的的phoenix.zookeeper.quorum是否配置了多个zookeeper地址,避免所有phoenix外部表的查询都指向到同一个节点
深入分析
根据初步分析知道,报错的一个原因是连接数达到上限了,回过头来看问题重现的过程,我们是在不断执行相同的操作。也就是即使修改了zookeeper的maxClientCnxns和phoenix.zookeeper.quorum,连接数依然会达到上限,因为修改的两个参数都只是扩大来上限而已,并没有解决连接数增长的问题。为了彻底解决问题,我们需要确定连接数的增长是否有上限,如果有,上限应该是多少,或者是根据其他条件能够明确上限;如果没有,那么需要确定为什么连接没有释放(或者没有重用)?
带着以上两个问题去查看源码,根据上面的分析过程大概知道是hive中的phoenix连接zookeeper是问题所在。查看phoenix的源码
定位到创建连接的地方在org/apache/phoenix/query/ConnectionQueryServicesImpl.java
public class ConnectionQueryServicesImpl extends DelegateQueryServices implements ConnectionQueryServices {...private void openConnection() throws SQLException {try {this.connection = HBaseFactoryProvider.getHConnectionFactory().createConnection(this.config);...} catch (IOException e) {...}...}...public void init(final String url, final Properties props) throws SQLException {...logger.info("An instance of ConnectionQueryServices was created.");openConnection();...}
}
查看调用.init()的地方,定位到org/apache/phoenix/jdbc/PhoenixDriver.java
public final class PhoenixDriver extends PhoenixEmbeddedDriver {protected ConnectionQueryServices getConnectionQueryServices(String url, final Properties info) throws SQLException {connectionQueryServices = connectionQueryServicesCache.get(normalizedConnInfo, new Callable<ConnectionQueryServices>() {@Overridepublic ConnectionQueryServices call() throws Exception {ConnectionQueryServices connectionQueryServices;if (normalizedConnInfo.isConnectionless()) {connectionQueryServices = new ConnectionlessQueryServicesImpl(services, normalizedConnInfo, info);} else {connectionQueryServices = new ConnectionQueryServicesImpl(services, normalizedConnInfo, info);}return connectionQueryServices;}});connectionQueryServices.init(url, info);}
}
可以看到以上代码中使用了Cache,也就是说,如果所有参数相同,那么应该利用缓存才对,没有利用缓存说明每次执行的时候normalizedConnInfo的hashCode并不相同,查看hashCode的生成规则
public static class ConnectionInfo {public ConnectionInfo(String zookeeperQuorum, Integer port, String rootNode, String principal, String keytab) {this.zookeeperQuorum = zookeeperQuorum;this.port = port;this.rootNode = rootNode;this.isConnectionless = PhoenixRuntime.CONNECTIONLESS.equals(zookeeperQuorum);this.principal = principal;this.keytab = keytab;try {this.user = User.getCurrent();} catch (IOException e) {throw new RuntimeException("Couldn't get the current user!!");}if (null == this.user) {throw new RuntimeException("Acquired null user which should never happen");}}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + ((zookeeperQuorum == null) ? 0 : zookeeperQuorum.hashCode());result = prime * result + ((port == null) ? 0 : port.hashCode());result = prime * result + ((rootNode == null) ? 0 : rootNode.hashCode());result = prime * result + ((principal == null) ? 0 : principal.hashCode());result = prime * result + ((keytab == null) ? 0 : keytab.hashCode());// `user` is guaranteed to be non-nullresult = prime * result + user.hashCode();return result;}
}根据上面的信息zookeeperQuorum、port以及rootNode都是相同的字符串,principal和keytab也是相同的字符串,只有user的hashCode比较可疑,查看org/apache/hadoop/hbase/security/User.class
public abstract class User {protected UserGroupInformation ugi;public int hashCode() {return this.ugi.hashCode();}
}
继续查看org/apache/hadoop/security/UserGroupInformation.class
public class UserGroupInformation {private final Subject subject;public int hashCode() {return System.identityHashCode(this.subject);}
}
可以看到这里使用了identityHashCode,这会导致即使请求参数相同,但是每次请求得到的hashCode不同,而导致没有重用缓存。这个Subject对应的是用户名(pyhive默认取的是客户端的用户名)。
修改hive.server2.enable.doAs
查看hive-site.xml配置文件,只需要把hive.server2.enable.doAs设置成false,执行的时候就不会使用客户端的用户,而是使用hive启动的用户。
因为不需要每次请求都创建hive启动的用户对象,因此得到的hashCode相同。
<property><name>hive.server2.enable.doAs</name><value>false</value><description>Setting this property to true will have HiveServer2 executeHive operations as the user making the calls to it.</description></property>
检查连接是否释放
做了以上修改之后,发现zookeeper的连接还是在不断增长,后来发现是我最初使用的版本是apache-phoenix-4.13.1-HBase-1.2里面有很多HConnection connection = HConnectionManager.createConnection()创建的连接没有释放,在最新的版本apache-phoenix-4.14.1-HBase-1.2中已经修复了该问题org/apache/phoenix/hive/mapreduce/PhoenixInputFormat.java
try (HConnection connection = HConnectionManager.createConnection(PhoenixConnectionUtil.getConfiguration(jobConf))) {
}
总结
1、确保使用的Phoenix版本已经修复了连接释放的问题,如果没有请升级到已经修复连接问题的版本apache-phoenix-4.14.1-HBase-1.2及其后续版本
2、hive-site.xml中需要把hive.server2.enable.doAs设置为false
3、可以根据集群使用情况适当调整zoo.cfg的最大连接数maxClientCnxns的值
4、建立Phoenix外部表的时候使用zookeeper集群地址,不要只配置单点
这篇关于[Hue|Hive]return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




