本文主要是介绍【合规性检查-Fitness】基于Token重演的拟合度评估方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们继续对合规性检查的质量维度fitness进行介绍,本次介绍最为经典的拟合度指标计算方法-基于Token重演的拟合度指标检测方法。
1.背景
上节我们介绍了基于完全解析的拟合度计算评估方法,基于完全解析的拟合度计算评估方法存在轨迹层面的解析只能简单地判断轨迹是否符合模型,事件层面的解析相较于轨迹层面的能更大程度地判断轨迹的符合程度,但是前序事件对后续事件的判断有很大的影响等问题,为此提出了基于Token重演的拟合度评估方法,该方法是由A. Rozinat,和W.M.P. van der Aalst在2008年提出的方法,该方法是基于Petri网的引发规则进行的。
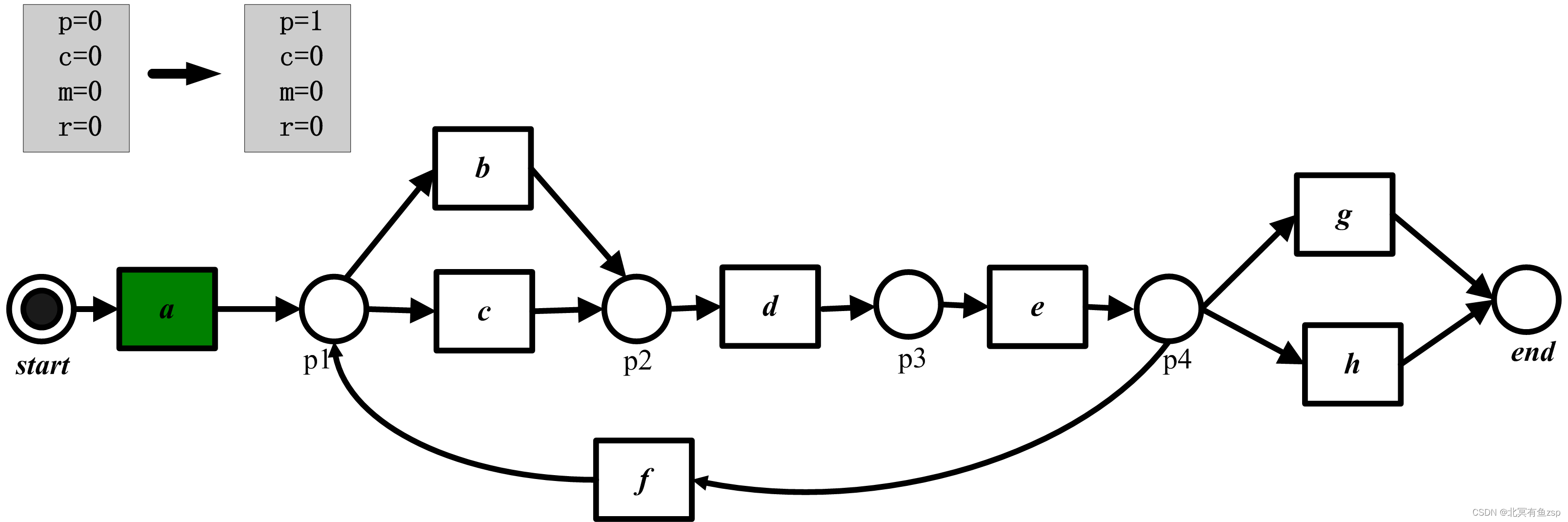
在介绍此方法之前,我们先简单地介绍下Petri网的引发规则。
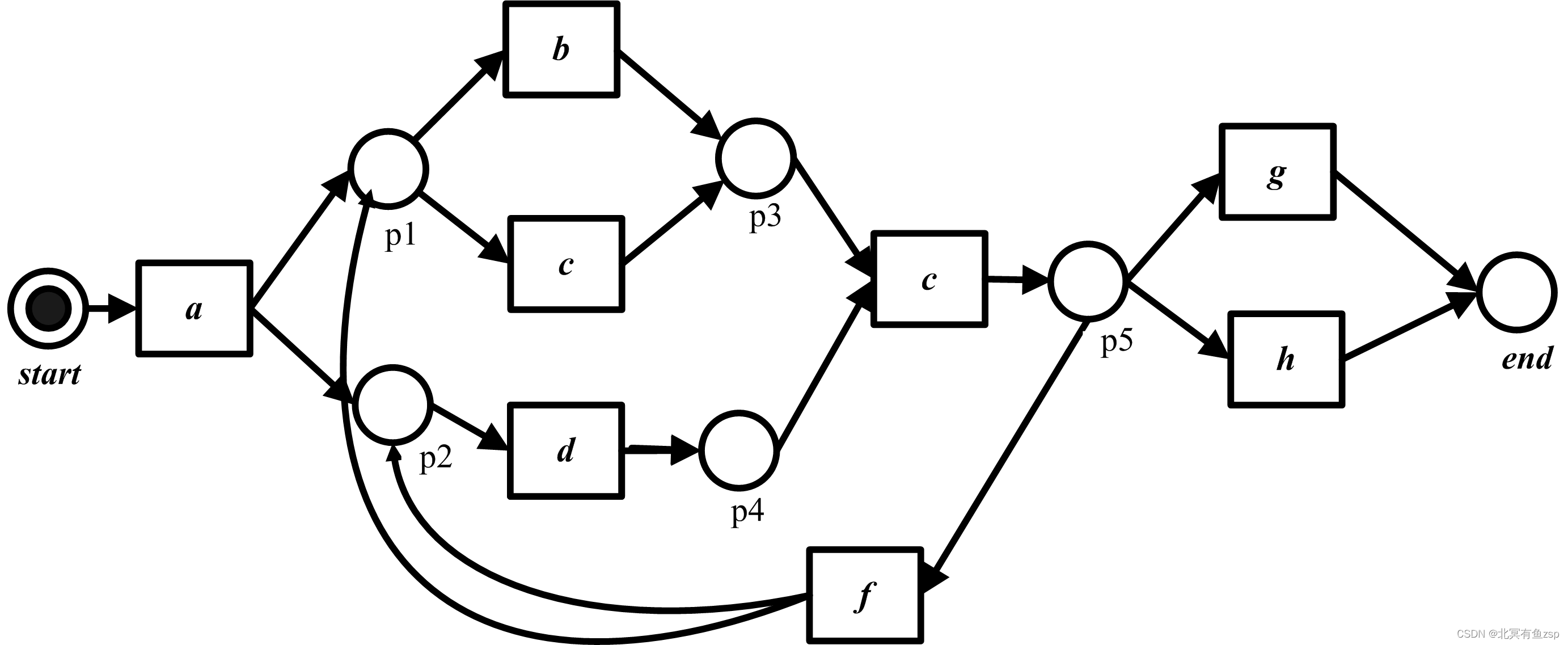
上图中只有start库所中有token(图中的小黑点),一个带标识的Petri网的动态行为可以用所谓的发生规则(fire rule)来定义。如果一个变迁的所有输入库所都含有托肯,那么这个变迁是使能的。一个使能的变迁可以发生(fire) ,此时从每个输入库所中消耗一个托肯,并在所有输出库所中生产一个托肯。
因此,变迁a在标识[start]使能,将托肯转移到标识[p1,p2],注意减少一个托肯的同时增加了两个托肯。在标识[p1,p2]上,变迁a不再使能。然而,变迁b,c,d使能,从标识[p1,p2]经变迁b发生,将得到标识[p2,p3].此时,d仍然使能,但b和c不再使能。由于含有变迁f的循环结构存在,该Petri网有无穷多个由[start]开始并在[end]终止的发生序列。
2.相关案例介绍
2.1 示例事件日志
给定一个事件日志L,包含的信息如下表所示,L中共有1391条轨迹,21条轨迹变体(不重复的轨迹数)。例如,在轨迹1=<a,c,d,e,h>中有455个案例,在轨迹2=<a,b,d,e,g>中有191个案例等。

2.2 示例流程模型
给定四个对应的流程模型,如下图所示,各Petri网模型的具体情况如下所示:
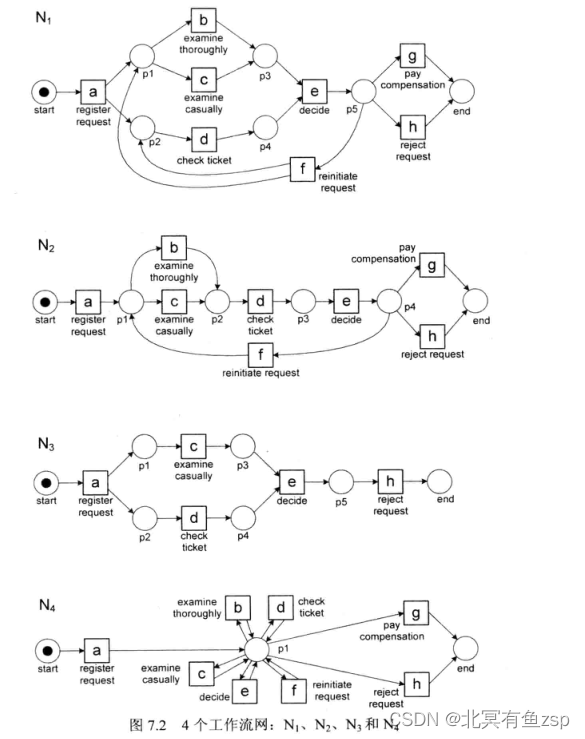
Petri网N1是对上述示例日志L应用基础α算法发现的流程模型;
Petri网N2相对于N1是一个顺序模型,需要在活动d前进行活动b或者活动c,有些示例日志L中的轨迹不能被表示;
Petri网N3中没有选择结构,即要求总是被拒绝,在示例日志L中的大部分轨迹不能被表示出来;
Petri网N4是一个“花型模型”的变体:只要求轨迹以a开始,以g或h结束,很明显,示例日志L中的所有轨迹都能够被N4表示。
3.轨迹在模型上的Token重演拟合度过程
为了解释这一思想,我们引入了四个计数器:p(产生的托肯)、c(消耗的托肯)、m(缺失的托肯),r(遗留的托肯)。我们举2个例子来具体说明此方法。
3.1 轨迹1在模型N1上的重演步骤(完全重演)
首先我们先对上述事件日志L中的轨迹1=<a,c,d,e,h>在模型N1上进行重演,请注意,轨迹1是可以完全被重演,也就是拟合度为1。
我们逐步分析重演的步骤,先关注p(产生的托肯)和c(消耗的托肯)。
(1)开始时,p=c=0且所有库所是空的,接着环境(一般Petri网有一个初识标记用于触发规则)为开始库所start产生一个托肯,所以此时p的计数器增长:p=1。
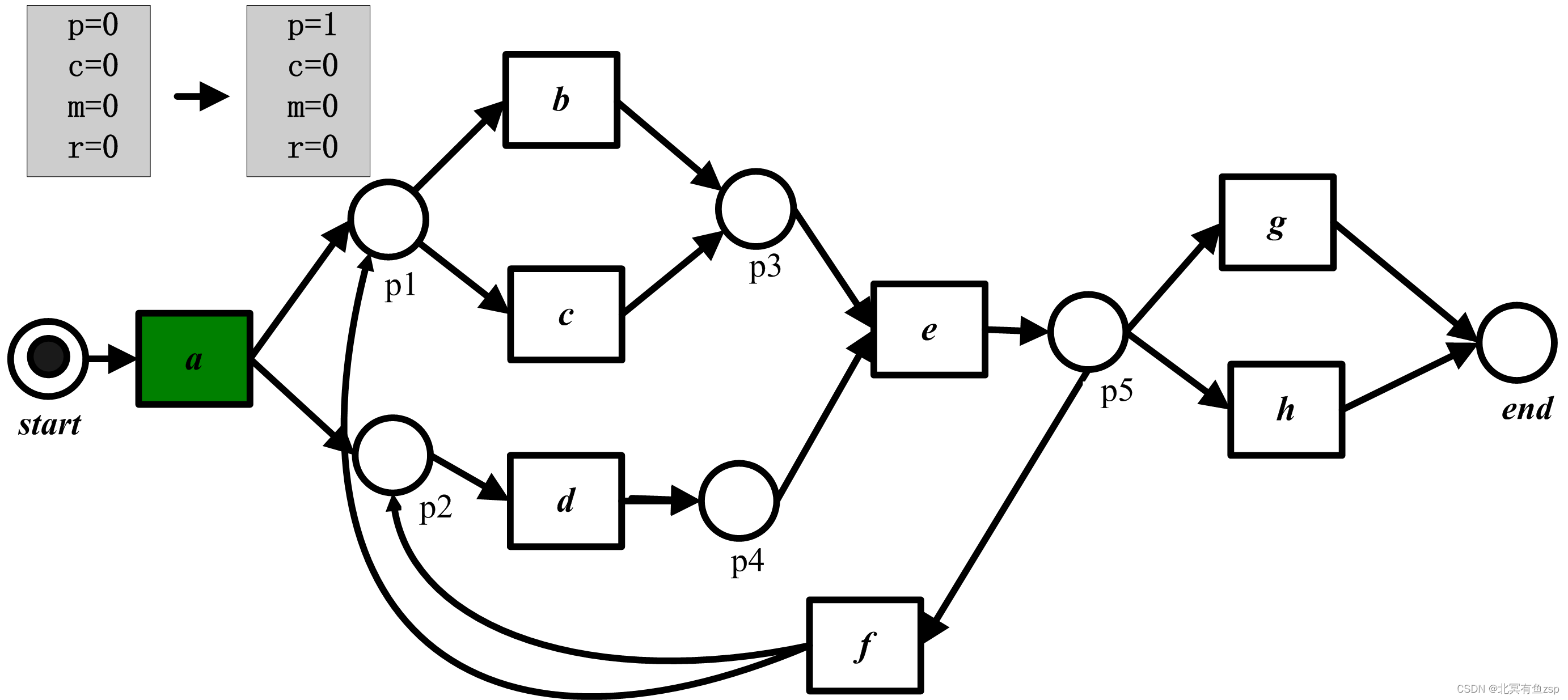
(2)现在我们需要重演轨迹1=<a,c,d,e,h>,首先触发变迁a,这是可能的,因此变迁a消耗了一个托肯并产生了2个托肯,c计数器增长1,且p计数器增长2,。所以,在触发变迁a后p=3,且c=1。 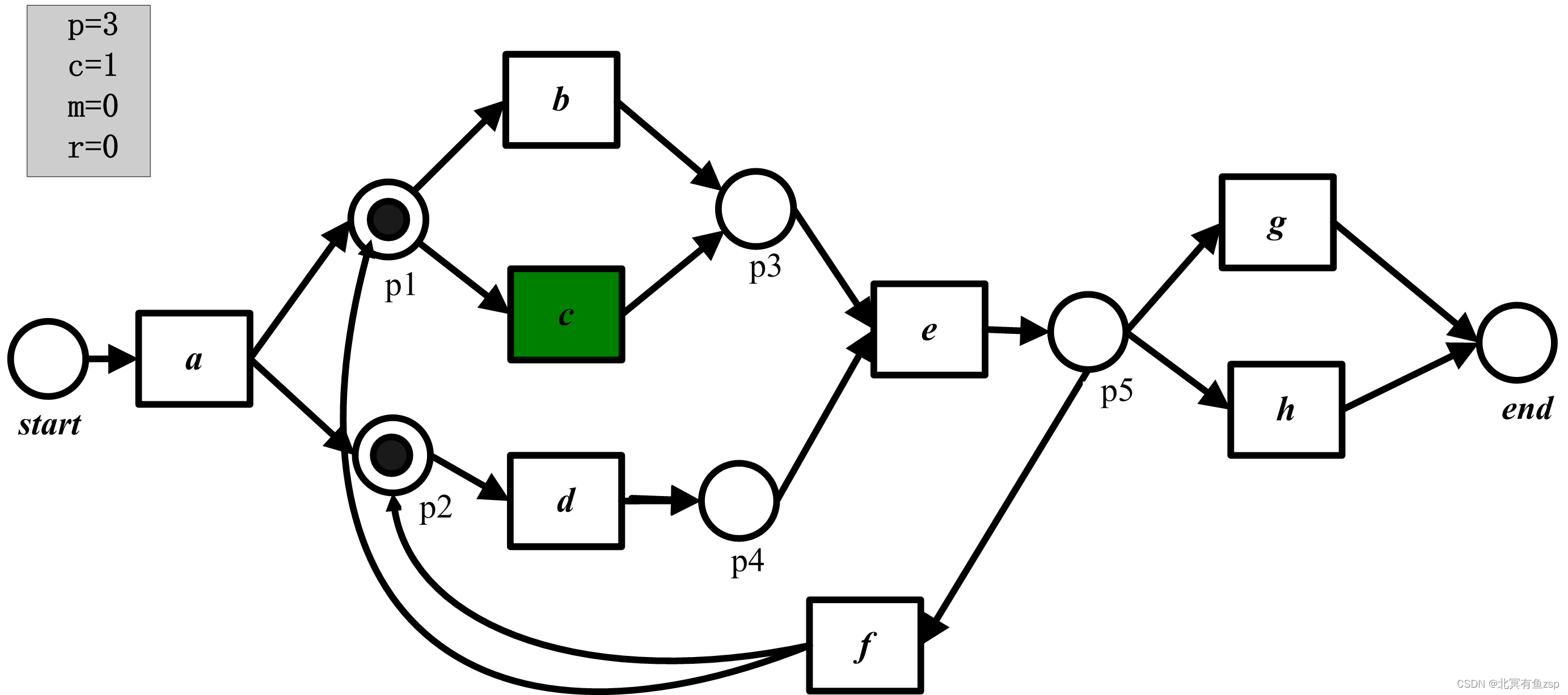
(3)下一步,我们重演第二个事件(c),触发变迁c,导致p=4且c=2。
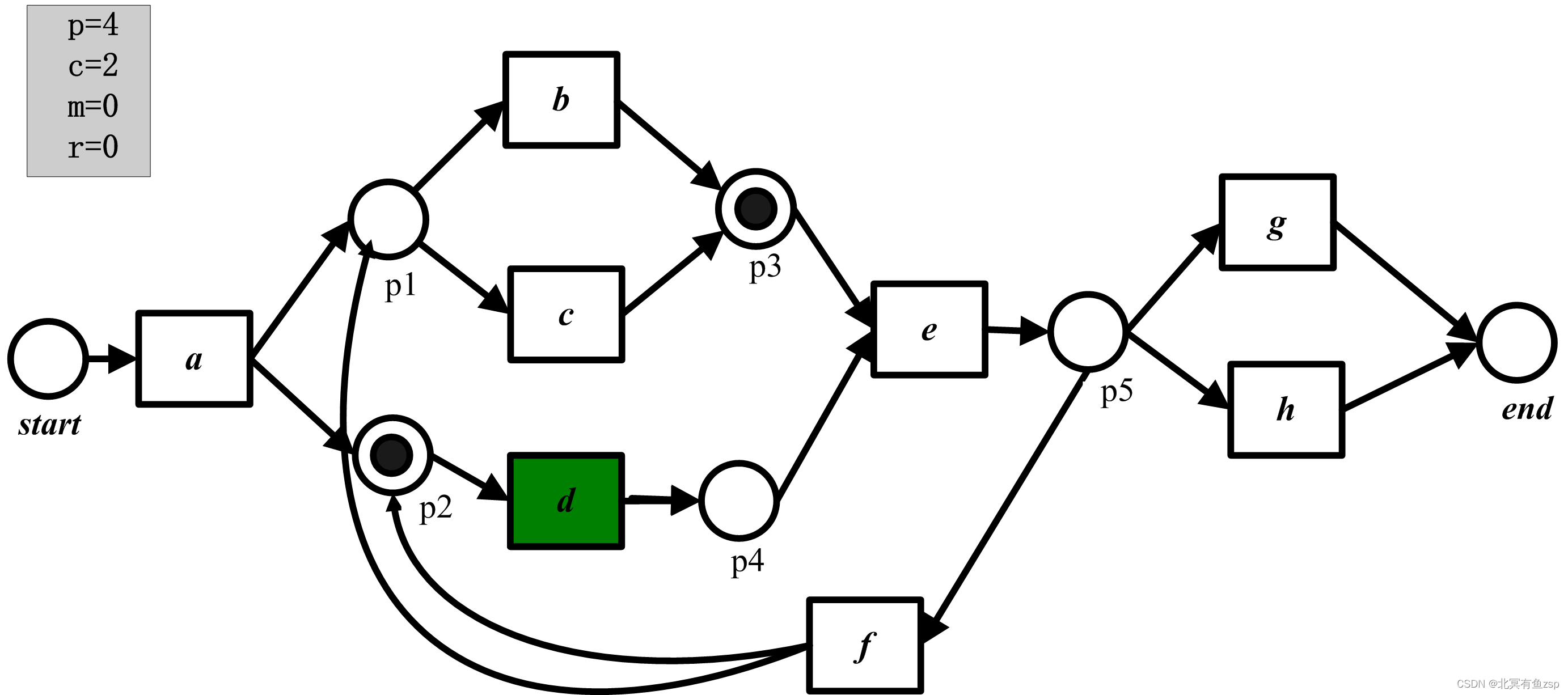
(4)在重演第三个事件(d)后,p=5且c=3。
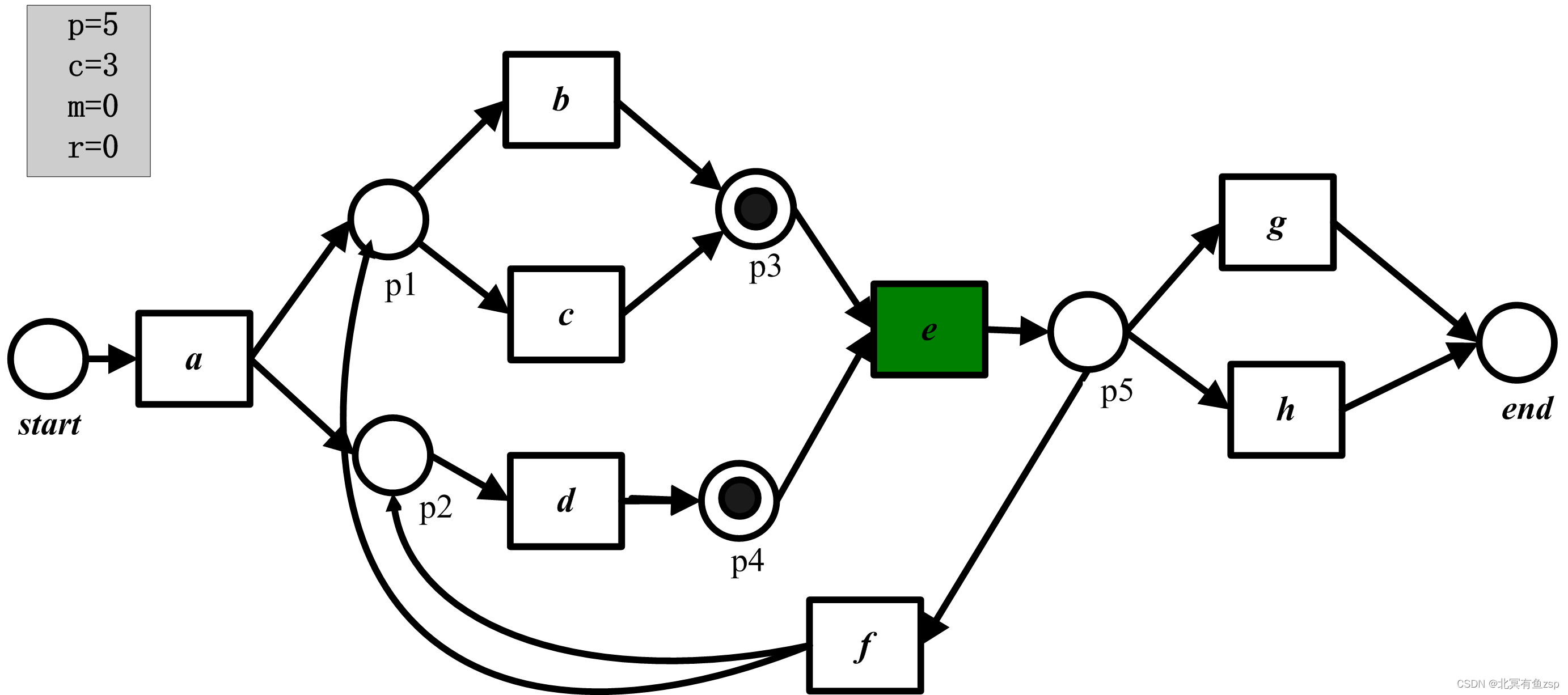
(5)在重演第四个事件(e)后,p=6且c=5。
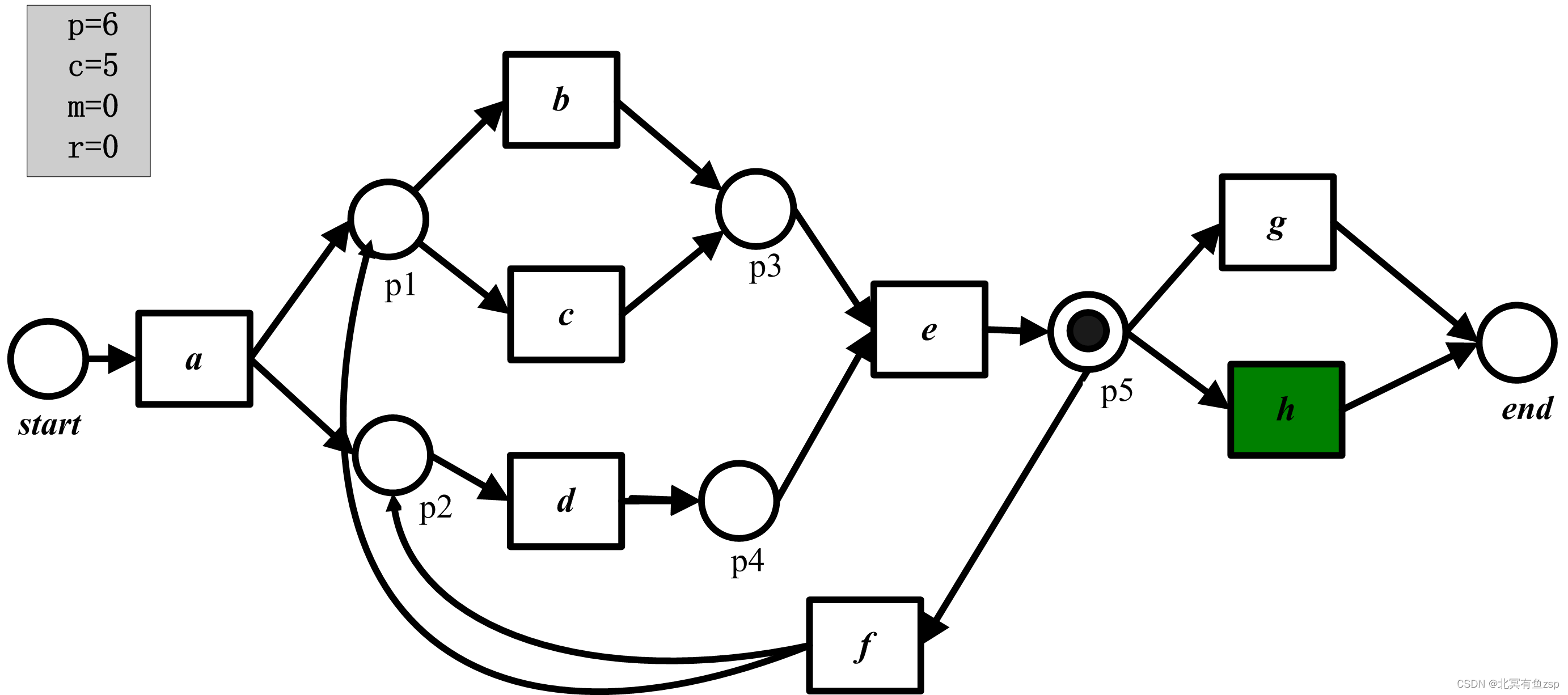
(6)重演最后一个事件(h),触发产生的结果是p=7且c=6,。最后,环境从终止库所中消耗了一个托肯。因此,最终的结果是p=c=7且m=r=0.
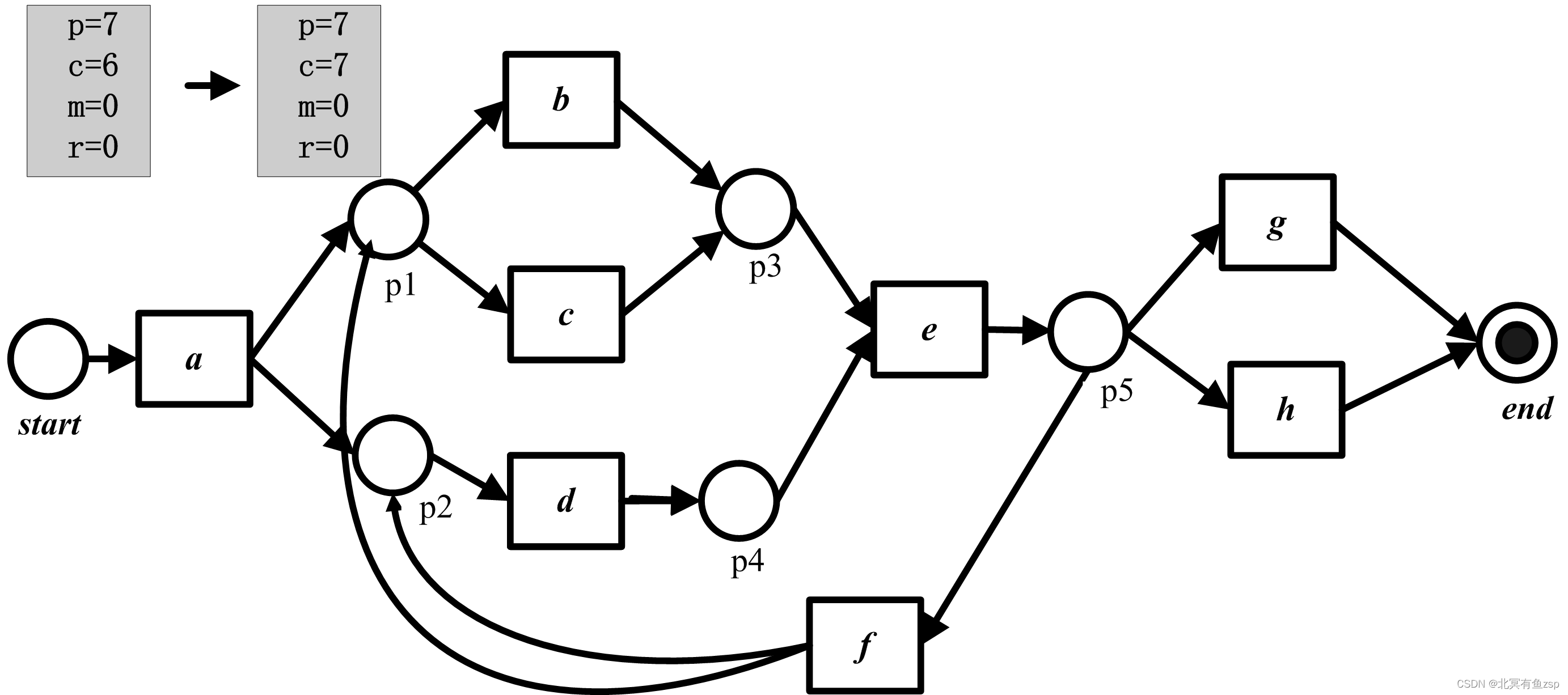
很明显,当重演轨迹1时没有问题,即没有缺失或者遗留的托肯(m=r=0)。
因此,在模型N上的一条轨迹为的拟合度定义如下:
式子中,第一部分计算的是缺失的托肯(m)与消耗的托肯(c)的数量比,如果没有缺失的托肯(m=0),则1-m/c=1;如果所有消耗的托肯都缺失(m=c),则1-m/c=0。同样,如果没有遗留的托肯,则1-r/p=1;如果所有生产的托肯实际上都没有被消耗,则1-r/p=0。我们对缺失和遗留的托肯使用相等的惩罚。根据定义:
。
用上述公式计算fitness(1,N1)=1/2(1-0/7)+1/2(1-0/7)=1,因为没有缺失或遗留的托肯。
接下来,我们考虑不能够被适当重演的轨迹。
3.2 轨迹3在模型N2上的重演步骤(不完全重演)
下面我们介绍在工作流网N2上重演轨迹3=<a,d,c,e,h>的过程。
(1)开始,p=c=0且所有库所都是空的。然后环境为开始库所生成一个托肯,且p计数器被更新:p=1。
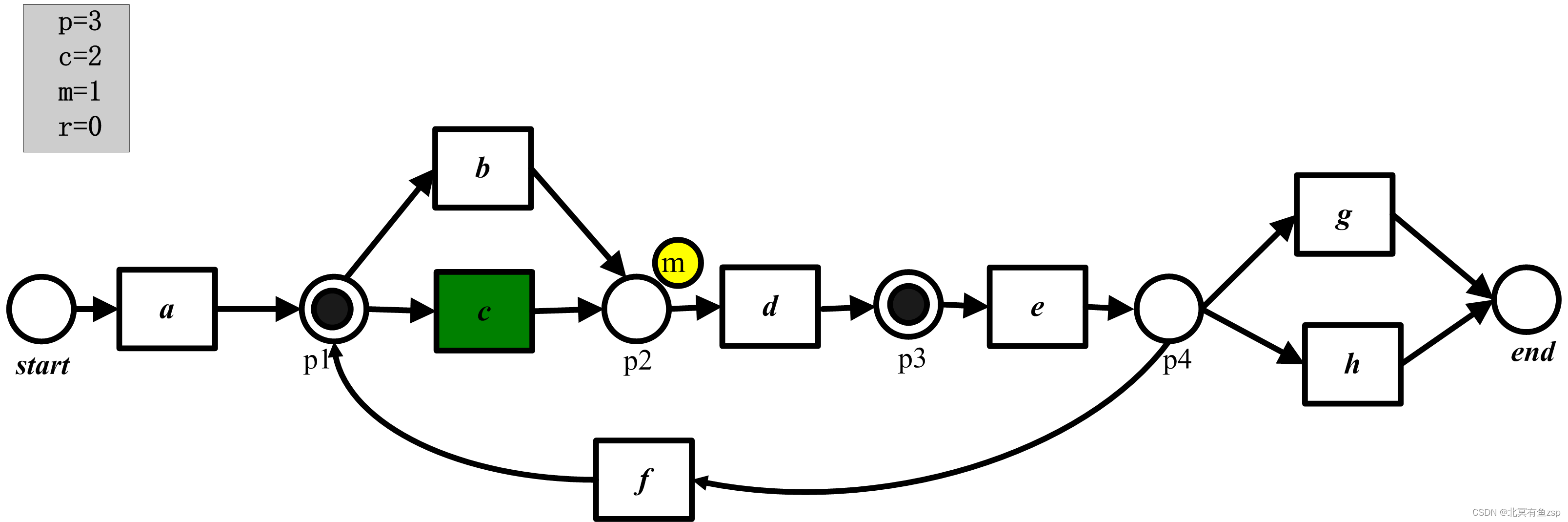
(2) 第一个事件(a)能够被重演,在触发a之后,计数器为p=2、c=1、m=0且r=0.

(3) 接着,我们试着重演第二个事件,这是不可能的,因为变迁d没有被使能,为了触发d,需要在库所p2中加入一个托肯,并记录缺失的托肯,也就是说,m计数器值增加,p和c计数器像平常一样被更新。因此,触发d之后,计数器值为p=3、c=2、m=1、r=0。我们也标记库所派p2来记录缺失了一个托肯。
(4) 然后,我们重演接下来的3个事件(c、e、h)。与之符合的变迁被使能,所以我们只需要更新p和c计算器。在重演完最后一个事件后,有p=6、c=5、m=1且r=0.
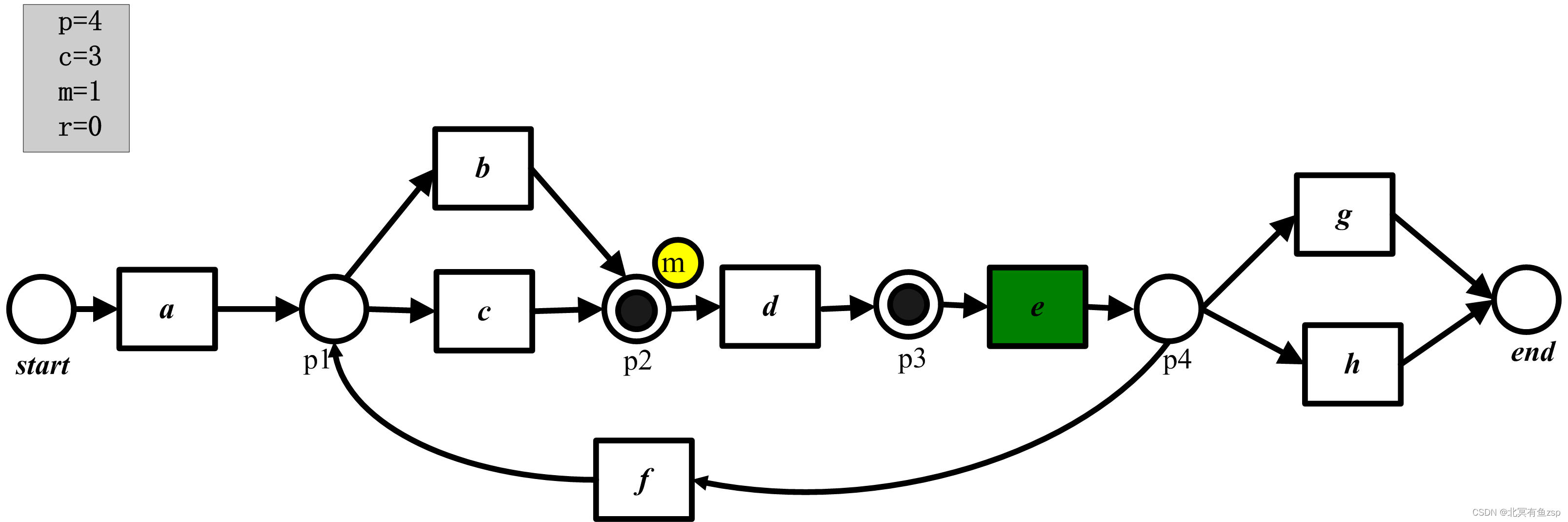
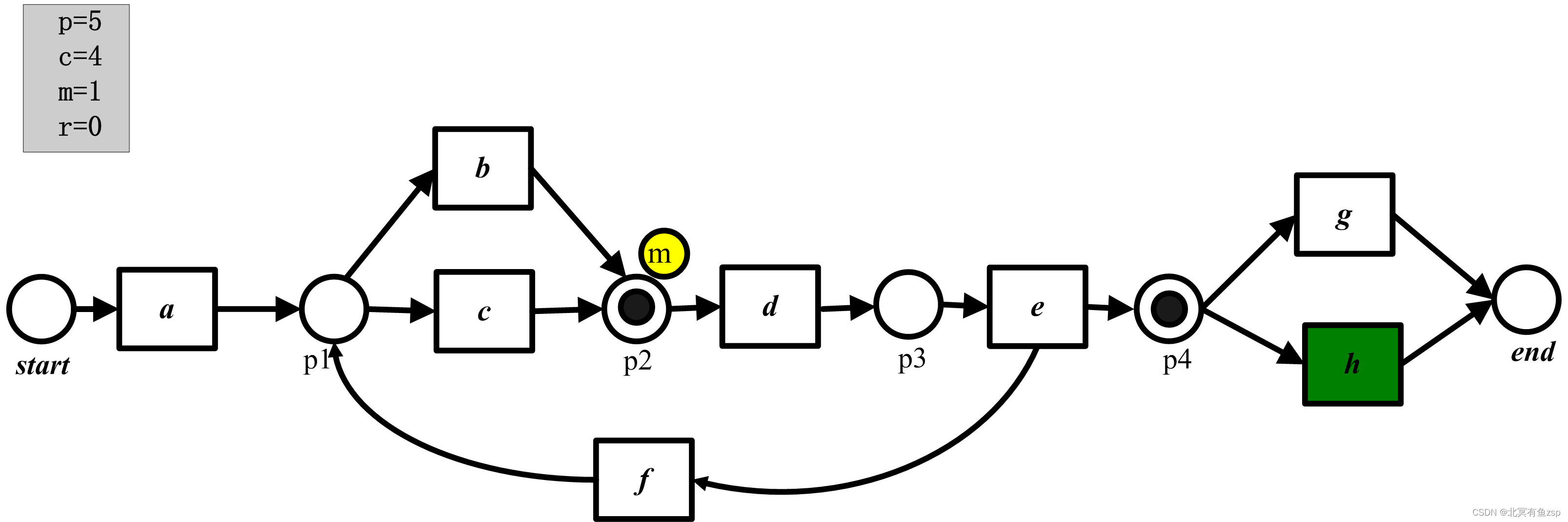
(5)在最后状态[p2,end],环境从终止库所消耗了托肯,1个托肯遗留在库所p2中,所以库所p2被标记,r计算器增长。所以最终p=c=6,且m=r=1。
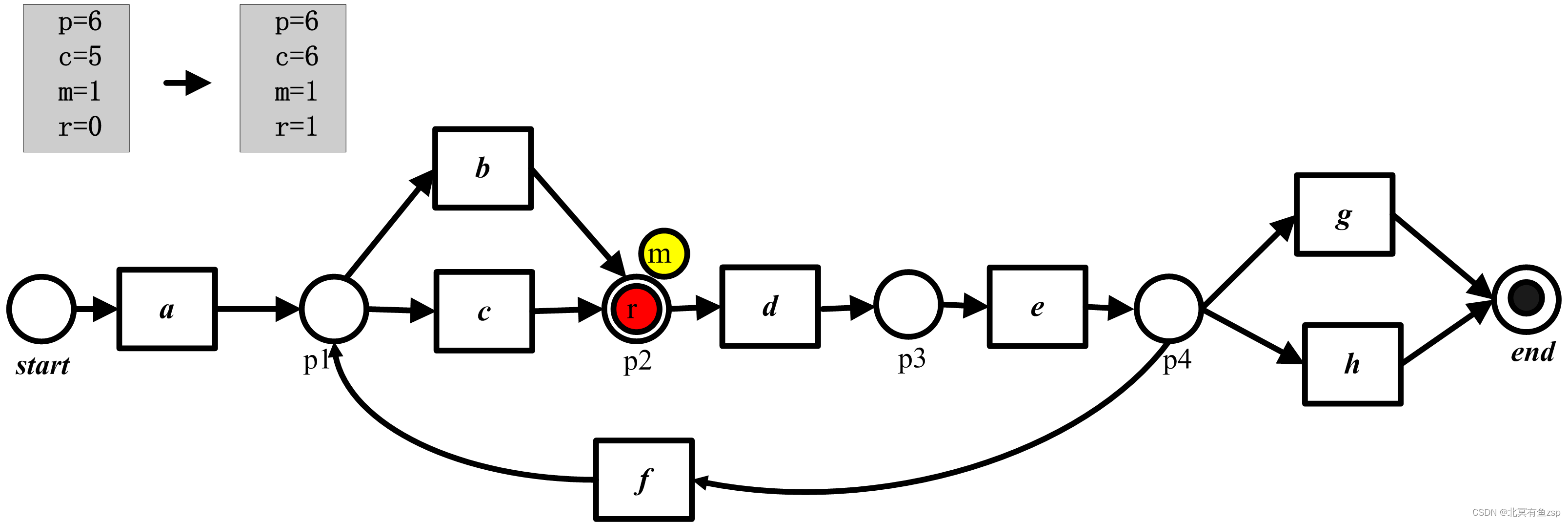
有一种情况,d发生了,但是依据模型(m标签)不能发声;有一种情况是d应该发生,但依据日志(r标签)却没发生,此外,我们能够依据p、c、m和r从而计算工作流网N2上的轨迹3的拟合度:
fitness(2,N2)=1/2(1-1/6)+1/2(1-1/6)=0.8333
同理,fitness(2,N3)=0.6
4.整个事件日志对于模型的重演指标计算
上述说明了怎么具体分析一条轨迹的拟合度,而相同的方法可以推广到用于分析一个由多条轨迹组成的事件日志的拟合度。简而言之,就是计算所有产生的、消耗的、缺失的和遗留的托肯数总和,并且应用相同的公式。
依照上述公式,我们计算出事件日志L和上述对应的4个流程模型的拟合度表示如下:
fitness(L,N1)=1, fitness(L,N2)=0.9504
fitness(L,N3)=0.8797, fitness(L,N4)=1
正如预期的一样,N1和N4可以没有任何问题地重演L(即拟合度为1)。fitness(L,N2)=0.9504,直观来看,L中有大约95%的事件可以在N2上被正确重演。可以从两方面理解:
1.事件日志L有0.9504的拟合度,也就是说,大约5%的事件是偏离的;
2.流程模型N2有0.9504的拟合度,也就是说,模型不能够解释观察到的行为中的5%。
第一种的角度是被用于模型被认为是规范和正确的时候,(即“现实不符合模型”);
第二种的角度是被用于模型是描述性的时候(即“流程模型不符合现实”)
5.结论
在流程模型上重演事件日志不仅仅局限于Petri网,任何包含可执行语义的流程模型表示法都允许重演,但当重演有静默活动的变迁或者重复任务的变迁时,通常会导致状态空间爆炸,因此需要更高级的重演技术。
下一讲我们将介绍基于对齐(Alignment)的重演技术-fitness。
参考文献:
1.《流程挖掘:业务过程的发现、合规和改进》,Wil van der Aalst著,王建民、闻立杰等译;
2.A. Rozinat, W.M.P. van der Aalst, Conformance checking of processes based on monitoring real behavior, Inf. Syst. 33 (1) (2008) 64–95.
如需进行相关的了解或者交流,欢迎私信或者加入QQ群:

这篇关于【合规性检查-Fitness】基于Token重演的拟合度评估方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



