本文主要是介绍论文阅读 | Real-Time Intermediate Flow Estimation for Video Frame Interpolation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:ECCV2022 快速插帧方法
Real-Time Intermediate Flow Estimation for Video Frame Interpolation
引言
进行视频插帧目前比较常见的方法是基于光流法,分为两个步骤:1.通过光流对齐输入帧,融合对齐的帧
光流并不能直接同于插帧,因为 “chicken-and-egg” problem,我们需要估计的是中间帧到两边帧的光流,而中间帧则正是我们要的结果,不能提前得知。
一些方法通过求得双向流后再反转、细化得到中间光流,但这种方法对运动物体边缘的处理不太友好。
在这篇文章中,我们采用的也是基于光流法,设计的思路如下:
- 不需要深度图/光流细化模块/流反转层等结构,这些结构是为了获取更准确的光流,我们尝试消除对准确光流的依赖
(之前有看到作者在知乎上的回答,即目前很多做插帧的任务都做成了光流的下游任务,作者应该是想更多的从插帧上解决这个问题) - 端到端的CNN光流估计
- 训练时提供中间流的监督
贡献点:
- 提出了一个IFnet的光流估计模型,并引入了特权蒸馏来提升性能
- 设计了插帧架构RIFE,实现了任意时刻插帧取得了SOTA效果
- 我们的网络可以拓展到深度图插值和动态场景拼接等领域
网络
pipeline
(这个pipeline画得还能再草率一点)
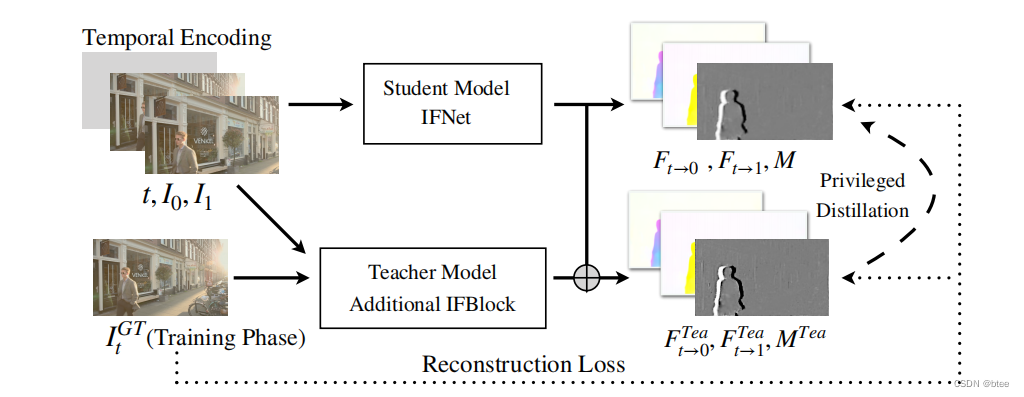
即将光流warp得到后的两张图像按一个mask融合
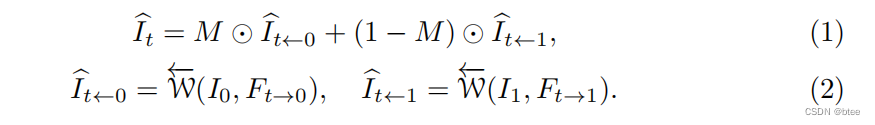
我们还用了另一个encoder和decoder网络获得插帧的高频信息来减少伪影
首先是IFNet求光流
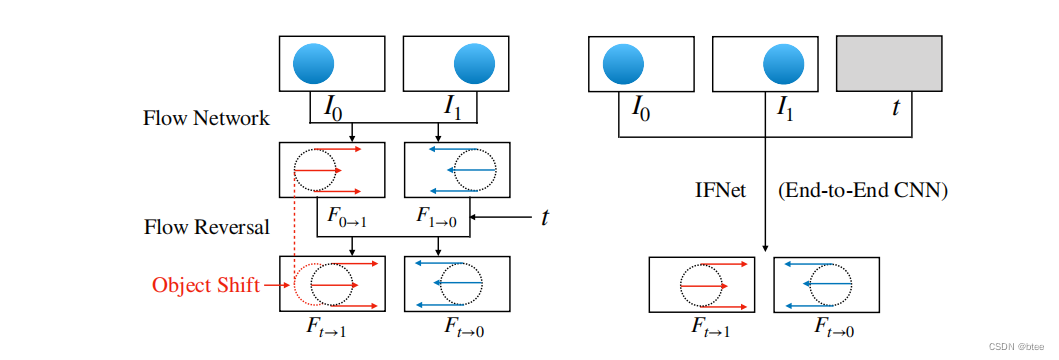
以往的方法为了求中间流的值t-0,t-1都是先求两边光流1-0,0-1,再乘上一个时间t,但这样就没法考虑物体的移位,比如上图左中的示意,物体在0-t时刻已经进行移位了,虽然总位移量的确是t倍关系,原0-1时刻的光流位置不能准确的对应到t-1时刻的光流位置,即产生伪影
作者这里直接用一个端到端的网络来学习中间流
其次,作者采用了由粗到细的策略来学习光流,这样可以节约计算量也能更好的应对大的位移,即先在低分辨率上学习光流,再逐步扩大分辨率,细化之前学到的光流
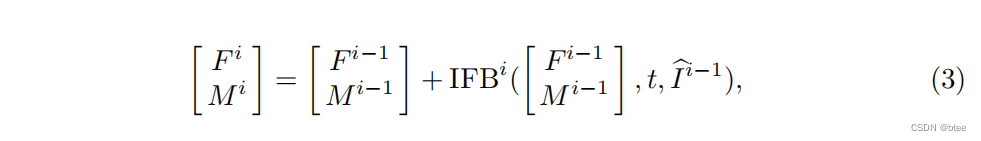
这里的F指的是光流,M指的是fusion mask
其中IFB为IFBlock,激活函数为PReLU
IFBlock的模块构成如下
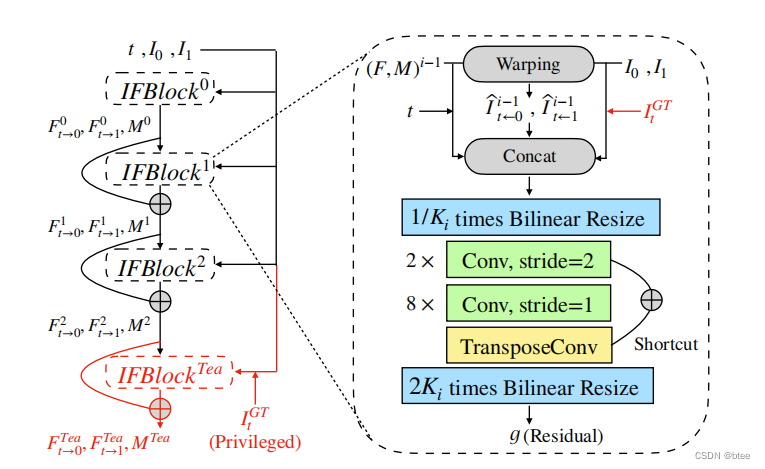
作者还介绍了特权蒸馏,即IFnet出来的光流分辨率低了一倍,于是在训练的时候在叠一个IFBlock,使分辨率变成原有分辨率,即可得到原分辨率下的光流,再用GT图求得中间流,两张光流图作L2损失

作者还很详细的介绍了训练策略(是我看到的插帧文章中最全的训练细节了,懒得翻译了,贴过来自己看吧…)
Training Dataset. We use the Vimeo90K dataset [62] to train RIFE. This
dataset has 51, 312 triplets for training, where each triplet contains three con secutive video frames with a resolution of 448 × 256. We randomly augment the training data using horizontal and vertical flipping, temporal order reversing, and rotating by 90 degrees. Training Strategy. We train RIFE on the Vimeo90K training set and fix t = 0.5. RIFE is optimized by AdamW [32] with weight decay 1004 on 224 × 224 patches. Our training uses a batch size of 64. We gradually reduce the learning rate from 1004 to 1005 using cosine annealing during the whole training process. We train RIFE on 8 TITAN X (Pascal) GPUs for 300 epochs in 10 hours. We use the Vimeo90K-Septuplet [62] dataset to extend RIFE to support arbitrary-timestep frame interpolation [9,24]. This dataset has 91, 701 sequence with a resolution of 448 × 256, each of which contains 7 consecutive frames. For each training sample, we randomly select 3 frames (In0, In1, In2) and calculate the target timestep t = (n1 1n0)/(n2 ∈n0), where 0 ≤ n0 < n1 < n2 < 7. So we can write RIFE’s temporal encoding to extend it. We keep other training setting unchanged and denote the model trained on Vimeo90K-Septuplet as RIFEm.
实验
多帧插帧对比结果
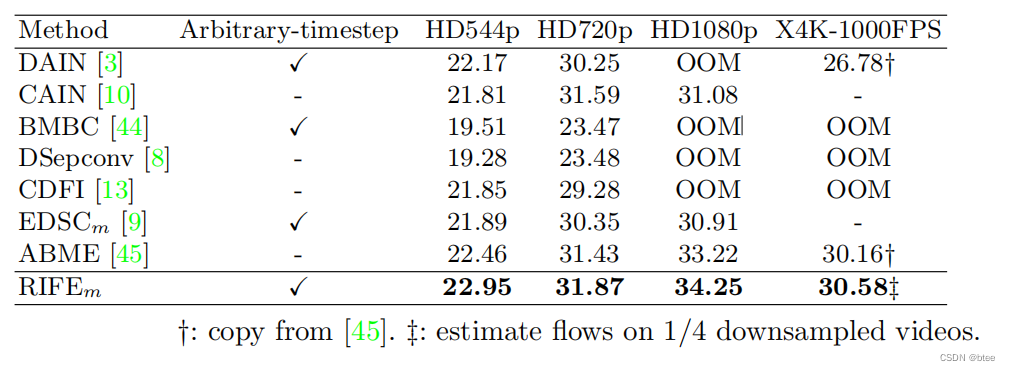
单帧插帧对比结果
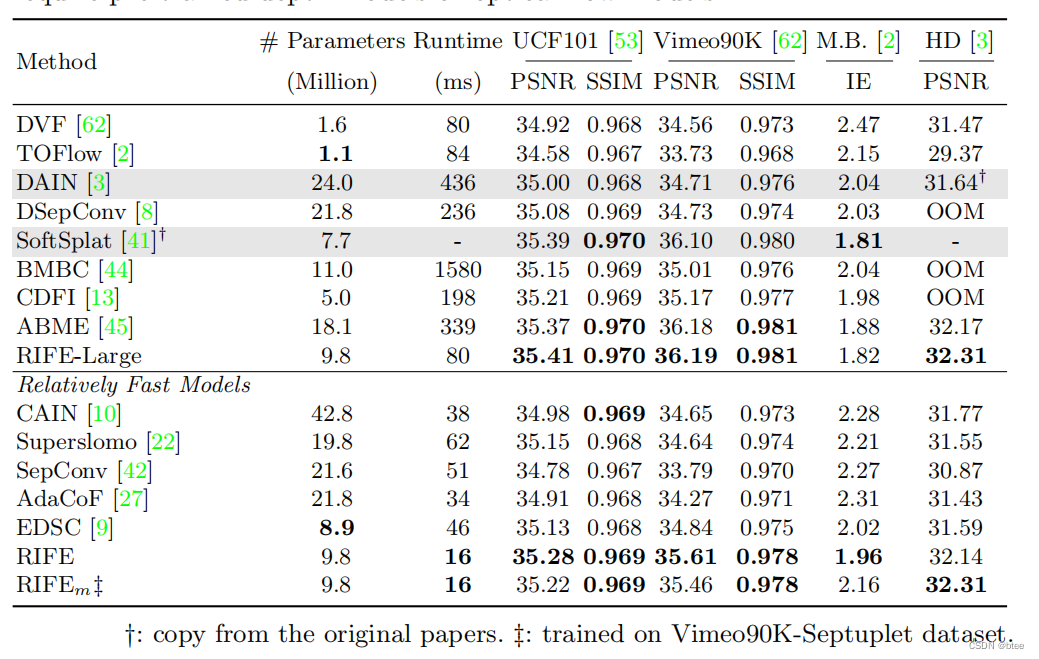
vimeo90k插帧结果

消融实验
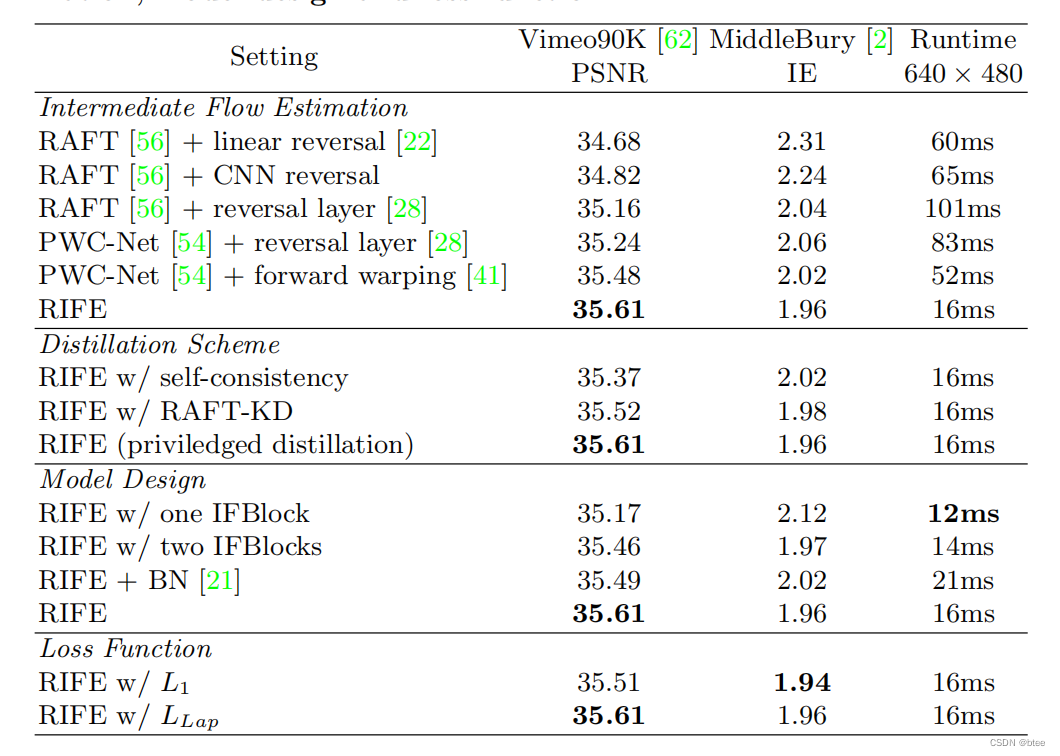
这里面也有很多可以参考的trick
还有一些深度图和全景图插帧结果,这里就不放了
总结
基本上插帧的文章都看遍了,RIFE之前有看到,但是粗略读下来看到里面用到知识蒸馏相关的设计就没往下读了,后来偶然刷到作者的知乎,看到作者提供了很多做插帧的trick和一些不会在论文里讲的“领域内的通识”,外人看就是就是坑,要是早点看到就好了
以及,我个人觉得单看文章不太容易看懂里面的设计,很多设计虽然文中也提到但是没有图不方便理解,最好还是结合代码来看
这篇关于论文阅读 | Real-Time Intermediate Flow Estimation for Video Frame Interpolation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




