本文主要是介绍作业帮实时数仓架构中的Doris是如何发挥神威的,一文玩儿透(建议收藏),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关 注 公 众 号,获 取 更 多 技 术 好 文~
摘要:今天分享的内容是Doris在作业帮实时数仓架构中的应用及实践
分享时间:2021年6月05日
内容分享:利敏
摘要整理:皮卡丘
主要内容:
1、作业帮业务与背景
2、基于Doris的实时查询系统
3、未来规划

Apache Doris
支持对海量大数据进行快速分析的MPP数据库
Apache Doris一款基于大规模并行处理技术的交互式SQL分析数据库,仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析Apache Doris由百度于2018年贡献给 Apache 基金会,目前正在孵化

一、业务背景介绍
1、数仓逻辑分层
2、过去的业务支持模式
3、总体架构图
4、成效收益
1.1、数仓逻辑分层:
提到数仓,绕不开的话题就是如何分层,但在这个问题上大家好像有个统一的答案,来,上架构图吧:

注:大数据团队主要负责ODS-DWS的建设,从DWS到ADS一般是数仓系统和业务线系统的边界。在过去,由于缺失统一的查询系统,探索了很多模式来支持各个业务线发展。
PS:虽然架构趋同,但在不同的业务模式和场景下,各个企业都有着自己鲜明的特点,正所谓“君子和而不同”。但殊途同归,最终都是为了给业务赋能~
1.2、过去的业务支持模式:
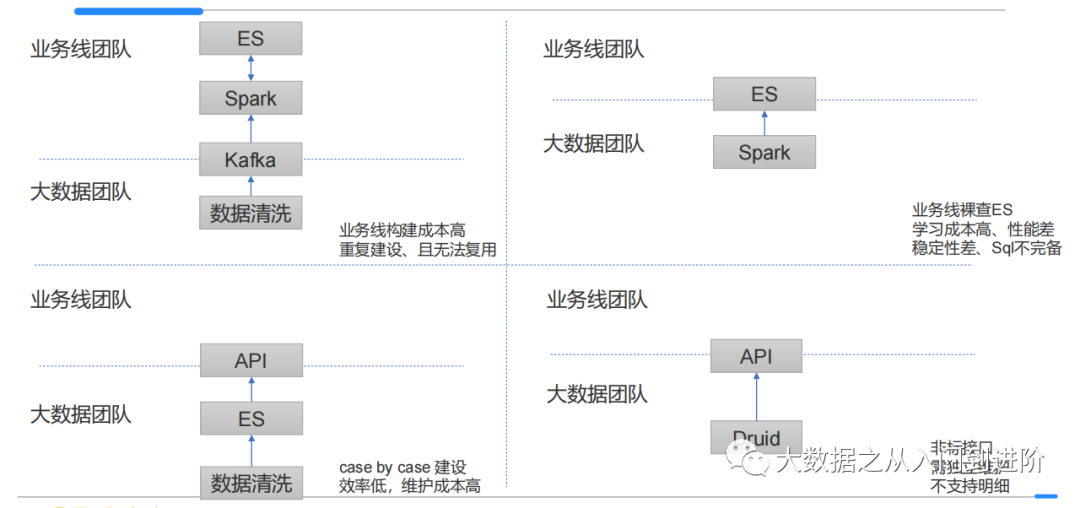
架构拆解:
非流量类:
Kafka:业务线从kafka接数据自己做数据的聚合计算,主要问题在于完全没有数仓的概念,业务线在做大量重复的建设
Spark + ES:每来一个业务需求,就构建一个Spark+ES集群(spark负责计算写入到ES,ES供业务层直接使用)。效率低、ES的接口以及内部原理学习成本高,对于业务线很难有这样的精力去做
ES + 自定义API。大数据将数据写入ES后,并case by case构建api。初步有了数仓的接口,但是接口不具备Sql的能力,只能基于需求case by case的构建,效率太低。
流量类(如pv、uv等):
由于数据量大,往往需要预聚合,引入druid
痛定思痛:
这些烟囱式的系统构建方式,导致系统越来越难以维护,且业务接入效率也逐步降低
统一整个查询引擎,对于数仓建设在提高业务支持效率、降低维护成本上都具有非常重大的意义
PS:如切如磋,如琢如磨,好的架构,总是建立在过去之上的。没有更好,只有更适合时下的业务场景,所以千万不要掉进惯性的陷阱
1.3、总体架构:
经过过去数月的探索与实践,团队确立了以Doris为基础的数仓实时查询系统。同时也对整个数仓的数据计算系统做了一次大的重构,最终整体的架构图如下:(划重点啦~)
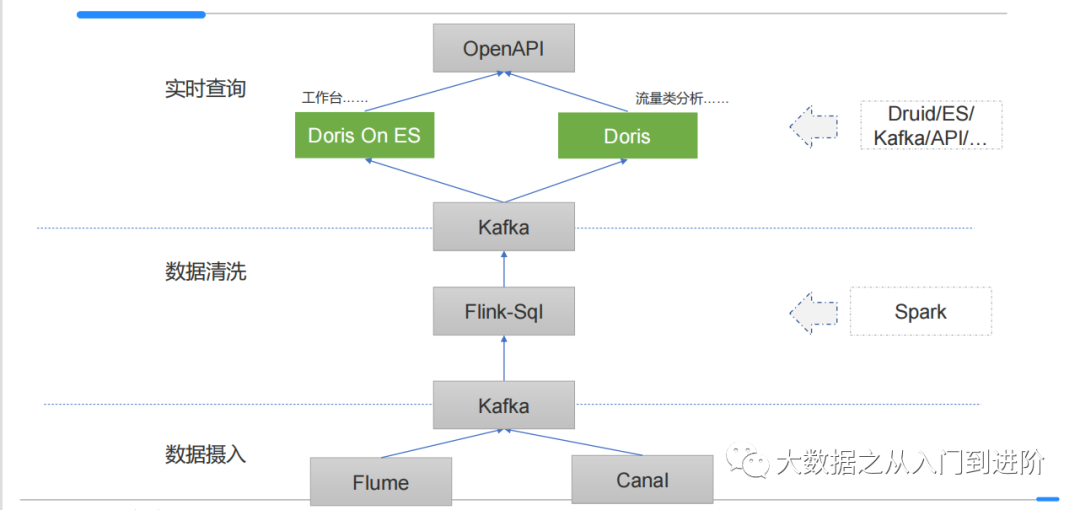
如图所示:
业务日志及实时数据通过采集工具落盘到kafka(ODS层)
经过Flink-SQL(将原来的spark替换掉)进行清洗、计算后,在将数据推回至kafka中(DW层)。且,使用SQL进行开发大大提升了效率
其后查询系统将Kafka的数据实时同步到查询引擎Doris(ADS层),并通过OpenAPI的统一接口对外提供查询服务
ps:经过这样层次清晰的梳理,现在是不是对实时数仓有了一定的认识了呢~
1.4、成效收益:
| 过去 | 现在 | 收益 |
| 技术选型:Spark/API/ES/…… 开发、联调…… | 基础数据写入Doris/ES 业务侧基于Sql进行查询 | 交付效率:数人周/月 -> 小时 |
| 裸用ES,千万级数据查询 十小时+ 前端基于Mysql做报表 | Doris/Doris on ES高性能查询 ES:十小时 -> 分钟级 | Doris:分钟级 -> 秒级 |
总结:
Doris 易运维(无第三方组件、Mysql接口)、社区支持度好
目前半年时间,7+业务线。近1T数据
0事故(>=P2)

二、基于Doris的实时查询系统
1、系统选型&原理
2、应用实践
2.1.1 业务场景:
BI、报表……
PV、UV……
日活
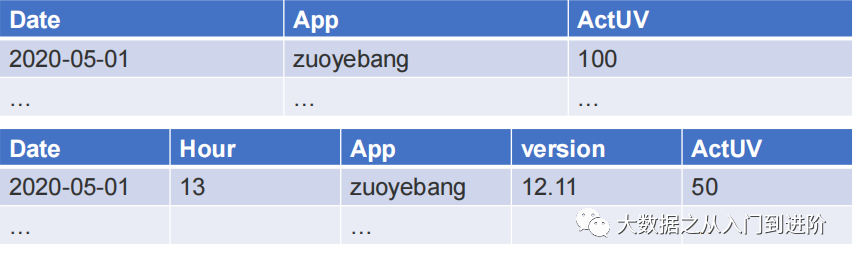
特点:明细、聚合
聚合:作业帮 主APP在某一天的活跃用户
明细:作业帮 主App各个小时段各个版本下的活跃用户
教研工作台

某节课内,各个老师的学生出勤数:
select teacher_id, count(student_id)
from attend_table
where lessonId=xxx and attend_time > 300
group by teacher_id
2.1.2 查询引擎调研:
实时查询系统的核心在于查询引擎,如何选型当然也成了其中很重要的内容。社区的查询引擎较多,如Impala、Presto、Doris、ES以及云上的ADB等。考虑到调研成本、团队技术生态、维护成本等多种因素,最后选择了Doris作为查询引擎。
调研结果:

经过性能、成本、生态及业务技术和业务现状,最终使用Doris onES。主要考虑点:
任意列检索。基于ES的倒排索引,我们可以对任意列进行检索(筛选)。这个模型大大降低了业务同学的学习理解成本,可以和mysql一样方便的构建数据模型
ES的易用性以及整个技术生态在公司内相对成熟的多,维护成本较低。如数据修改可以直接覆盖最新值,非常简单
Doris on ES在数据Scan上做了大量的优化操作,如列存、local优先、响应内容过滤、顺序扫描、提前终止等,对于数据的扫描性能可以达到~30w/
Doris 提供了更强大的Sql语法(如join、多列group by……),且整个查询过程保障了数据的准确度。大大提高了数据使用的效率和数据查询质量
当然,对于流量分析的场景,由于指标列一般是pv、uv等,业务上并没有对指标的筛选过滤需求,且Doris自身支持RollUP,因此非常适合流量类的查询分析。
因此,通过Doris我们统一了整个查询引擎端的实现,这样对于后续整个数仓的进一步建设就打下了非常重要的基础。
2.1.3 Doris简介:
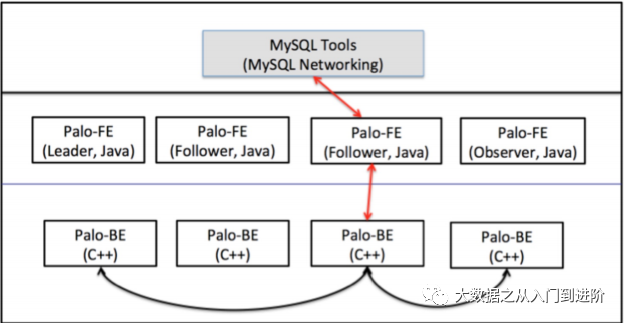
MPP架构的OLAP引擎
FE:解析、元数据;BE:执行、存储
同时支持高并发点查询和高吞吐的Ad-hoc查询
同时支持离线批量导入和实时数据导入
兼容MySQL协议和标准SQL
支持Rollup Table和Base Table的智能路由
支持Schema在线变更
丰富的数据模型(Aggre、Dup…)
2.1.4 Doris数据模型:
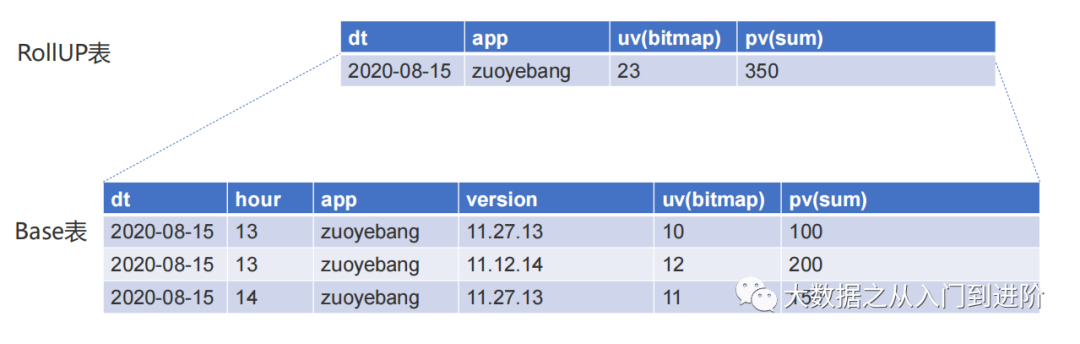
Aggregate模型
RollUP预聚合,提高查询性能
Doris on ES模型:
ES任意列检索

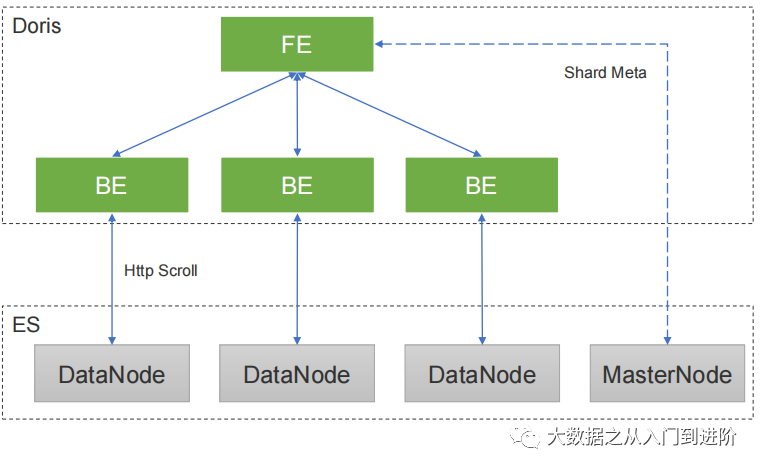
2.1.5 DoE高性能的设计:
Doris on ES总体架构
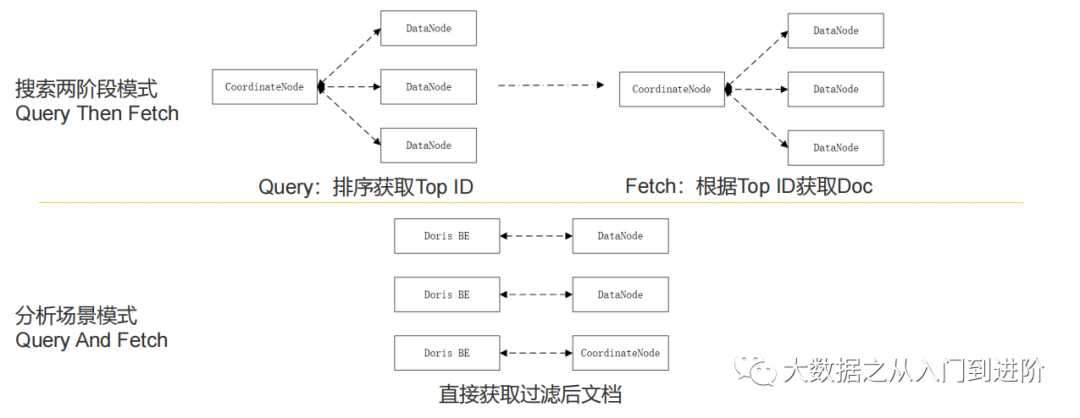
Doris on ES 比 裸访问ES快的原因
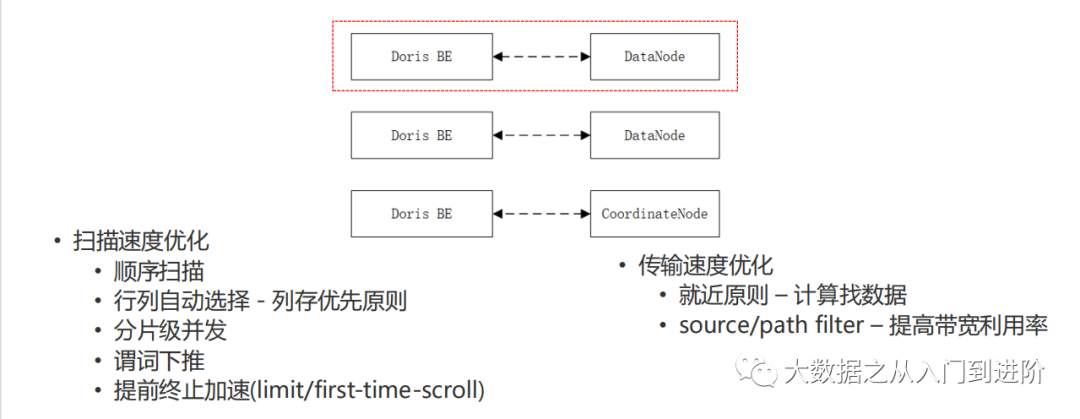
2.2.1 应用实践-架构设计:
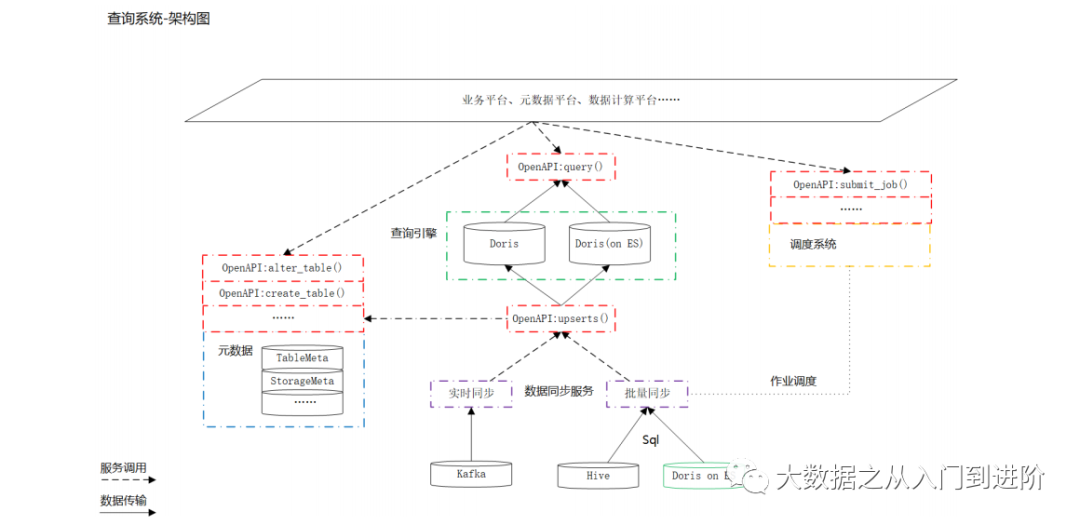
2.2.2 实践案例:
1. 元数据/表管理
元数据存在的必要性:
最优化性能保证
Doris on ES 列存尽力而为:需要保证ES index全部开启列存读取
查询性能稳定
ES与Doris类型不一致,会导致查询出错,keyword vs bigint
不一致字段Schema,会导致数据同步质量不可控
使用效率
ES建index、Doris建表需要配套
ES新增字段,Doris表重建
Doris建表、Rollup...
其他
Flink SQL强依赖元数据构建DDL
方案:
统一数据模型 <env, db, table -> Fields & Index & Storage>
Json-Schema 约束列值域
效果:
查询效率保障
100% 列存访问
查询稳定性
由于数据质量问题导致的异常:0 CASE
运维效率
平台化表管理:CreatTable/AlterTable/RollUP/…
提高系统自动化、稳定性的基础
Openapi/Flink……
2. 写操作
Upserts
表抽象为Env/DB/Table, 统一数据模型
JsonSchema 校验,保证数据质量
自动写入Meta字段,提高Debug能力
UpdateTime/IndexID/…
_version做版本控制,避免乱序覆盖
Monitor
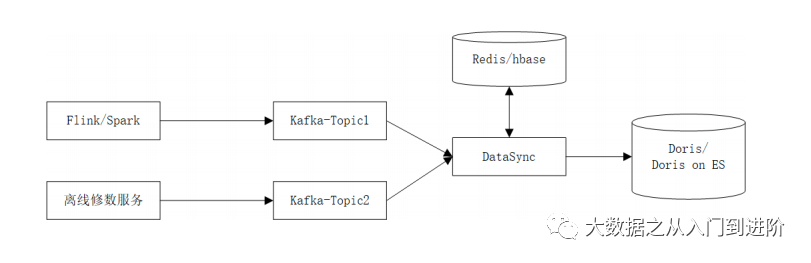
Upserts – 乱序流写入下的问题背景:
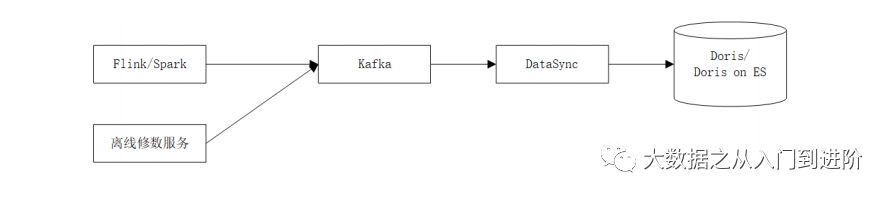
问题:
离线修数据和实时流写入同一个Table(ES index),导致乱序覆盖
修数数据规模大,避免乱序只能牺牲写入的时效性
解决:
修数流、实时流隔离,写入各自topic
数据同步服务基于topic限速消费
基于_id & field => _version,对字段级做版本管理
效果:
数据正确性&时效性得到兼顾
3. 读操作:
Query
Sql语义。业务方最大效率使用数据
Sql缓存,解决 F5刷新、系统Bug、重复Sql执行等场景的性能和稳定性问题
系统参数,如query_timeout……
某业务线上线后,访问doris规模下降90+%,TP99延迟下降40倍(16s->400ms),CPU IDLE 50% 提高到 95%
业务场景:
统计某个学部下(各个老师)的学生上课情况:上课人数…

微批模式调度:

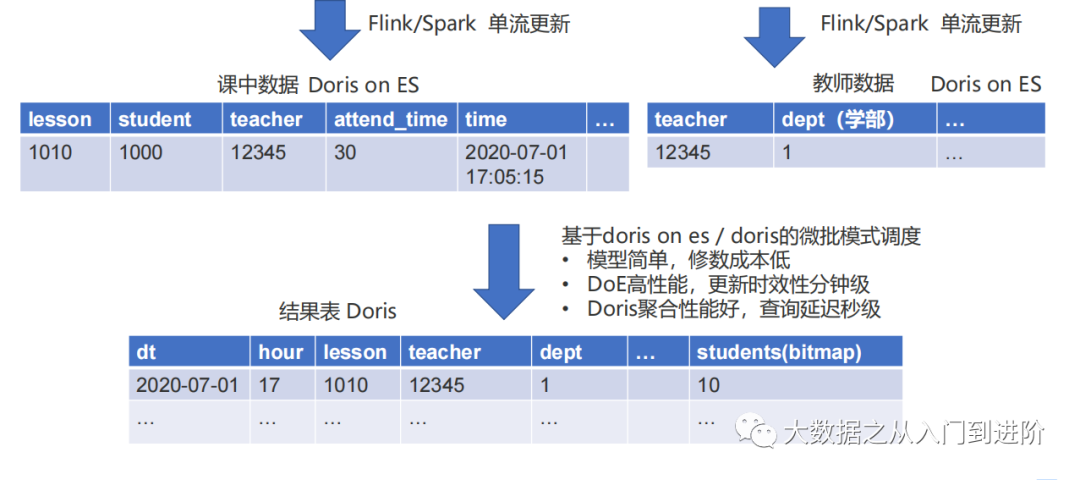
4. 其他实践:
ADS层表慎用join
DoE参数
ES扫描超时(默认5s):es_http_timeout_ms = 300000
batch_size = 4096 max: 30w/s
bitmap计算重
parallel_fragment_exec_instance_num: 5(分桶/机器)
运维
Supervisor
ulimit –c unlimited / …
master版本
bugfix及时
新feature引入:issue、case 回归、自动化沉淀、小流量……

三、未来规划
Doris on ES:
多表Join性能
表分区能力
Schema同步
更多的谓词下推: count…
......

写在最后:
关于实时数仓的技术架构,企业根据自己的业务场景都有着各种各样的不同。Doris也是目前我工作中涉及到的,作为学习和记录,并且站在巨人的肩膀上,对好的技术文章进行总结、归纳。
书山有路勤为径。所有成功人士的成功都不是一蹴而就的,希望兄弟们也一直保持着不断攀登的劲头儿,不断走向人生巅峰。
文章整理不易,希望兄弟们多支持。识别下方二维码,关注后,点击“资料获取”,即可获取免费学习资料,并且资料在不断更新中。记得关注、点赞、收藏哦~
往期推荐
基于阿里OneData思想,深入剖析数据仓库方法论
ClickHouse如何在字节跳动内部演化的
快手基于Flink构建实时数仓场景

点分享

点收藏

点点赞

点在看
这篇关于作业帮实时数仓架构中的Doris是如何发挥神威的,一文玩儿透(建议收藏)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





