本文主要是介绍论文阅读-USSA: A Unified Table Filling Scheme for Structured Sentiment Analysis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文来自2023ACL,原文:
https://aclanthology.org/2023.acl-long.802/
contribution:(来自原文)
1.提出了一种双词法依赖解析图,并将其转换为统一的二维表格填充方案USSA,解决了SSA中重叠和不连续的核心问题。
2.提出了一个有效的模型,与USSA方案很好地合作,利用提出的双轴注意模块,以更好地捕捉表中关系的相关性。
我的关注点:
1.Table Filling Scheme
word-pair之间的关系被分成了两大类13种,
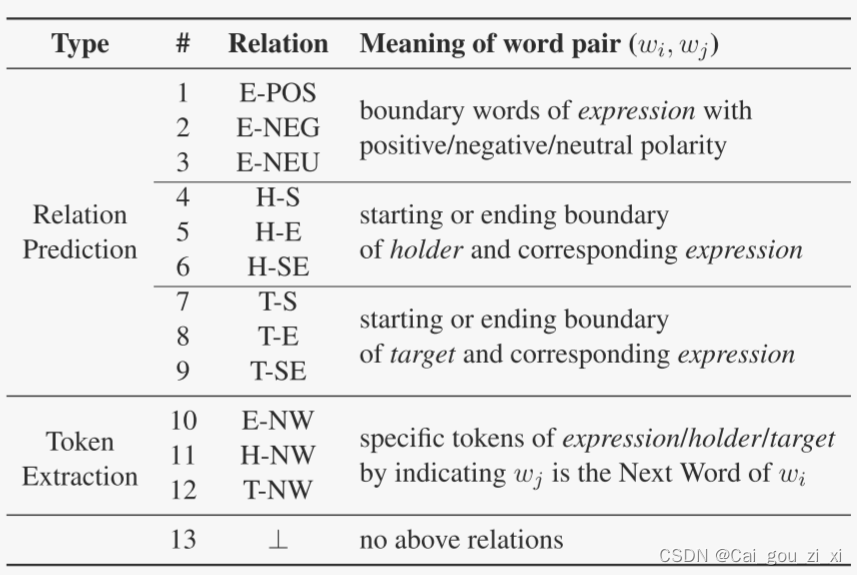
表格分成了上三角和下三角,上三角表示Token Extraction(TE),下三角表示Relation Prediction(RP)。
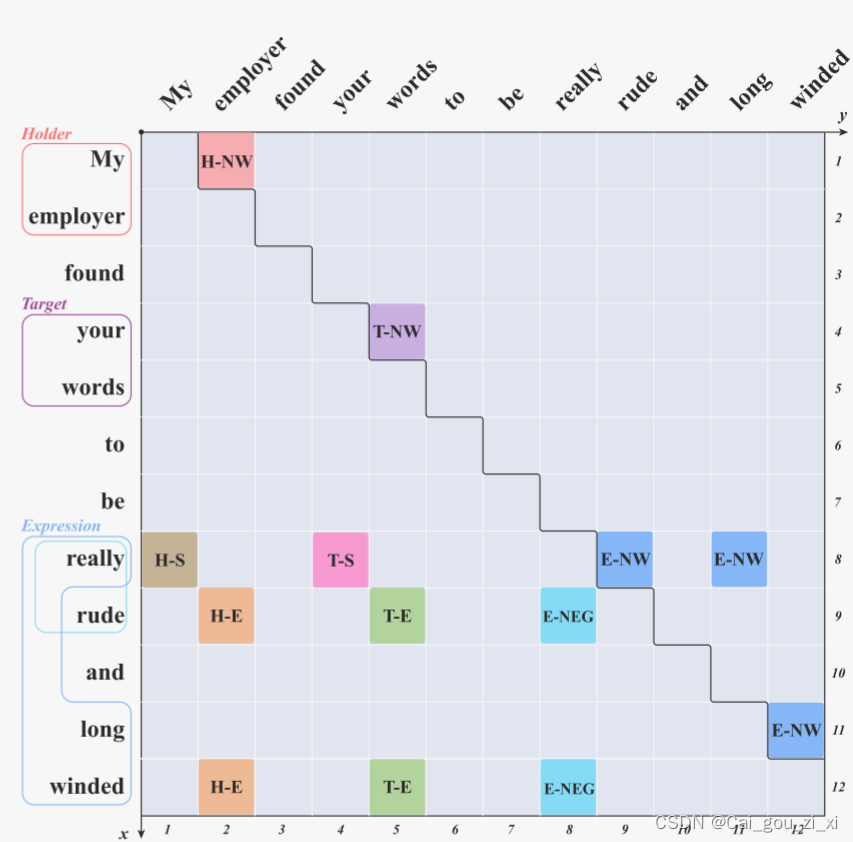
之前看到ASTE中,很多都使用对称的GTS,或者GTS的衍生。但是,在本文中,上三角表示的是完整的holder, target和expression,即Relation Prediction(RP)。下三角表示的是holder和target分别对应着哪个expression,并表示出了expression代表的是什么情感。
思考:若是远距离的否定句,是否可行呢?
2.Word-pair Representation Layer
利用Conditional Layer Normalization(CLN)表示word-pair,

3.Bi-Axial Attention Module
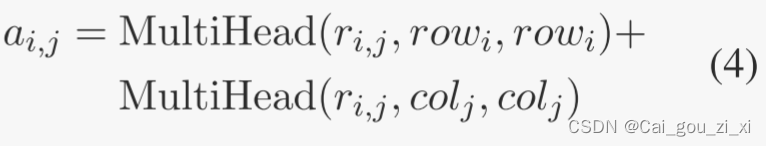
![]()
关于轴向注意力(axial attention) :
Axial Attention 和 Criss-Cross Attention及其代码实现-CSDN博客
这篇关于论文阅读-USSA: A Unified Table Filling Scheme for Structured Sentiment Analysis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)