本文主要是介绍爬虫写得好,监狱进的早?我看太刑了,日子越来越有判头了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
你在网上的匿名言论,在爬虫面前可能毫无隐私可言,在一些社交平台中,看似可以肆意吐槽发言的隐秘角落,如果有别有用心的人,使用爬虫进行大数据分析,每个用户的行为都形同于裸奔。事实上,在网络空间,对于爬虫的使用和安全防攻程度早已超出了普通人的想象 。那么今天我就结合一些现实中发生的一些真实防攻案例和大家讨论——写爬虫真的会坐牢吗?

一、爬虫初识,什么是爬虫?
简单来讲,爬虫就是一个探测机器,它的基本原理就是模拟人的行为去各个网站溜达,点点按钮、查查数据,或者把看到的信息抓回来。
如果用专业一点的说法,一个最简单的爬虫就是通过程序用技术模拟人的操作,从中获取到服务器里众多数据,先解析出自己需要的信息,再由程序决定接下来做什么。
【----帮助技术学习,以下所有学习资料文末免费领!----】

有可能是拿到网页中的某个标签链接,继续跳转到下一个页面。也有可能把获取到的信息直接存储到本地或数据库中。但这些都还是传统意义上的爬虫。或许扒一扒匿名社区,搜罗所谓极端发言时能提高效率。
二、爬虫的涉及方面?
在现如今的爬虫,高手和大公司之间的博弈早已不限于web端,还会涉及到客户端逆向、动态调试分析等,真实的攻防场景和爬虫带来的巨大利益要远远超过人们的想象。爬虫最基础的就是抓取,我们习惯于把一次http请求拿回数据并分析自己需要的数据的过程,称为一次“抓取”。
比如你手动在百度里面搜索“张三”,这即是你http向百度服务器发出的一次请求。爬虫的“抓取”是模拟人的行为,不过它与你手动发出的请求不同,它是由机器或者说程序批量发起。

比如你每天使用的百度,就是利用了这样的爬虫技术 ,它每天发出无数个爬虫到各个网站把它们的信息抓取回来,然后化好妆排着小队等着你来检索。

前些年12306刚刚上线的时候,市面上也出现了大量的抢票软件。你可能不知道,这些抢票软件也是利用了爬虫技术,相当于帮你撒出去无数个分身都在不断的刷新12306网站的火车余票,一旦发现有票,就马上拍下来,然后喊你“快来付款”。
众所周知,技术本身并没有善恶之分,关键在于掌握在什么人手里。

三、恶意爬虫
很多政务网站,新闻聚合类媒体等背后都有爬虫的应用,可以说没有爬虫就没有“互联网”。知识区有个神仙般的大up,他会用爬虫将小伙伴们的弹幕评论等爬取下来,然后进行分析、比对,有针对性地进行优化行文,大大提高工作效率 。但是像抢票这样的爬虫,对着12306恨不得撸几万次,这种就定为“恶意爬虫”。

四、反爬虫
但是,有爬虫的地方就有反爬虫,这是一个攻防的过程。攻击可以定义为,在未授权的前提下,通过技术手段模拟真人操作,获取目标系统,对真实用户展示的信息。防御可以定义为对攻击欣慰进行干预、拦截、溯源等。 在网络安全领域没有绝对的固若金汤,一切攻防手段都是“魔高一尺,道高一丈”,正对爬虫买的攻防博弈也是如此。
从web端的IP封禁,到验证码识别发起请求者是人还是机器人,再到祭出内容“投毒”, 爬虫与反爬虫之间的博弈永远没有尽头。

倘若把我们防护网和网站APP比作是一座城,最原始的爬虫机械化地发起一个开门请求,如果没有防守策略,就会导致城门大开,面对无人把守的城门,爬虫可能得寸进尺,开始疯狂进出。**为了守住城门,保证服务器的稳定,守门人必须开启IP封禁,如果爬虫过于频繁的来访,反扒这便会记住爬虫所现在的IP地址,对这样的恶意爬虫直接进行IP封禁。**不过这样的防御手段,通常只对web端的爬虫起作用,用户登录账号时弹出的验证码是反爬虫的又一大利器。

它是由计算机天才“路易斯.冯.安”和他的小伙伴提出的,全名叫“全自动区分计算机和人类的公开图灵测试”。
不论是拼图还是找数字和文字,都是系统向请求的发起第方提出问题,能正确回答的就是人类,**反之则被判定为机器。**当然,验证码并不是专为反爬虫而生,起初是为了解决机器批量下发垃圾邮件的问题。我们前面也说了,爬虫行为也是机器批量行为,所以当发现爬虫时弹出验证码就能防止爬虫行为。

随着网络攻防不断演化,又出现了“打码平台”来识别验证码,甚至用AI来打码来突破防御。
这里就需要系统有更强的洞察能力,通过蛛丝马迹分辨出到底是人还是机器。验证码经过几代演进,在12306系统应用中达到了巅峰,其题目难度和通过率让人望而却步。
比如在屏幕上的这张图片中找出喜羊羊,当然这个验证码并不是为了故意刁难老老实实买票的人,而是被爬虫逼得没办法。

五、“蜜罐”技术
对待爬虫不一定要一刀切拦截,在网络安全领域,有一种技术叫做“蜜罐”,英文名是“honeypot”。

你可以想象这样一种场景,把蜂蜜装在罐里作为诱饵诱引昆虫陷进去,诱引昆虫入陷进,放在爬虫抓取防御的技术上面,可以叫做“内容投毒”。当被爬方发现疑似非授权的爬虫爬取数据时,并不是直接打开,而是给出错误信息。
比如电商为了爬取同行平台商品价格,同行为了反爬,故意显示给爬虫错误的价格,而消费者正常搜索看到的才是正确的价格。

这里讲一个真实的案例:
张三准备偷偷爬取李四的页面内容,李四早有防备,有针对性的在搜索结果中加入了一段文案“搜索结果来自李四”,由于张三在抓取过程中没有遇到验证码之类的阻拦,于是自李四认为可以万事大吉的爬取使用,后面的事大家应该都略有耳闻,这样的文案被大大方方的展示在张三公司的前端页面上,相当于昭告天下,张三家号称自研的搜索引擎,其实内容都是从李四那里爬来的。这波操作可以说攻击性不大但侮辱性极强。

六、写爬虫会面临哪些法律风险?
坊间还有一个这样的段子“爬虫写得好,监狱进的早”。

网络爬虫本身是一种信息搜集技术,是中立的技术,而技术本身没有违法和非法之分。
就好比菜刀,它可以用来犯罪,它也可以用来切菜,菜刀本身只是一种技术或者工具,无所谓正当与否。爬虫技术本身也不是恶意技术,但结合一些恶意行为或者里面加入一些恶意的程序或工具,那可能涉嫌违法。
具体从刑法来讲,如果强行突破被爬方的某些特定的技术措施,可能构成非法获取计算机信息系统数据罪,如果在数据抓取过程中,实施了对计算机的非法控制行为,可能构成非法控制计算机系统罪。如果使用爬虫对目标网站的功能和正常运行造成干扰,导致其访问流量增大,系统反应变缓,影响系统运营,也可能构成破坏计算机信息系统罪。

再从你要爬取的目标数据来看,如果这个数据本身是公民的个人信息,商业秘密、国家秘密,这样哪怕你使用的是合法技术,但是你的目标数据失手法律保护的,你爬取的这些数据也有可能构成侵犯公民个人信息罪、侵犯商业秘密罪、非法获取国家秘密罪。

七、如果信息是公开的,爬取是否违法呢?
答案是:如果这些信息是违法公开的或者说不是公民自动或主动公开的,爬取这些信息也涉嫌侵犯公民个人信息罪。这几年,互联网公司用爬虫技术对簿公堂的案例也不少。
比较知名的有“大众点评诉百度案”,原因在于百度爬取了大众点评上的用户点评信息;

再比如“新浪微博诉脉脉案”,新浪微博起诉的原因是:脉脉未经授权和用户同意获取使用新浪微博用户的信息,这两起案件法院终审认定百度、脉脉的爬取行为违反了《反不正当竞争法》,属于不正当行为,最终百度赔偿大众点评323万元;脉脉赔偿新浪微博200万元。

八、我只是个小码农
今年1月1号起施行的《民法典中》也有知识产权相关规定,爬虫行为也有可能侵犯著作权等知识产权。 讲到这里那么就有小伙伴会问了,我只是一个公司的小码农,根据公司的要求写爬虫代码也要承担责任吗?

这要分几种情况来看,如果公司的这种爬取行为,构成了不正当竞争,要承担民事责任,这由公司全部承担。如果涉嫌触犯刑法的,那就是属于公诉案件,不是给钱私了就能解决的事,它可能构成单位犯罪。除了罚你公司钱外,你公司直接负责的主管人员,比如说你的主管或者领导,或者是分管的副总裁,甚至公司法定代表人要被判处刑罚。至于你要不要坐牢,要看你在这个过程中是否发挥了主管能动性,是否起到了推动作用。
这样来看,写爬虫真的有可能坐牢,而且写的越好,风险可能越大。
最后我想说的是,当我们在使用爬虫的时候,内心始终要遵循这样一条信仰,我们在运用着自己力所能及的一些方法和工具,目的是一点一点地让这个世界变得更加完美和美好。
一、Python入门
下面这些内容是Python各个应用方向都必备的基础知识,想做爬虫、数据分析或者人工智能,都得先学会他们。任何高大上的东西,都是建立在原始的基础之上。打好基础,未来的路会走得更稳重。所有资料文末免费领取!!!
包含:
计算机基础
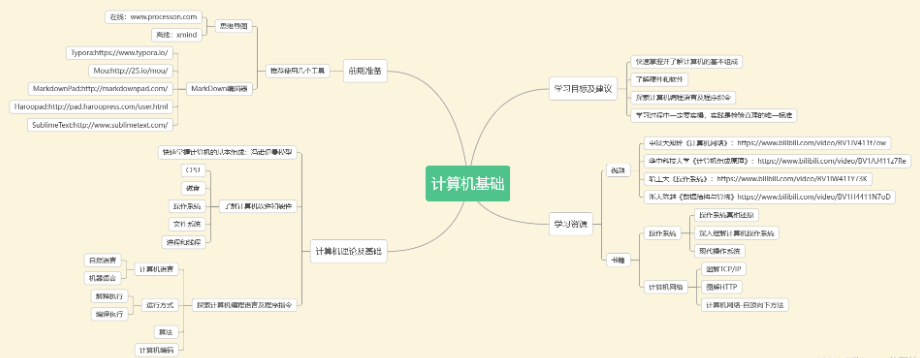
python基础

Python入门视频600集:
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
二、Python爬虫
爬虫作为一个热门的方向,不管是在自己兼职还是当成辅助技能提高工作效率,都是很不错的选择。
通过爬虫技术可以将相关的内容收集起来,分析删选后得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等,都能够借助爬虫技术获取更精准有效的信息加以利用。

Python爬虫视频资料
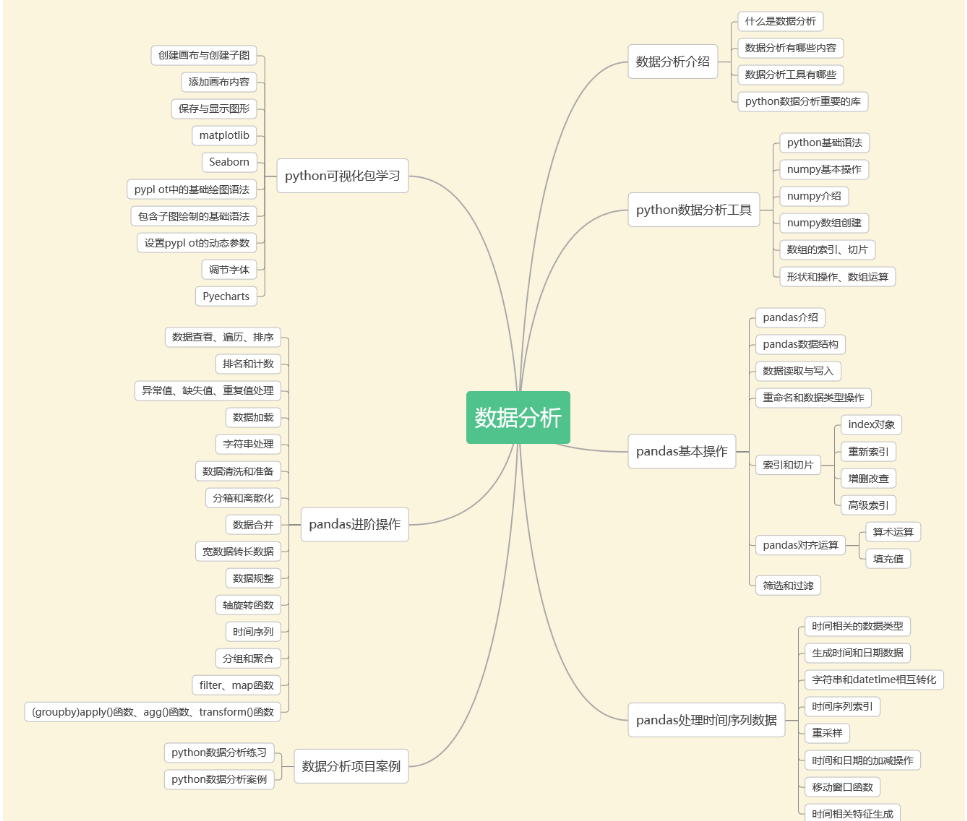
三、数据分析
清华大学经管学院发布的《中国经济的数字化转型:人才与就业》报告显示,2025年,数据分析人才缺口预计将达230万。
这么大的人才缺口,数据分析俨然是一片广阔的蓝海!起薪10K真的是家常便饭。
四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
五、机器学习
机器学习就是对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

机器学习资料:
六、Python高级进阶
从基础的语法内容,到非常多深入的进阶知识点,了解编程语言设计,学完这里基本就了解了python入门到进阶的所有的知识点。

到这就基本就可以达到企业的用人要求了,如果大家还不知道去去哪找面试资料和简历模板,我这里也为大家整理了一份,真的可以说是保姆及的系统学习路线了。
但学习编程并不是一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
资料领取
这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以点击下方CSDN官方认证微信卡片免费领取 ↓↓↓【保证100%免费】

这篇关于爬虫写得好,监狱进的早?我看太刑了,日子越来越有判头了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








