本文主要是介绍如何处理【SVC】中的样本不均衡问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
样本不均衡是指在一组数据集中,标签的一类天生 占有很大的比例,但我们有着捕捉出某种特定的分类的需求的状况。比如,我们现在要对潜在犯罪者和普通人进行 分类,潜在犯罪者占总人口的比例是相当低的,也许只有2%左右,98%的人都是普通人,而我们的目标是要捕获 出潜在犯罪者。
在这里我们引入参数class_weight,这个参数可以通过设置标签的权重来影响建模的效果,更好的捕捉少数类。我们接下来就来看看如何使用这个参数。
首先自建一组样本不平衡的数据集。我们在这组数据集上建两个SVC模型,一个设置有class_weight参数,一个不设置class_weight参数。我们对两个模型分别进行评估并画出他们的决策边界,以此来观察class_weight带来的效果。
我们先导入相应的模块:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs再来创建不均衡样本:
class_1 = 500 #类别1有500个样本,10:1
class_2 = 50 #类别2只有50个
centers = [[0.0, 0.0], [2.0, 2.0]] #设定两个类别的中心
clusters_std = [1.5, 0.5] #设定两个类别的方差,通常来说,样本量比较大的类别会更加松散
X, y = make_blobs(n_samples=[class_1, class_2],centers=centers,cluster_std=clusters_std,random_state=0, shuffle=False)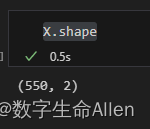
可以看到,我们创建了550个样本,2个特征的特征矩阵。
接下来我们画散点图:
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="rainbow",s=10)
plt.show()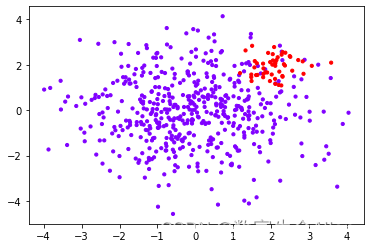
可以看到一个样本不均衡的散点图。接下来我们实例化两个线性分类器,分别是不含class_weight参数和含有class_weight参数:
#不设定class_weight
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X, y)#设定class_weight
wclf = svm.SVC(kernel='linear', class_weight={1: 10})
wclf.fit(X, y)然后我们打分:
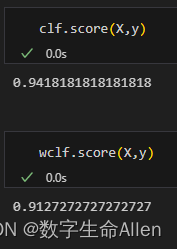
可以看出,从准确率的角度来看,不做样本平衡的时候准确率反而更高,做了样本平衡准确率反而变低了,这是因为做了样本平衡后,为了要更有效地捕捉出少数类,模型误伤了许多多数类样本,而多数类被分错的样本数量 > 少 数类被分类正确的样本数量,使得模型整体的精确性下降。现在,如果我们的目的是模型整体的准确率,那我们就 要拒绝样本平衡,使用class_weight被设置之前的模型。然而在现实中,我们往往都在追求捕捉少数类,因为在很多情况下,将少数类判断错的代价是巨大的。比如我们之 前提到的,判断潜在犯罪者和普通人的例子,如果我们没有能够识别出潜在犯罪者,那么这些人就可能去危害社 会,造成恶劣影响,但如果我们把普通人错认为是潜在犯罪者,我们也许只是需要增加一些监控和人为甄别的成 本。所以对我们来说,我们宁愿把普通人判错,也不想放过任何一个潜在犯罪者。我们希望不惜一切代价来捕获少 数类,或者希望捕捉出尽量多的少数类,那我们就必须使用class_weight设置后的模型
接下来我们将决策超平面绘制出来,现在回忆一下我们绘制决策超平面的3步:①绘制网格②计算每个样本点和决策超平面的距离③画图例。代码如下:
#首先要有数据分布
plt.figure(figsize=(6,5))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="rainbow",s=10)
ax = plt.gca() #获取当前的子图,如果不存在,则创建新的子图#绘制决策边界的第一步:要有网格
xlim = ax.get_xlim()
ylim = ax.get_ylim()xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T#第二步:找出我们的样本点到决策边界的距离
Z_clf = clf.decision_function(xy).reshape(XX.shape)
a = ax.contour(XX, YY, Z_clf, colors='black', levels=[0], alpha=0.5, linestyles=['-'])Z_wclf = wclf.decision_function(xy).reshape(XX.shape)
b = ax.contour(XX, YY, Z_wclf, colors='red', levels=[0], alpha=0.5, linestyles=['-'])#第三步:画图例
plt.legend([a.collections[0], b.collections[0]], ["non weighted", "weighted"],loc="upper right")
plt.show()输出结果如下图所示:
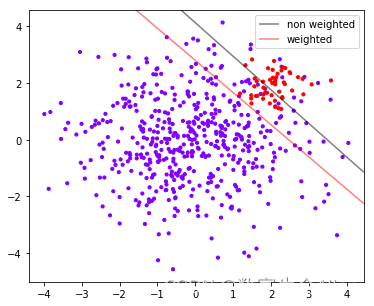
可以看到用了class_weight之后,模型会将少数类全部分类正确,但是也会误伤多数类。因此单纯地追求捕捉出少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。所以在现实中,我们往往在寻找捕获少数类的能力和将多数类判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵和ROC曲线。详情请看下一篇推文。
这篇关于如何处理【SVC】中的样本不均衡问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







