本文主要是介绍[统计学笔记] (六) 参数估计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(六)参数估计 (Parameter Estimation)
参数估计是推断统计的重要内容之一。它是在抽样及抽样分布的基础上,根据样本统计量来推断所关心的总体参数。
人们常常需要根据手中的数据,分析或推断数据反映的本质规律。即根据样本数据如何选择统计量去推断总体的分布或数字特征等。统计推断是数理统计研究的核心问题。所谓统计推断是指根据样本对总体分布或分布的数字特征等作出合理的推断。它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。
参数估计(Parameter Estimation),统计推断的一种。根据从总体中抽取的随机样本来估计总体分布中未知参数的过程。例如:用样本平均值估计总体均值
,用样本比例
估计总体比例
,用样本方差
估计总体方差
,等等。
从估计形式看,区分为点估计与区间估计:从构造估计量的方法讲,有矩法估计、最小二乘估计、似然估计、贝叶斯估计等。
参数估计有多种方法,有矩估计、极大似然法、一致最小方差无偏估计、最小风险估计、同变估计、最小二乘法、贝叶斯估计、极大验后法、最小风险法和极小化极大熵法等。最基本的方法是最小二乘法和极大似然法。
要处理两个问题:(1)求出未知参数的估计量;(2)在一定信度(可靠程度)下指出所求的估计量的精度。信度一般用概率表示,如可信程度为95%;精度用估计量与被估参数(或待估参数)之间的接近程度或误差来度量。
主要分类
点估计
点估计(Point Estimate)是用样本统计量的某个取值直接作为总体参数的估计值。例如,用样本均值x直接作为总体均值μ的估计值,用样本方差直接作为总体方差
的估计值。点估计的方法有:矩估计法、顺序统计量法、最大似然法、最小二乘法。
点估计是以抽样得到的样本指标作为总体指标的估计量,并以样本指标的实际值直接作为总体未知参数的估计值的一种推断方法。通常它们是总体的某个特征值,如数学期望、方差和相关系数等。
点估计问题就是要构造一个只依赖于样本的量,作为未知参数或未知参数的函数的估计值。例如,设一批产品的废品率为。为估计
,从这批产品中随机地抽出n个作检查,以X记其中的废品个数,用X/n估计θ,这就是一个点估计。
构造点估计常用的方法是:
① 矩估计法。用样本矩估计总体矩,从而得到总体分布中参数的一种估计。它的思想实质是用样本的经验分布和样本矩去替换总体的分布和总体矩。矩估计法的优点是简单易行, 并不需要事先知道总体是什么分布。缺点是,当总体类型已知时,没有充分利用分布提供的信息。一般场合下,矩估计量不具有唯一性。
矩是指以期望为基础而定义的数字特征,一般分为原点矩和中心矩。设X为随机变量,对任意正整数k,称E(Xk)为随机变量X的k阶原点矩,记为:
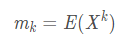
当k=1时,m1=E(X)=μ,可见一阶原点矩为随机变量X的数学期望。
把Ck=E[X-E(X)]k称为以E(X)为中心的k阶中心矩。显然,当k=2时,C2=E[X-E(x)]2=σ2,可见二阶中心矩为随机变量X的方差。
②最大似然估计法(Maximum Likelihood)。于1912年由英国统计学家R.A.费希尔提出,利用样本分布密度构造似然函数来求出参数的最大似然估计。它用来求一个样本集的相关概率密度函数的参数。
③最小二乘法(generalized least squares)。主要用于线性统计模型中的参数估计问题。最小二乘法是一种数学优化技术,它通过最小化误差的平方和找到一组数据的最佳函数匹配。 最小二乘法是用最简的方法求得一些绝对不可知的真值,而令误差平方之和为最小。 最小二乘法通常用于曲线拟合。很多其他的优化问题也可通过最小化能量或最大化熵用最小二乘形式表达。
④贝叶斯估计法。基于贝叶斯学派(见贝叶斯统计)的观点而提出的估计法。可以用来估计未知参数的估计量很多,于是产生了怎样选择一个优良估计量的问题。首先必须对优良性定出准则,这种准则是不唯一的,可以根据实际问题和理论研究的方便进行选择。优良性准则有两大类:一类是小样本准则,即在样本大小固定时的优良性准则;另一类是大样本准则,即在样本大小趋于无穷时的优良性准则。最重要的小样本优良性准则是无偏性及与此相关的一致最小方差无偏估计,其次有容许性准则,最小化最大准则,最优同变准则等。大样本优良性准则有相合性、最优渐近正态估计和渐近有效估计等 。
区间估计
区间估计(Interval Estimation)是依据抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,作为总体分布的未知参数或参数的函数的真值所在范围的估计。例如人们常说的有百分之多少的把握保证某值在某个范围内,即是区间估计的最简单的应用。1934年统计学家 J.奈曼创立了一种严格的区间估计理论。
区间估计示意图

可以求出样本均值落在总体均值
的两侧任何一个抽样标准差范围内的概率。但是实际估计时,情况恰恰相反。
是已知的,而
是未知的,也正是要估计的。由于
与
的距离是对称的,如果某个样本的平均值落在
的两个标准差范围之内,反过来,
也就被包括在以
为中心左右两个标准差的范围内。因此约有95%的样本均值所构造的两个标准差的区间会包括
。
通俗地说,如果抽取100个样本来估计总体的均值,由100个样本所构造的100个区间中,约有95个区间包含总体均值,另外5个区间则不包含总体均值。
区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量。
区间估计中,由样本统计量所构造的总体参数的估计区间称为置信区间(Confidence Interval),其中区间的最小值称为置信下限,最大值称为置信上限。
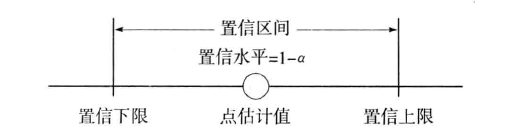
如果将构造置信区间的步骤重复多次,置信区间中包含总体参数真值的次数所占的比例称为置信水平(Confidence Level),也称为置信度或置信系数(Confidence Coefficient)。
在构造置信区间时,可以用所希望的任意值作为置信水平。比较常用的置信水平及正态分布曲线下右侧面积为时的
值(
),如下表所示:
| 置信水平 | |||
|---|---|---|---|
| 90% | 0.10 | 0.05 | 1.645 |
| 95% | 0.05 |
这篇关于[统计学笔记] (六) 参数估计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








