本文主要是介绍one-hot Embedding 理论知识详解 + 代码实操 (为学习笔记模式,同时附完整代码)【独热向量编码】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目 标:使用one-hot Embedding 处理数据库查询语句,使其变成向量模式,以下为个人学习笔记和学习过程中用到的完整代码。
环 境:腾讯云服务器 Linux系统(具体环境会在代码段前进行标注)
目录
一、one-hot 理论基础
二、用 one-hot 处理句子?
三、用one-hot处理查询语句
四、如果我使用更长的查询语句呢?one-hot能处理吗?
4.1 字符型数据的单引号屏蔽问题
4.2 如何依次读取文件夹中的sql文件并进行编码
五、解决“如何依次读取文件夹中的sql文件并进行编码”问题
5.1 如何用Python读取sql文件
5.2 如何用Python遍历文件夹中的文件
5.3 用Python遍历文件夹中的sql文件并将它们变成向量形式
Bing! 任务完成!
六、one-hot的优缺点总结
6.1 优点
6.2 缺点
一、one-hot 理论基础
进行机器学习,就需要对数据的特征进行提取,但有些数据是离散非连续的,这个时候就需要将这些特征转换为向量形式。
one-hot向量编码,就是将每个特征都进行0 1 表示,具体的解说可以参看下面这篇文章,它描述得非常详细。
【one-hot理论详解】![]() https://blog.csdn.net/qq_38651469/article/details/121100275
https://blog.csdn.net/qq_38651469/article/details/121100275
下面放入一段使用了one-hot 的简单代码(python版本3.7.0)
from sklearn import preprocessingenc = preprocessing.OneHotEncoder()
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])array = enc.transform([[1,2,3]]).toarray()print(array)【运行结果】

【解析】(都是自学的不一定对哈)
preprocessing.OneHotEncoder() 调用起One-hot
enc.fit([ ]) 传入了学习数据
enc.transform([1,2,3]) 得出了预测结果
二、用 one-hot 处理句子?
根据上面的实验,我做了进一步的测试,发现这种方法只能对数字特征进行编码,无法编译中英文,但我的目标是通过One-Hot编译查询语句,因此我的进阶学习路线为:用one-hot处理句子。
于是我找到了这篇文章:
【实现对文本的简单one-hot编码】![]() https://blog.csdn.net/Einstellung/article/details/82865224?spm=1001.2014.3001.5506按照文章中所提到的,首先,使用one-hot对单词进行编码
https://blog.csdn.net/Einstellung/article/details/82865224?spm=1001.2014.3001.5506按照文章中所提到的,首先,使用one-hot对单词进行编码
from keras.preprocessing.text import Tokenizersamples = ['The cat sat on the mat.', 'The dog ate my homework.']tokenizer = Tokenizer(num_words=1000) # i创建一个分词器(tokenizer),设置为只考虑前1000个最常见的单词tokenizer.fit_on_texts(samples) # 构建索引单词sequences = tokenizer.texts_to_sequences(samples) # 将字符串转换为整数索引组成的列表one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
#可以直接得到one-hot二进制表示。这个分词器也支持除了one-hot编码外其他向量化模式
print(one_hot_results)# 这个one-hot-result就是向量表示word_index = tokenizer.word_index # 得到单词索引
print('Found %s unique tokens.' % len(word_index))【运行结果】(需要使用Keras框架)
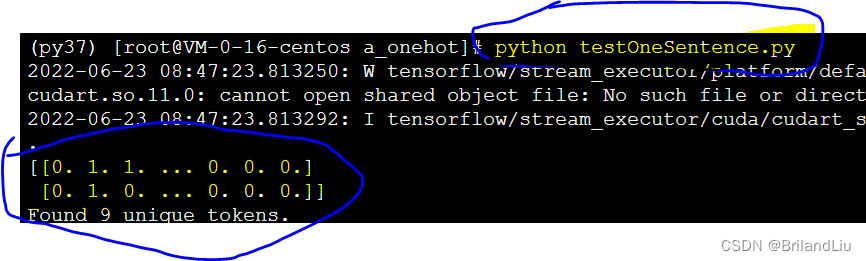
【解析】
Keras框架自带One-hot编码方式,因此只给出要训练的语句就行了。
输出的三个东西分别是
①前面两个 0 1 向量序列是对
['The cat sat on the mat.', 'The dog ate my homework.']
的编码。
② “Found 9 unique tokens” 是指遇到了9个单词—— The出现两次所以选1个单词。
三、用one-hot处理查询语句
假设我有一个SQL查询语句如下:
SELECT MIN(mc.note) AS production_note,MIN(t.title) AS movie_title,
FROM company_type AS ct,info_type AS it,movie_companies AS mc,
WHERE ct.kind = 'production companies'AND it.info = 'top 250 rank'那么我首先尝试将其放进Sample,代入Keras框架进行 one-hot向量表示
from keras.preprocessing.text import Tokenizersamples = ['SELECT MIN(mc.note) AS production_note FROM company_type AS ct', 'SELECT MIN(t.title) AS movie_title']tokenizer = Tokenizer(num_words=1000) # i创建一个分词器(tokenizer),设置为只考虑前1000个最常见的单词tokenizer.fit_on_texts(samples) # 构建索引单词sequences = tokenizer.texts_to_sequences(samples) # 将字符串转换为整数索引组成的列表one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
#可以直接得到one-hot二进制表示。这个分词器也支持除了one-hot编码外其他向量化模式
print(one_hot_results)# 这个one-hot-result就是向量表示word_index = tokenizer.word_index # 得到单词索引
print('Found %s unique tokens.' % len(word_index))可以看到的是——在这里,我将样本替换为了查询语句,实验结果证明,one-hot可以对其进行编码,并有效地查出了13个 “unique tokens”
【运行结果】

另,one-hot 似乎并不对标点符号进行编码
四、如果我使用更长的查询语句呢?one-hot能处理吗?
因为查询语句经常非常长,而且包含各种数据类型,不知道One-Hot能不能对这种混合数据模式进行编码,因此,下一步实验是——将sample里的查询语句加长
(大家可以在代码中看到,我已经将查询语句的长度加长到了一个变态的程度)
from keras.preprocessing.text import Tokenizersamples = ['SELECT MIN(mc.note) AS production_note, MIN(t.title) AS movie_title, FROM company_type AS ct, info_type AS it, WHERE ct.kind = production companies AND it.info = top 250 rank AND mc.note NOT LIKE %(as Metro-Goldwyn-Mayer Pictures)%']tokenizer = Tokenizer(num_words=1000) # i创建一个分词器(tokenizer),设置为只考虑前1000个最常见的单词tokenizer.fit_on_texts(samples) # 构建索引单词sequences = tokenizer.texts_to_sequences(samples) # 将字符串转换为整数索引组成的列表one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')
#可以直接得到one-hot二进制表示。这个分词器也支持除了one-hot编码外其他向量化模式
print(one_hot_results)# 这个one-hot-result就是向量表示word_index = tokenizer.word_index # 得到单词索引
print('Found %s unique tokens.' % len(word_index))
【运行结果】
————!!! WARNING ! ! ! 下图高度密集!密恐患者速速撤离!————

就,跑也能跑,但向量也是真 的 大 啊
此外,在运行的过程中遇到了两个问题,都是必须考虑的。
4.1 字符型数据的单引号屏蔽问题
在查询语句中经常会带有字符型的数据,这些数据的单引号会造成错误,导致部分数据无法录入。
因此,在对带有字符型数据的查询语句进行编码时,就必须先对这些双引号进行屏蔽。
4.2 如何依次读取文件夹中的sql文件并进行编码
在训练的过程中,势必不可能总是手动将查询语句替换进去,因此还涉及到一个如何用Python进行文件夹读取并代入的问题。
五、解决“如何依次读取文件夹中的sql文件并进行编码”问题
5.1 如何用Python读取sql文件
首先,拆解问题为:“如何用python读取sql文件”(先只读取一个文件,之后再尝试依次读取文件夹)
参考了下面这篇文章的做法:
【使用Python读取sql文件】![]() https://blog.csdn.net/zyq_victory/article/details/90297701?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165595433116781818734050%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165595433116781818734050&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~pc_rank_34-5-90297701-null-null.142%5Ev20%5Epc_rank_34,157%5Ev15%5Enew_3&utm_term=%E5%A6%82%E4%BD%95%E7%94%A8python%E8%AF%BB%E5%8F%96sql%E6%96%87%E4%BB%B6&spm=1018.2226.3001.4187
https://blog.csdn.net/zyq_victory/article/details/90297701?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165595433116781818734050%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165595433116781818734050&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~pc_rank_34-5-90297701-null-null.142%5Ev20%5Epc_rank_34,157%5Ev15%5Enew_3&utm_term=%E5%A6%82%E4%BD%95%E7%94%A8python%E8%AF%BB%E5%8F%96sql%E6%96%87%E4%BB%B6&spm=1018.2226.3001.4187
根据服务器的路径,将代码改造如下:
# sql文件夹路径
sql_path = '/root/Liujq/a_onehot/onehot_data' + '/'# sql文件名, .sql后缀的
sql_file = '1a.sql'# 读取 sql 文件文本内容
sql = open(sql_path + sql_file, 'r', encoding='utf8')
sqltxt = sql.readlines()
# 此时 sqltxt 为 list 类型# 读取之后关闭文件
sql.close()# list 转 str
sql = "".join(sqltxt)# 输出一下看看能不能完整地读出来
print(sql)
可以,能读得出来:

5.2 如何用Python遍历文件夹中的文件
然后,尝试将文件夹里的所有sql文件依次读出 (下面这个代码只能读取出文件名,就是看看能不能读)
import ospath = '/root/Liujq/a_onehot/onehot_data'
for filename in os.listdir(path): #读取Path路径下的文件名print(filename)
5.3 用Python遍历文件夹中的sql文件并将它们变成向量形式
import os
from keras.preprocessing.text import Tokenizerpath = '/root/Liujq/a_onehot/onehot_data/'
for filename in os.listdir(path): #读取Path路径下的文件,此时文件名是指针形式。print(filename)# 读取 sql 文件文本内容sql = open(path + filename, 'r', encoding='utf8')sqltxt = sql.readlines()# 此时 sqltxt 为 list 类型# 读取之后关闭文件sql.close()# list 转 strsql = "".join(sqltxt) #得到str形式的sql文件内容# 将sql内容放进要被转换的samples里samples = [sql]tokenizer = Tokenizer(num_words=1000) # i创建一个分词器(tokenizer),设置为只考虑前1000个最常见的单词tokenizer.fit_on_texts(samples) # 构建索引单词sequences = tokenizer.texts_to_sequences(samples) # 将字符串转换为整数索引组成的列表one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')# 可以直接得到one-hot二进制表示。这个分词器也支持除了one-hot编码外其他向量化模式print(one_hot_results) # 这个one-hot-result就是向量表示word_index = tokenizer.word_index # 得到单词索引print('Found %s unique tokens.' % len(word_index))print('==============================================================')Bing! 任务完成!
代码确实能用,就是输出效果过于密恐,不给大家展示了hhh
六、one-hot的优缺点总结
总结来自这篇文章:
one-hot编码优缺点分析![]() https://blog.csdn.net/qq_38651469/article/details/121100275?spm=1001.2014.3001.5506
https://blog.csdn.net/qq_38651469/article/details/121100275?spm=1001.2014.3001.5506
6.1 优点
(1) 解决了分类器不好处理离散数据 的问题。
a. 欧式空间。在回归,分类,聚类等机器学习算法中,特征之间距离计算 或 相似度计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
b. one-hot 编码。使用 one-hot 编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值 就 对应欧式空间的某个点。将离散型特征使用 one-hot 编码,确实会让 特征之间的距离计算 更加合理。
(2) 在一定程度上也起到了 扩充特征的作用。
6.2 缺点
在文本特征表示上有些缺点就非常突出了。
(1) 它是一个词袋模型,不考虑 词与词之间的顺序(文本中词的顺序信息也是很重要的);
(2) 它 假设词与词相互独立(在大多数情况下,词与词是相互影响的);
(3) 它得到的 特征是离散稀疏 的 (这个问题最严重)。
上述第3点展开:
(1) 为什么得到的特征是离散稀疏的?
例如,如果将世界所有城市名称作为语料库的话,那这个向量会过于稀疏,并且会造成维度灾难。如下:
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。
(2) 能不能把词向量的维度变小呢?
a) Dristributed representation:
可以解决 One hot representation 的问题,它的思路是:
1. 通过训练,将 每个词 都映射到一个 较短的词向量 上来。
2. 所有的这些 词向量 就构成了 向量空间,
3. 进而可以用 普通的统计学的方法 来研究词与词之间的关系。
这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
b) 举例:
1. 比如将词汇表里的词用 "Royalty", "Masculinity", "Femininity" 和 "Age" 4个维度来表示,King 这个词对应的词向量可能是 (0.99,0.99,0.05,0.7)。

2. 在实际情况中,并不能对词向量的每个维度做一个很好的解释。
3. 将king这个词从一个可能非常稀疏的向量坐在的空间,映射到现在这个 四维向量 所在的空间,必须满足以下性质:
(1)这个映射是单射;
(2)映射之后的向量 不会丢失之前的 那种向量 所含的信息 。
4. 这个过程称为 word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。如图:

5. 经过我们一系列的降维神操作,有了用 representation 表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到 2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:


6. 出现这种现象的原因是,我们得到最后的词向量的训练过程中引入了词的上下文。举例:

想到得到 "learning" 的词向量,但训练过程中,你同时考虑了它左右的上下文,那么就可以使 "learning" 带有语义信息了。通过这种操作,我们可以得到近义词,甚至 cat 和它的复数 cats 的向量极其相近。
—————— END ——————
这篇关于one-hot Embedding 理论知识详解 + 代码实操 (为学习笔记模式,同时附完整代码)【独热向量编码】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




