本文主要是介绍语音论文阅读:U2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition
摘要
提出一种双路方法将流式和非流式端到端语音识别模型统一到一个模型中,模型采用混合CTC/attention架构,其中encoder中的conformer结构被修改。提出了一种基于动态的块的注意力策略,以允许任意右上下文长度。在推理时间,CTC解码器以流式方式生成n最佳假设。只能通过更改块大小来容易地控制推理延迟。然后通过注意解码器来重新筛选CTC假设以获得最终结果。这种有效的备用过程导致句子级延迟非常小。在aishell-1上进行测试,本文提出的U2模型相对于非流式模型降低5.60%的相对字错率。同时在较低延迟下,CER可以降低为5.42%。
引言
介绍了端到端的发展,优势,以及目前主流的端到端ASR系统(CTC,RNN-T,AED),不同类型的模型有着不同的应用场景,优势不同,有些工作对比了这三种模型,有些工作将三种模型集成到一个模型中[1,2,3]。
介绍了流式RNNT模型通过一些策略达到与LAS相媲美的精度,以及介绍了AED模型一些进行流式识别的操作(MoCha),最近,将流式和非流式统一到一个模型的研究越来越火热。U2模型不仅降低了流模型和无流模型之间的精度差距,还可以减轻模型开发,培训和部署的负担
相关工作
Two pass解码最先在RNN-T模型中应用,但RNN-T模型难以训练,非常占用内存,以及不稳定,一些改善的变种模型(联合CTC训练,CE,以及加入LAS loss)比较复杂。对于统一无流和流式媒体模型,Y模型在培训时使用可变上下文,并且可以在推理时使用若干可选的上下文。但是,可选的上下文在训练阶段预定义,并且在编码器层的数量方面仔细设计了上下文,Dual-model仅在训练和推理中只有一个流配置,如果我们希望在推理的推断下具有不同延迟的另一流模型,则需要完全再培训模型。此外,y模型和Dual-model是基于RNN-T的模型,它们具有与RNN-T相同的缺点,针对上面的一些工作,本文提出U2,是CTC和基于AED的联合模型,通过组合CTC和AED损失和动态块的关注,不仅统一无流化和流媒体模型,给出了有希望的结果,也大大简化了训练管道,也是如此随着动态控制流媒体应用中的延迟与准确性之间的权衡。
模型结构
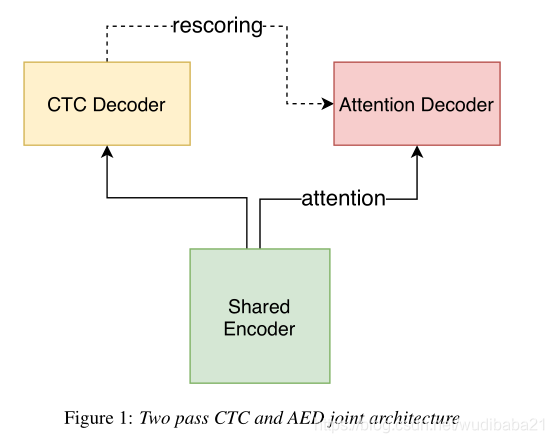
其中Encoder部分可选Transformer或者Conformer,限制Encoder只能看到有限的未来信息,CTC-Decoder以一种流式的方式运行,为The first pass。Two pass输出为CTC和attention的联合输出。
使用CTC/attention联合损失函数。
提出了一种动态块训练技术,统一无流化和流式模型并启用延迟控制。
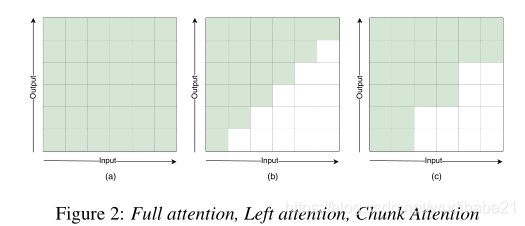
(a)为使用全部的注意力,不能进行流式识别,(b)为只看时间t的输入以及之前的输入或者每层看有限个未来信息,假设有N个encoder层,每层看W个右边信息,则一共所看右边信息为N*W,看到未来部分信息相比只看过去信息效果更好。但这在confomer结构中有些困难,(c)为本文工作,使用动态的截断未来信息。我们有输入[t + 1,t + 2,...,t + c],每个块都取决于自身和所有之前的块。然后编码器的整个延迟取决于块大小,易于控制和实现。我们可以使用固定的块大小培训模型,我们称之为静态块训练,并用同一个块解码。我们称大小为1到25的块作为流块,用于流式模型和尺寸,最大话语长度为无流块,无用于无流模型。然而,这种方法的结果不够好,所以接下来我们在培训过程中改变块大小的分布如下。
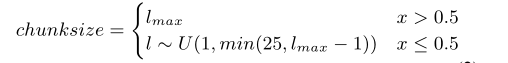
Conformer中的卷积单元考虑左上和右上下文。总正确上下文取决于卷积层的上下文和堆叠数量的符合者层。因此,这种结构不仅带来了额外的延迟,而且还破坏了基于块的关注的好处,延迟是在网络结构上独立的,并且可以刚刚在推理时间的块控制。为了克服这个问题,我们使用因果卷积。
解码
CTC的输出作为流式方式输出
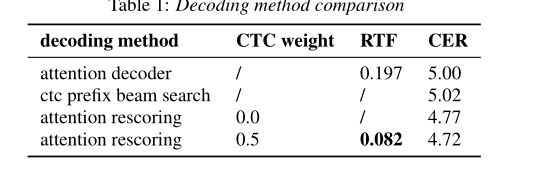
另外:使用Attention Decoder 和Rescoring mode 作为最后输出方式
Rescoring mode使用CTC 的输出优化Attention的输出。
实验
Aishell-1数据集
80Fbank,应用变速,时域频域掩盖等增强技术
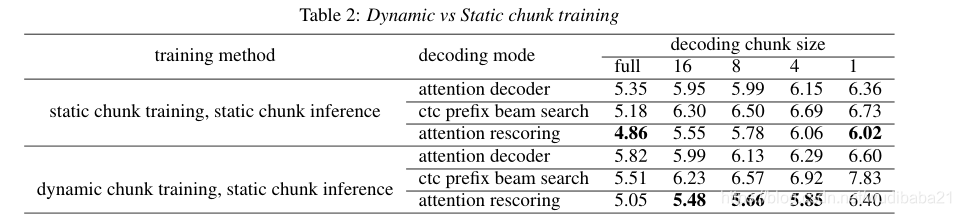

参考文献
1.R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A comparison of sequence-to-sequence models for speech recognition
2.S. Kim, T. Hori, and S. Watanabe, “Joint ctc-attention based end-to-end speech recognition using multi-task learning,” in 2017 IEEE international conference on acoustics, speech and signal
processing (ICASSP). IEEE, 2017, pp. 4835–4839.
3.T. N. Sainath, R. Pang, D. Rybach, Y . He, R. Prabhavalkar, W. Li,
M. Visontai, Q. Liang, T. Strohman, Y . Wu et al., “Two-pass end-
to-end speech recognition,” arXiv preprint arXiv:1908.10992,
2019
这篇关于语音论文阅读:U2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






