本文主要是介绍白话空间统计番外五:美国大选中的数据科学,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2018年3⽉, 全球最⼤的社交⽹站Facebook被曝出负⾯新闻:⼀个名不见经传的⼩公司, 通过不正当的⼿段, 在Facebook⽹站上获取了8700万⽤户的数据。 这些数据随后被⽤于多个国家选举中的选民分析, 2016年当选的美国总统特朗普就曾经雇⽤这家公司, 这引发了关于数据操纵选举的批评, 直逼特朗普当选的合法性, 触⽬惊⼼。——此处引用自涂子沛《数文明》
实际上在政治活动中使用数据科学,已经不是什么新闻了,今天我们一起来看看在美国大选中数据科学的各种应用。

民主和共和这两个词,从来就是一起出现了,但是很多人都不明白这两个词到底指的是什么,当然,如果涉及到内涵啊,理论啊啥的,汗牛充栋,但是最简单的来说就是:
民主:少数服从多数
共和:权力公有

当然,二者都有很多道理和利弊,特别现在大家最热议的民主,很多人直接就把民主等同与“选举”,还一口一个起源古希腊……
但是,这里要打脸了……因为古希腊认为,选举是一个最不公平的方法——所谓的公平,指的是所有人的机会都均等,但是不管你怎么投票,有人永远不会获得当选的机会……那么古希腊用的是什么方法来保证绝对公平呢?答案是——抽签……

因为只有抽签才能保证,每个人当选的机会,是完全均等的……
这里有人可能说,虾神你瞎编吧,哪有这种事?这个真不是我编的,大家有兴趣去看清华大学王绍光教授的著作:《抽签与民主、共和:从雅典到威尼斯》(中信出版社是不是应该给我点广告费?)

抽签,如果不作弊,从概率学上来说,可以达到机会的完全均等……这尼玛才是真正的公平啊……如果我们也采用这种公平的方法,是不是表示虾神也有可能成为第N代core呢(想想都好激动)?

好吧,这样的公平,能够带来什么呢?大家可以自己思考一下……用数学语言来说:局部最优不会表示全局最优。
好了,题外话说道这里,下面还是回到我们美国大选。
美国的政治制度确立于1787年的立宪会议,当时独立的13个州,分别提出了两种方案,如下:
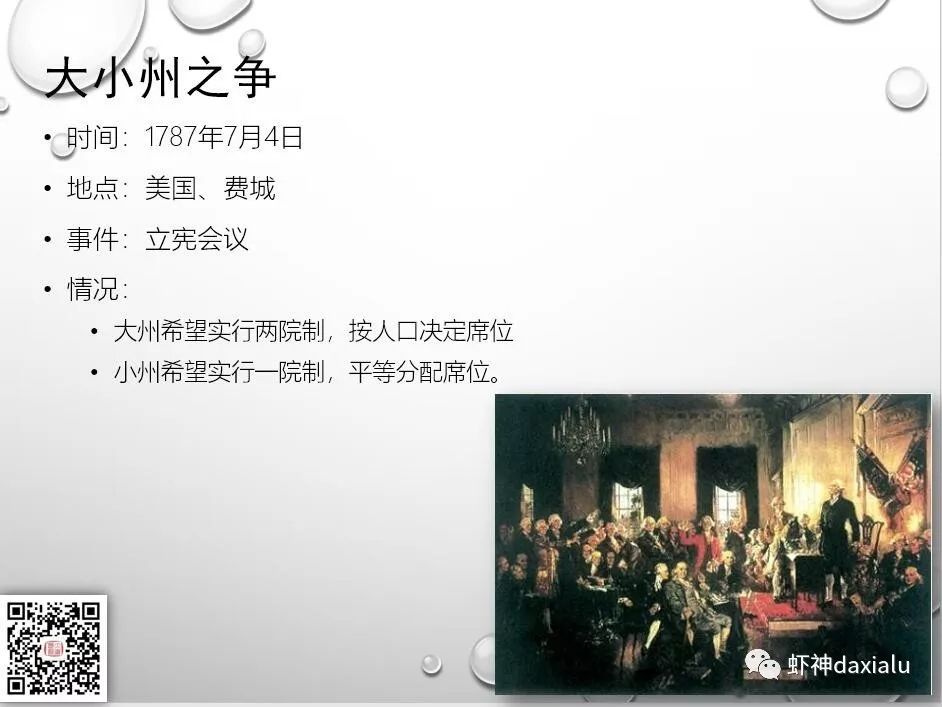
大州希望人口决定席位,这样的话,大州就有绝对的话语权,而小州希望平均分配,所有的希望州的选票都一样……
然后自然就是和平友好的交流:

最后完成了伟大的妥协:

参议院平均分配,大家一样,众议院按人口分……任何法律都必须两院同时通过才有效。
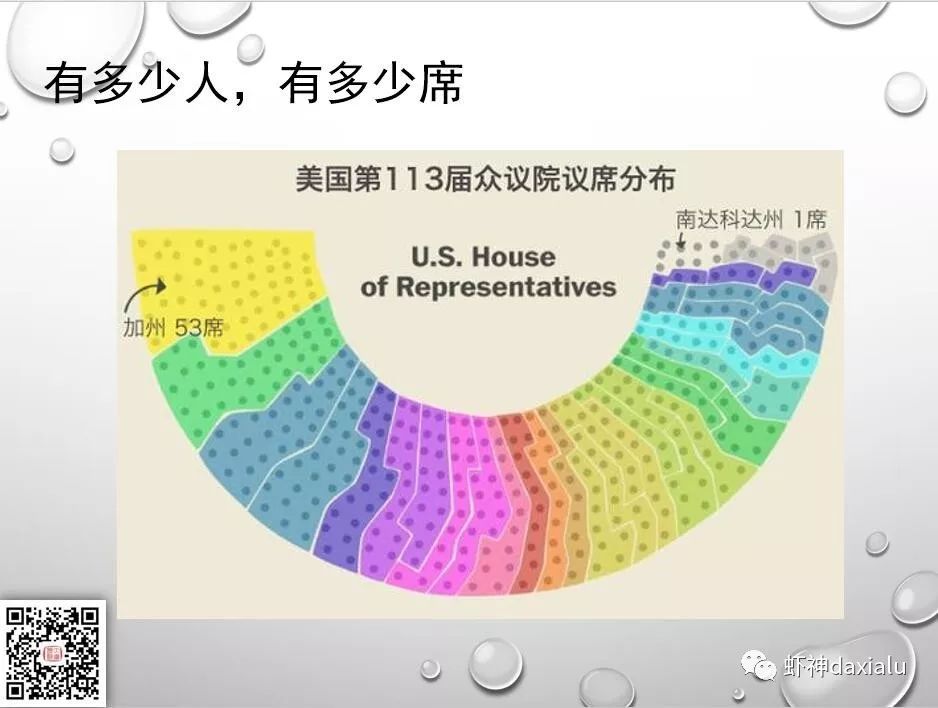
那么在大选中,是不是我们说以为的一人一票选总统呢?实际上这是对美国选举制度的误解,美国实现的是选区制度,如下所示:

那么选区的划分就非常的有意思了,看看下面这个案例:
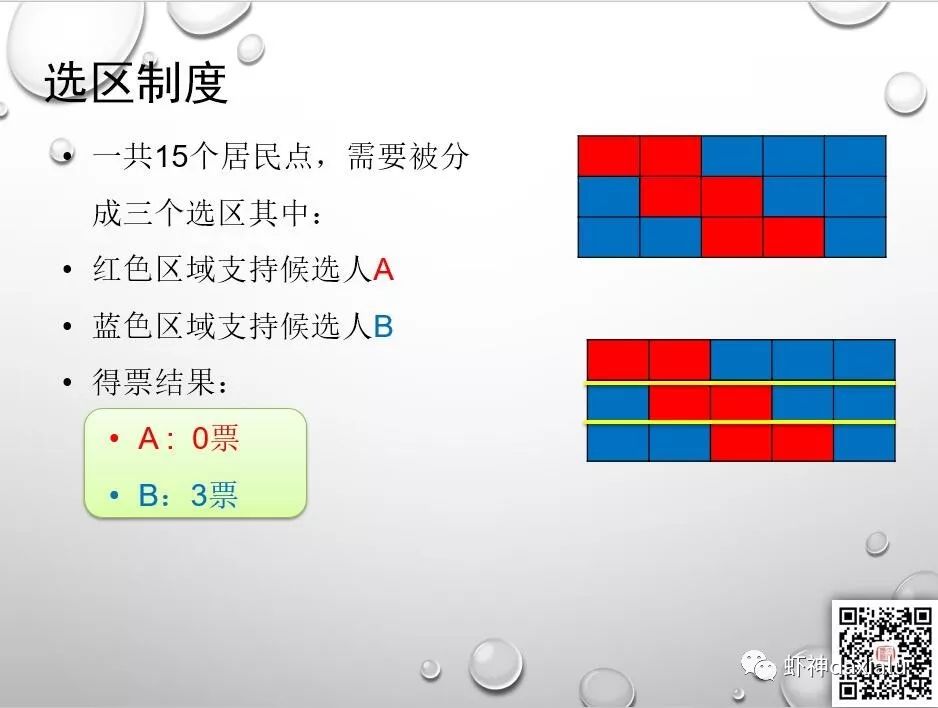
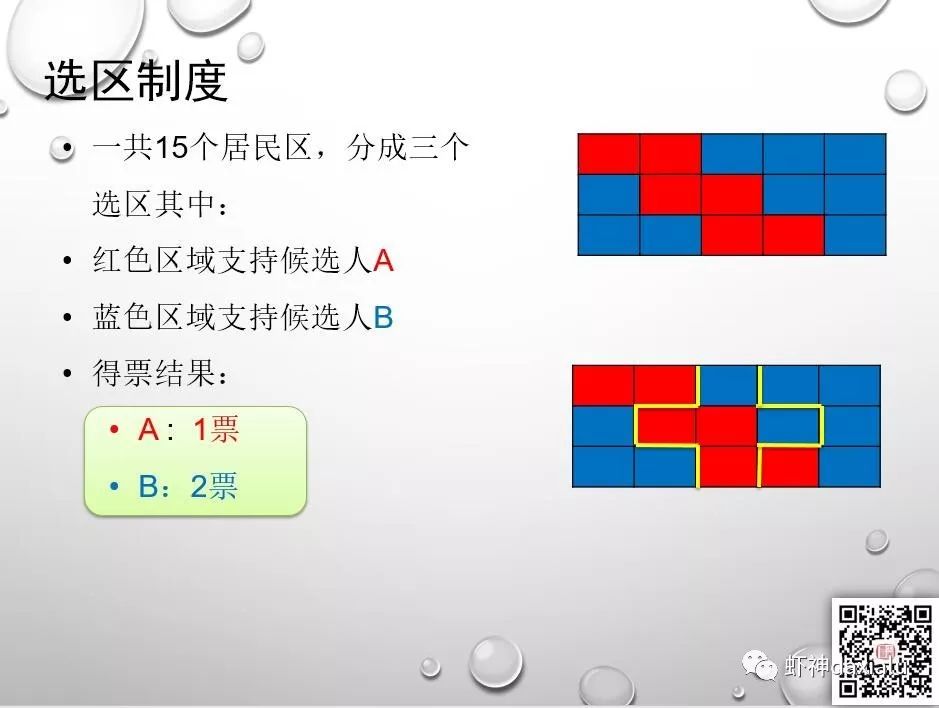
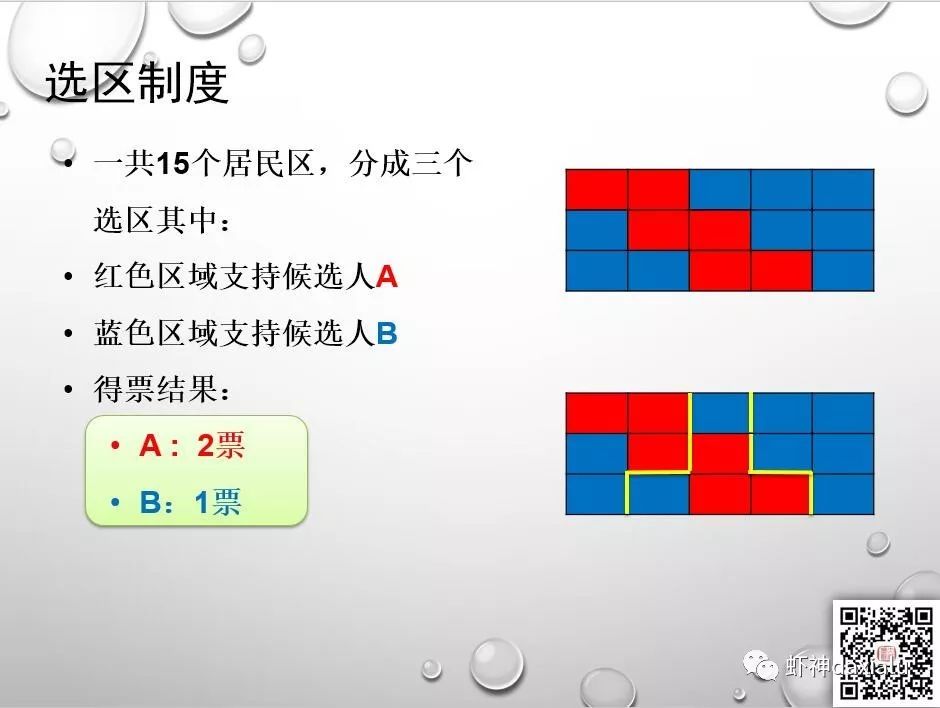
以上三种划分方法,可以在人数完全不变的情况下,得到三种完全不同的结果,可以看出,选区划分是一个非常重要的权力,那么有同学会问,真的可以像图三如此任性么?答案是:yes。
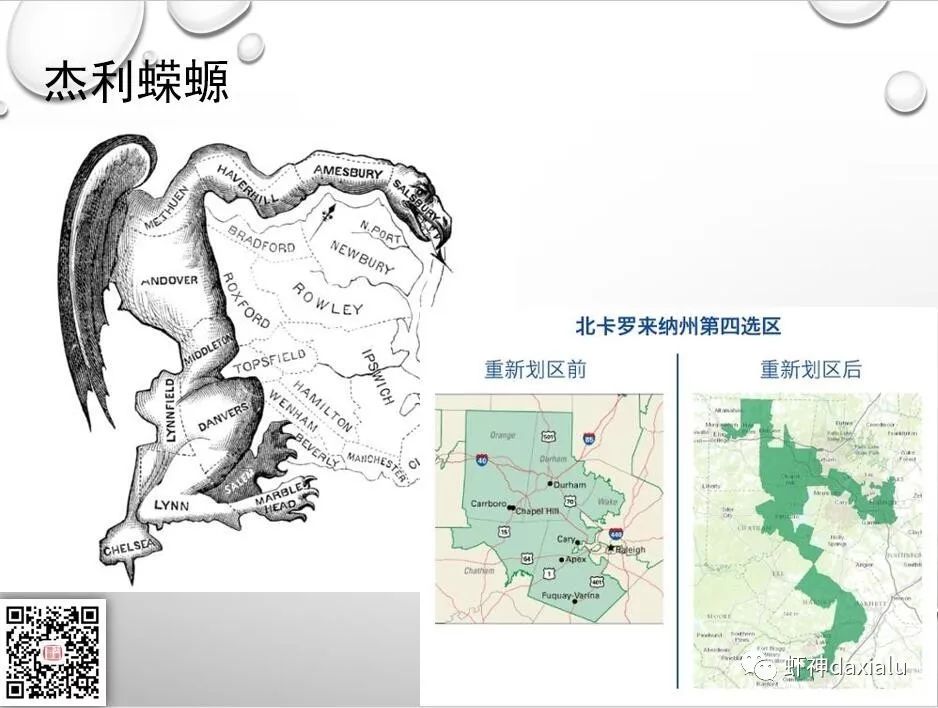
我们可以来看看美国历史上非常著名的事件:杰利蝾螈——有兴趣的同学,可以自行维基百科,我这就不大段复制了,这个事件虽然最后被终结,但是直到200年后的今天,依然存在,可以看2010年划分的北卡第四选区:
当然,除了这些阳谋以外,随着科技的进步,还出现了很多新的手段,比如:
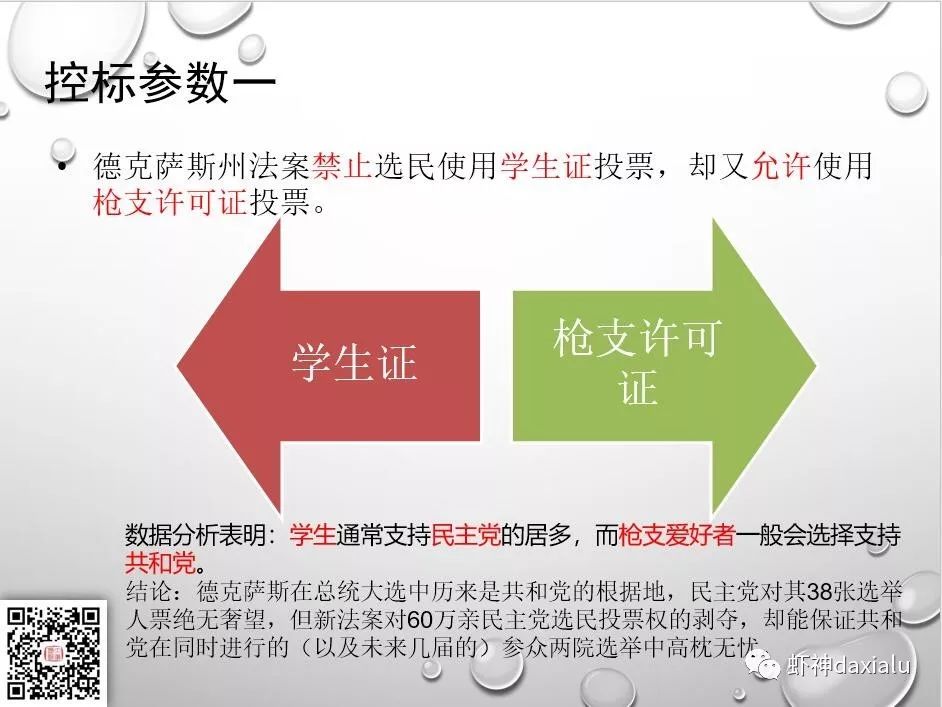
又比如在选票上动手脚:

不过,这些小动作,在2016年大选中的剑桥分析公司面前,都是上不了台面的东西:
因为,他们用的最厉害的手段:

他们的理论来源于下面这个研究:

经过了OCEAN测试,剑桥分析公司号称可以百分之百的了解你的喜好。
他们利用与facebook的合作,获取了超过8000多万用户的数据,并且进行精确的数据分析手段,获得了他们的喜好,然后:

他们怎么做的呢?
比如你是一个狂热的赛车爱好者,那么你每天打开电脑,都会无意中发现,某某候选人又出席了某赛车比赛的开幕式,然后发表了关于他特别爱好赛车,承诺他当选之后一定会大力发展赛车的言论……
反之,如果你是一个非常讨厌赛车的人,那么你打开电脑的,看见是他的竞选对手支持赛车发展的言论了……
正如怀利说的:

我们只给你看你想看到的
我们只给你看我们想让你看到的
如果说,每个人心理都有一个恶魔,那么数据和科技就可以把这个恶魔暴露出来,并且被利用。
(在特朗普公开的竞选⽀出明细中, 剑桥分析公司的名称赫然在列, 特朗普团队先后5次购买该公司的数据服务, 共⽀付了591万美元。)

(故事还在继续,我们待续未完)。
这篇关于白话空间统计番外五:美国大选中的数据科学的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







