hue专题

大数据-Hadoop-户管理界面:HUE(Hadoop User Experience)【将Hadoop中各种相关的软件(HDFS、Hive...)的操作界面融合在一起,形成一个统一的操作界面】
什么是HUE? hadoop的用户体验 HUE主要的作用将Hadoop中各种相关的软件的操作界面. 给融合在一起, 形成一个统一的操作界面HUE是一个大集成者 Hue 是一个Web应用,用来简化用户和Hadoop集群的交互。Hue技术架构,如下图所示,从总体上来讲,Hue应用采用的是B/S架构,该web应用的后台采用python编程语言别写的。大体上可以分为三层,分别是前端view层、Web服

CDH5.17版本Hue接入HBase步骤
1.启动HBase中的thrift服务; 2.在Hue的配置中搜索ini 然后在 hue_safety_value.ini的Hue服务高级配置代码段(安全阀) 添加如下配置: [hbase] hbase_conf_dir=/opt/cloudera/parcels/CDH/lib/hbase/conf thrift_transport=buffered 3.选点如下图的配置

脚本自动定时启动/停止Cloudera版本的Hue
我们可以利用基于Cloudera的Hue的API接口 停止命令: curl -X POST -u 'admin:admin' http://ip:7180/api/v18/clusters/cluster/services/hue/commands/stop 启动命令: curl -X POST -u 'admin:admin' http://ip:7180/api/v18/clus
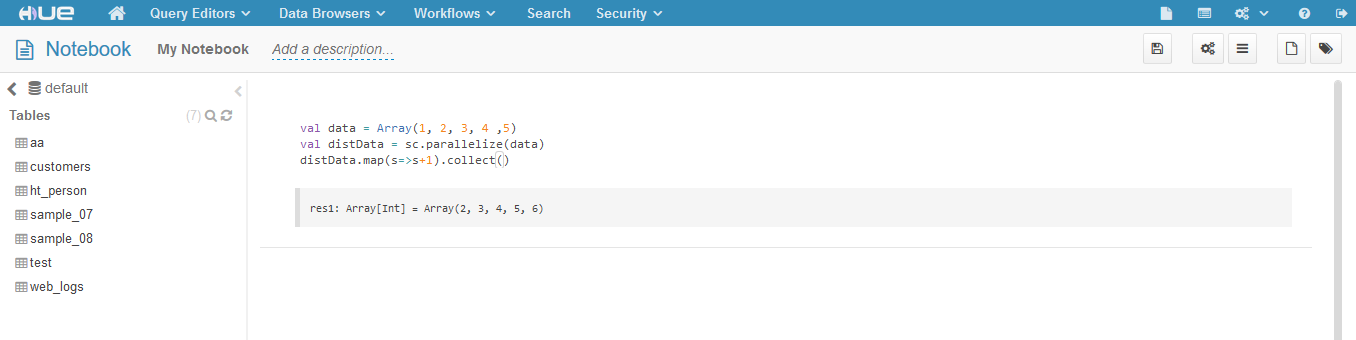
HUE配置Spark Notebook
在HUE3.10版中已经具有spark notebook的功能,但需要自己配置。 安装步骤 主要参照run-hue-spark-notebook-on-cloudera进行。 注意点 在第四步, #download Livywget http://archive.cloudera.com/beta/livy/livy-server-0.2.0.zipunzip livy-se
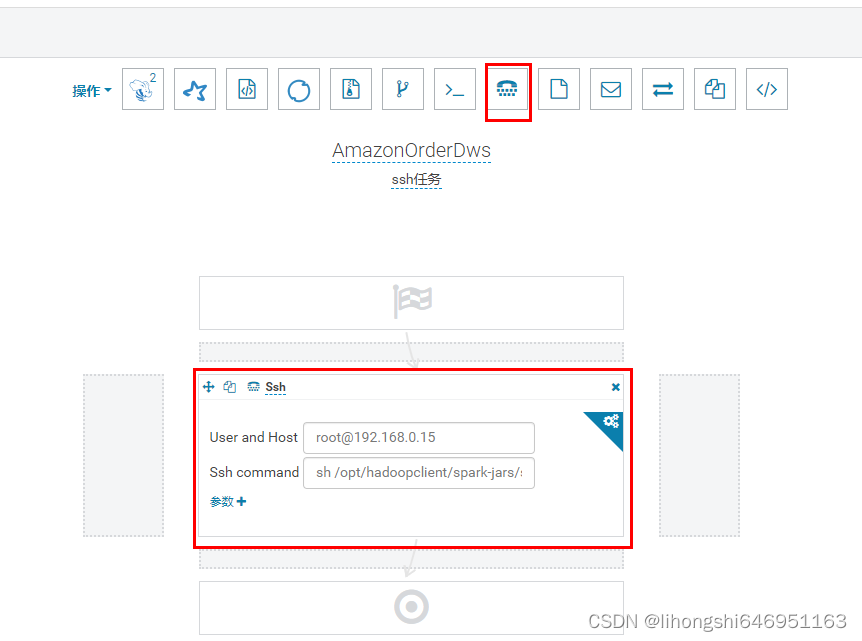
在hue中使用ooize调度ssh任务无法执行成功,无法查看错误
ssh执行失败,但是hue没有给出明确的错误原因: 经过经验分析,原来是服务器上的sh文件用的是doc/window格式,需要使用notepad++将格式改为unix之后就可以正常执行。 特此记录,避免遗忘知识点
![[bigdata-037]apache hue 用SQL获取数据以及可视化](/front/images/it_default2.jpg)
[bigdata-037]apache hue 用SQL获取数据以及可视化
1. hue官网 https://github.com/cloudera/hue http://gethue.com/ 2. hue的功能 有py2+django开发,提供Hive, Impala, MySQL, Oracle, PostgreSQL, Spark SQL, Solr SQL, Phoenix...等SQL数据获取和页面展示 3. 用docker 安装hue

hue编译时出现_mysql.c:2005:41: error: ‘MYSQL’ has no member named ‘reconnect’
错误信息 building '_mysql' extension creating build/temp.linux-x86_64-2.7 gcc -pthread -fno-strict-aliasing -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-bu
[喵咪大数据]HUE大数据管理工具
日常的大数据使用中经常是在服务器命名行中进行操作,可视化功能仅仅依靠着各个组件自带的网页进行,那么有没有一个可以结合大家能在一个网页上的管理工具呢?答案是肯定的,今天就和大家一起来探索大数据管理工具HUE的庐山真面目. 附上: 喵了个咪的博客:w-blog.cn 1.环境准备 编译依赖 wget http://repos.fedorapeople.org/repos/dchen/ap
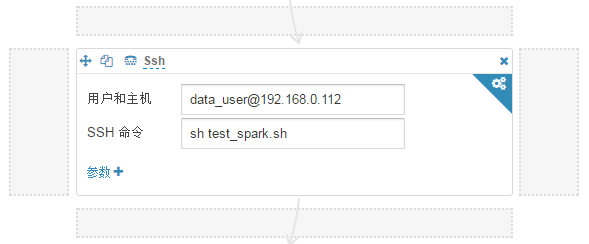
Spark job在hue-oozie中的另一种方式调度
工作中使用的是hue来配置oozie工作流调度及任务中调度关系,spark job的输入是由hive sql产生输出的表,在配置spark job由于一些客观关系出现很多问题导致无法正确的执行,在oozie中支持spark job的及shell job的配置执行 1. 采用spark program组件配置, 目前版本过低无法添加运行时的一些参数 官网http://gethue

Cloudera Manager Hue 集成其他组件
Hue 集成其它组件 Hue集成其它组件很简单,首先需要安装好需要集成的组件。然后在Hue 配置页面勾选中需要集成的组件,然后重启Hue就可以了,如下图所示: 但是,Hue集成RDMBS(DB Query)需要额外配置: put configuration in HUE as below: 在上面配置框中输入如下配置: [librdbms]# The RDBMS app can
hue(5):Hue与zookeeper、oozie、Hbase集成
一、配置步骤 1.和zookeeper集成,修改hue.ini [zookeeper] [[clusters]] [[[default]]] # Zookeeper ensemble. Comma separated list of Host/Port. # e.g. localhost:2181,localhost:2182,localhost:2183 host_ports=ha
hue集成mysql问题:配置hue.ini后,进入hue界面无法访问mysql数据库内容
1.问题描述 进入hue界面http://hadoop:8888/rdbms/#,发现mysql数据库没有反应,无法获得数据。 2.原因 hue.ini中的[[[mysql]]]前面两个##没有删除,所以,myslq没有生效。 3.解决 删除两个##,重启hue即可访问mysql
hue(4):Hue与mysql集成
1.配置Hue.ini [[[mysql]]]# Name to show in the UI.nice_name="My SQL DB"# For MySQL and PostgreSQL, name is the name of the database.# For Oracle, Name is instance of the Oracle server. For express edit
hue(3):Hue与Hive集成
1.修改hive-site.xml <property><name>hive.server2.thrift.bind.host</name><value>hadoop</value></property><property><name>hive.metastore.uris</name><value>thrift://hadoop:9083</value><description>Thrift
hue(2):Hue与Hadoop集成
一、实现功能 hue界面可以浏览、更改、添加hdfs上的文件,从而,便于更多人员操作大数据平台。 二、实现步骤 1.hadoop配置 (1)配置etc/Hadoop/hdfs-site.xml <property><name>dfs.webhdfs.enabled</name><value>true</value></property><!--下面这个自己本来就有!--><prop

Hue error: 集成hive报错Could not start SASL: Error in sasl_client_start (-4) SASL(-4): no mechanism avai
1.问题描述 hue配置完hive后,打开hue界面报错: Could not start SASL: Error in sasl_client_start (-4) SASL(-4): no mechanism available: No worthy mechs found (code THRIFTTRANSPORT): TTransportException('Could not sta
cloudera cdh.511.2 安装hive hue等组件数据库连接出现问题
在测试连接的时候出现这个问题:logon denied for user/password. able to find the database server and database,but the login request was rejected. 参考了这篇文章也没搞好。
1.7.1 大数据-HUE可视化软件安装
版本 hue-3.9.0-cdh5.5.0 下载解压 http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.0.tar.gz tar -zxf hue-3.9.0-cdh5.5.0.tar.gz -C /opt/modules 编译 联网虚拟机里面设置为自动连接切换为root用户安装相关依赖包 yum install ant

安装HDFS的HA后配置hue与hive
安装HDFS的HA后配置hue与hive 一、配置hue1.1 安装HdfsFS1.2 配置hue 二、配置hive 在配置完hdfs的HA后,提示需要重新配置如下内容: 将 Hue 服务 Hue 的 HDFS Web 界面角色 配置为 HTTPFS 角色,而非 NameNode。 Documentation对于每个 Hive 服务 Hive,停止 Hive 服务,将 Hive
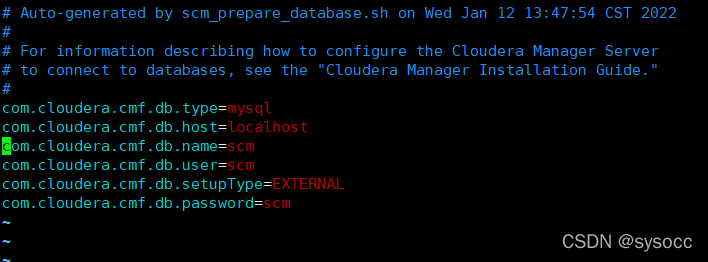
安装CDH6.2时hive、hue、oozie等找不到对应数据库
问题描述:如下图(忘了截图,找个了类似的),hive、hue、oozie等都找不到对应数据库,No database server found running on host xxx: 编辑文件 /etc/cloudera-scm-server/db.properties,发现服务端配置文件里默认是localhost: 这里有两种解决方法: 方法一:安装界面数据库主机名改为 localh

HUE middleware INFO Processing exception: StandbyException: Operation category RAD is not supported
HUE middleware INFO Processing exception: StandbyException: Operation category RAD is not supported 原因是:HDFS高可用(HA)活动节点变了,而HUE HDFS Web url没有变,导致HUE HDFS Web url用的是NameNode节点是standby namenode,所以出现问
Linux-centos下安装hue可视化以及与hdfs、hive、hbase和mysql的集成
1. Hue概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。 2)
pairplot 中参数hue的作用就是在图像中将输出的散点图按照hue指定的特征或标签的类别的颜色种类进行区分
sns.pairplot(diabetes,hue="Outcome"); pairplot 中参数hue的作用就是在图像中将输出的散点图按照hue指定的特征或标签的类别的颜色种类进行区分 https://www.jianshu.com/p/6e18d21a4cad
HUE配置Impala队列提交SQL
目前,我们可以通过HUE连接到impala集群来提交SQL,进行一些数据分析和测试验证工作,非常方便,不用再额外配置beeline环境或者在java代码里面通过jdbc调用。但是,在hue上面提交SQL的时候,默认是会提交到default队列上,而线上集群往往都会根据业务设置相应的队列。因此,default上预留的资源一般不会很多,当需要跑一些比较大的SQL的时候,就需要选择相应业务的队列,否则可