本文主要是介绍NanoPi做深度学习开发(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在(一)中配置完成了深度学习的环境后,开始部署算法。然后在Pi上摄像头显示的检测图像不同步,由于在MAC上脚本是正常的,因此考虑是不是Pi的平台上处理器能力8行,于是掏出了Jetson Nano对同段代码运行,看一下画面效果如何。
嗯,效果是同步的。
李白曾经说过,如果眼睛看到的有用,那还要数据干什么?
因此,写了段代码验证一下相同尺寸图的情况下,不同的两个平台的测试时间如何。
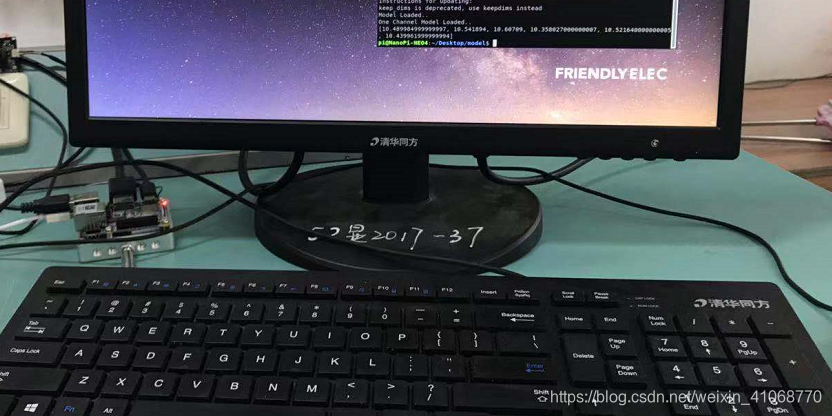
太真实了。JetsonNano在GPU的加速下,检测的平均时间在0.05s左右,NanoPi的检测时间在10s左右。
好的,问题又来了,NanoPi的检测时间太太太太太太太太太长了,枯了。

![]()
所以,又到了快乐的揪内鬼时间了,去看看哪出问题。
内鬼1:time.clock()
之前结果中,使用time.clock()测试的时间。
start = time.clock()
#long running
#do something other
end = time.clock()time.clock()返回程序第一次被调用的CPU时间。返回的是CPU的执行时间。
time.time()获取的是纪元以来的当前时间,程序执行结束后,获取的是程序执行时间。
start = time.time()
#long running
#do something other
end = time.time()
print end-start在改用time.time方法后,我们的检测时间如下:


Jeston的检测时间在10fps左右,而NanoPi的检测时间也从吓死人的10s变成了可以感受的2s,果然李白也是会骗人的。
time.time和time.clock在很多时候的结果差距不大,但还是不能大意呀。
揪出内鬼后,现在要做的就是想办法去加速了~干巴爹!哭泣…
2019.09.21更新
在检测算法的时候,发现自己写的模型本质上层数规模都很小,然而检测时间不像预期的一样仍较长。检测时仍使用
start = time.time()
#long running
#do something other
end = time.time()
print end-start的方法,发现在关键算法环节的测试时间其实很短,然而在结果呈现环节花费的时间很长。这里总结一条很小的经验:
不要过分相信自己的先验知识,在代码可能出现问题的段落,分句进行time检测,往往会有出乎意料的效果。
经过分局检测,在区域确定和算法检测部分的测试时间其实都较短,问题出现在了结果呈现部分。
经过观察呈现结果部分以及写了段代码测试发现,
cv2.rectangle(show, (self.find_ROI()[0], self.find_ROI()[1]), (self.find_ROI()[2], self.find_ROI()[3]), self.color, 4)该段代码中,涉及了了四次find_ROI调用,导致时间花费增大。
在测试发现,cv2.rectangle()本身时间很短,接近于0。因此考虑是内部参数出问题,果然找到了内鬼,揪出来后,效果立竿见影。
这篇关于NanoPi做深度学习开发(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





