本文主要是介绍HTK搭建大词汇量连续语音识别系统(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接着昨天的做。昨天有个没注意的地方需要改过来,timit发音文件每个发音最后不能有sp,否则dict1会有两个sp。
六、提取特征参数,生成.mfc文件
编写配置文件wav_config,内容如下:
SOURCEFORMAT=NIST
TARGETKIND=MFCC_0_D_A
TARGETRATE=100000.0
SAVECOMPRESSED=T
USEHAMMING=T
WINDOWSIZE=250000.0
SAVEWITHCRC=T
PREEMCOEF=0.97
NUMCHANS=26
CEPLIFTER=22
NUMCEPS=12
使用python编写生成.mfc文件的路径文件codetrain.scp,如下:
data/train/dr1/fcjf0/Untitled/sa1.wav data/train/dr1/fcjf0/Untitled/sa1.mfc
data/train/dr1/fcjf0/Untitled/sa2.wav data/train/dr1/fcjf0/Untitled/sa2.mfc
data/train/dr1/fcjf0/Untitled/si1027.wav data/train/dr1/fcjf0/Untitled/si1027.mfc
data/train/dr1/fcjf0/Untitled/si1657.wav data/train/dr1/fcjf0/Untitled/si1657.mfc
data/train/dr1/fcjf0/Untitled/si648.wav data/train/dr1/fcjf0/Untitled/si648.mfc
data/train/dr1/fcjf0/Untitled/sx127.wav data/train/dr1/fcjf0/Untitled/sx127.mfc
data/train/dr1/fcjf0/Untitled/sx217.wav data/train/dr1/fcjf0/Untitled/sx217.mfc
data/train/dr1/fcjf0/Untitled/sx307.wav data/train/dr1/fcjf0/Untitled/sx307.mfc
data/train/dr1/fcjf0/Untitled/sx37.wav data/train/dr1/fcjf0/Untitled/sx37.mfc
执行命令:
HCopy –T 1 –C def/wav_config –S def/codetrain.scp
在目录data/train/dr1/fcjf0/Untitled/下就生成了对应的mfc文件
七、定义模型,生成文件:hmms/hmm0/protov,hmms/hmm0/vFloors
先定义一个一个原始的HMM模型文件proto,放在主目录,不能放在新生成proto的目录,内容如下:
~o <VecSize> 39 <MFCC_0_D_A>
~h "proto"
<BeginHMM>
<NumStates> 5
<State> 2
<Mean> 39
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 39
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<State> 3
<Mean> 39
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 39
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<State> 4
<Mean> 39
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<Variance> 39
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<TransP> 5
0.0 1.0 0.0 0.0 0.0
0.0 0.6 0.4 0.0 0.0
0.0 0.0 0.6 0.4 0.0
0.0 0.0 0.0 0.7 0.3
0.0 0.0 0.0 0.0 0.0
<EndHMM>
然后编写新的配置文件config,内容如下:
#SOURCEFORMAT=NIST
TARGETKIND=MFCC_0_D_A
TARGETRATE=100000.0
SAVECOMPRESSED=T
USEHAMMING=T
WINDOWSIZE=250000.0
SAVEWITHCRC=T
PREEMCOEF=0.97
NUMCHANS=26
CEPLIFTER=22
NUMCEPS=12
ENORMALISE=F
这里和wav_config文件唯一的区别是没有了SOURCEFORMAT=NIST这句。
执行命令:
HCompV -C def/config -f 0.01 -m -S def/train.scp -M hmms/hmm0 proto
在hmms/hmm0中生成新的proto文件和一个vFloors文件
新建全局宏文件macros,内容是把vFloors文件复制过来,在头上加:
~o
<VECSIZE> 39 <MFCC_0_D_A>
然后在hmm0文件夹中新建主宏文件hmmdefs,内容为把新生成的proto文件内容复制进来,复制data /monophone1为data /monophone0,并去掉“sp”,并把~h “proto”替换成data /monophone0文件中的所有音素,并在hmms新建hmm1,hmm2,hmm3。执行命令进行模型重估:
HERest –A –D –T 1 –C def/config –I labels/phones0.mlf –t 250.0 150.0 1000.0 –S def/train.scp –H hmms/hmm0/macros –H hmms/hmm0/hmmdefs –M hmms/hmm1 data/monophones0
重复执行三次,最终结果有两个文件hmmsdef和macros放在hmm3下,执行界面如下。

八、绑定静音
将hmm3中的hmmdefs文件的”sil”模型复制,并改为“sp”,然后把新的hmmdefs跟macros一起放在hmm4文件夹中。执行命令:
HHEd –A –D –T 1 –H hmms/hmm3/macros –H hmms/hmm4/hmmdefs –M hmms/hmm5 scripts/sil.hed data/monophones1
其中sil.hed内容如下:
AT 2 4 0.2 {sil.transP}
AT 4 2 0.2 {sil.transP}
AT 1 3 0.3 {sp.transP}
TI silst {sil.state[3],sp.state[2]}
执行界面如下:

使用HERest重估两次,生成文件存放在hmm7中
九、重新校正训练数据
使用命令:
HVite –A –D –T 1 ‘*’ –o SWT –b SILEN –C def/config –H hmms/hmm7/macros –H hmms/hmm7/hmmdefs –I aligned.mlf –m –t 250.0 150.0 1000.0 –y lab –a –I labels/trainwords.mlf –S def/train.scp dict/dict2 data/monophones1
其中dict2是SILEN sil加入发音字典dict1后的新发音字典,aligned.mlf是生成的新的音素级标音文件。
然后使用HERest重估两次,放在hmm9中,其中,用aligned.mlf代替phones0.mlf,命令:
HERest –A –D –T 1 –C def/config –I labels/aligned.mlf –t 250.0 150.0 1000.0 –S def/train.scp –H hmms/hmm7/macros –H hmms/hmm7/hmmdefs –M hmms/hmm8 data/monophones1
注意:生成的aligned.mlf文件中需要把路径的”’*’”替换成”*”(如果有这个单引号的话),还有就是sp sp不能连一块出现。
当然,根据《应用HTK搭建语音拨号系统》提到,到这里就可以进行识别率的测试了。首先需要建立gram任务语法,并生成wdnet任务网络语法,命令不详述了。其次在test目录下生成.mfc文件方法同train下生成.mfc,并制作mfcc路径文件test.scp,使用命令进行测试:
HVite –H hmms/hmm9/macros –H hmms/hmm9/hmmdefs –S test/test.scp -l * -i results/recout_hmm9.mlf –w dict/wdnet –p 0.0 –s 5.0 dict/dict2 data/monophones1由于timit数据量较大,生成recout_hmm9.mlf的过程可能会持续两小时左右。
生成的recout_hmm9.mlf格式如下:
#!MLF!#
"*/sa1.rec"
0 5800000 SILEN -4256.611816
5800000 8100000 SHE -1795.725220
8100000 10700000 HAD -2194.983154
10700000 12400000 ADD -1555.612183
12400000 14900000 ARC -2140.485596
14900000 18100000 SOON -2659.971924
18100000 19600000 IN -1301.001099
19600000 21900000 AGREE -2065.449951
21900000 24000000 SEE -1762.183838
24000000 28200000 WASH -3261.522949
28200000 32200000 WATER -3161.133789
32200000 34300000 ALL -1702.356079
34300000 38000000 YOUR -2794.063232
38000000 39500000 SILEN -1017.923950
.
"*/sa2.rec"
0 7900000 SILEN -5215.187500
7900000 9800000 BONE -1653.495239
然后执行命令:
HResult -I test/testwords.mlf data/monophones1 test/recout_hmm9.mlf
其中testwords.mlf用prompts2mlf脚本得到,命令:
perl scripts/prompts2mlf test/testwords.mlf test/testprompts
其中testprompts与trainprompts方法相同,只是不用全路径,格式如下:sa1 SHE HAD YOUR DARK SUIT IN GREASY WASH WATER ALL YEAR
sa2 DON'T ASK ME TO CARRY AN OILY RAG LIKE THAT
si1573 HIS CAPTAIN WAS THIN AND HAGGARD AND HIS BEAUTIFUL BOOTS WERE WORN AND SHABBY
si2203 THE REASONS FOR THIS DIVE SEEMED FOOLISH NOW
si943 PRODUCTION MAY FALL FAR BELOW EXPECTATIONS
而之前的trainprompts的格式是这样的:
data/train/dr1/fcjf0/Untitled/sa1 SHE HAD YOUR DARK SUIT IN GREASY WASH WATER ALL YEAR
data/train/dr1/fcjf0/Untitled/sa2 DON'T ASK ME TO CARRY AN OILY RAG LIKE THAT
data/train/dr1/fcjf0/Untitled/si1027 EVEN THEN IF SHE TOOK ONE STEP FORWARD HE COULD CATCH HER
data/train/dr1/fcjf0/Untitled/si1657 OR BORROW SOME MONEY FROM SOMEONE AND GO HOME BY BUS
data/train/dr1/fcjf0/Untitled/si648 A SAILBOAT MAY HAVE A BONE IN HER TEETH ONE MINUTE AND LIE BECALMED THE NEXT
对比一目了然。
第一次的测评结果如下:
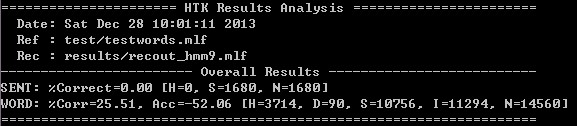
但貌似识别率很低的样子,而且出现了负数,肯定有问题。
明天继续。。。
这篇关于HTK搭建大词汇量连续语音识别系统(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









