本文主要是介绍yolov5的正负样本的定义和匹配,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- build_target
- 1.输入参数
- 2.初始化准备
- 3.设置偏移值
- 4.初步筛选出正样本
- 5.扩增正样本
- 6.返回值
- 代码
- 总结
前言
虽然yolov5没有正式的论文发布,但是其整个检测框架已经越来越成熟了。
源码:https://github.com/ultralytics/yolov5
版本yolov5 v6.1
build_target
正负样本的分配,建立在生成target的步骤上,方便后面训练时损失的计算。
1.输入参数
def build_targets(self, p, targets):'''P:predict->[检测层数,ANCHOR个数,gridspace长,gridspace宽,类别数+5(xywh+obj)], targets:[num_target,image+class+xywh]'''# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
输入参数预测输出p : [检测层数,anchor个数,gridspace长,gridspace宽,classes+5(xywh+obj)],这个p的作用只是为了提供特征层的尺寸,计算target是anchor与targets之间的事。

输入参数标签targets信息 : [num_target,image+classes+xywh],是归一化了的信息

2.初始化准备
na : anchor的数量,一般都是给3个聚类或手工设置的模板
nt :一个batch里的所有target的数量
tcls, tbox, indices, anch :用来存放结果
gain :保存输出特征层的长宽尺寸,作为匹配argets在对应特征层上的坐标大小
ai : 一个targets有3个anchors的模板索引,要根据索引取anchor匹配计算loss
targets :每个target都有3个anchors,把anchors的模板索引加到后面,组成一个[3,nt,7]
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)na, nt = self.na, targets.shape[0] # number of anchors, targets,na正常都为3tcls, tbox, indices, anch = [], [], [], [] # 用来存放结果的gain = torch.ones(7, device=self.device) # normalized to gridspace(就是输出的检测特征层大小) ,保存放缩到特征图大小的因子# ai:[3,nt],每个target对应的anchor索引,方便下一句的ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt),# cat([3,nt,6],[3,nt,1],dim=2)->[3,nt,7] nt:num_targets,增加anchor索引targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices,复制3份对应3个anchor
3.设置偏移值
设置target上下左右的网格也作为正样本的考虑范围,后面是要减去偏移值
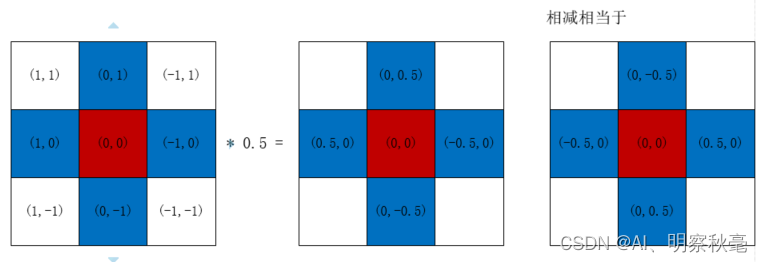
g = 0.5 # bias,偏移值off = torch.tensor( # 坐标偏移值分别对应中心点、左、上、右、下[[0, 0],[1, 0],[0, 1],[-1, 0],[0, -1], # j,k,l,m# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm],device=self.device).float() * g # offsets,g=0.5,变为偏移值为0.54.初步筛选出正样本
不同于yolov3和yolov4利用类似MaxIoUAssigner分配的原则去对正负样本进行定义和分配。yolov5通过将聚类或者手工设置的anchor,通过计算它们与target的宽高之比的最大值是否小于一个阈值来进行正负样本的划分。小于(包含在内)为正样本,大于为负样本。图参考:https://blog.csdn.net/qq_37541097/article/details/123594351
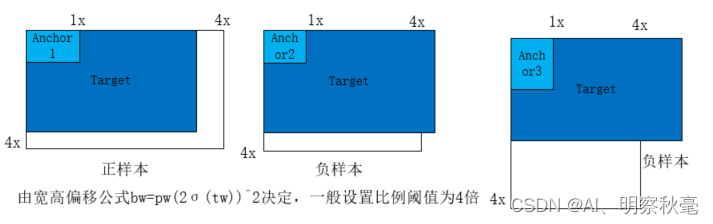
for i in range(self.nl): # 遍历每个检测层anchors = self.anchors[i] # 获取第i个模板的anchor# gain = [1, 1, 特征图w, 特征图_h, 特征图w, 特征图_h]gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain,放缩因子# Match targets to anchorst = targets * gain # targets为归一化的,乘以当前层尺度还原为当前层的尺度if nt: # 如果分层检测的特征层上有目标# Matchesr = t[..., 4:6] / anchors[:, None] # wh ratio# self.hyp['anchor_t']=4,根据偏移值计算公式,bw=pw(2σ(tw))^2,比值范围最好为(0,4)j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare,.max(2)[0]返回宽的比值和高的比值两者中较大的一个值# yolov5之前的方法,通过iou阈值来分配正负样本# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))# j中,符合比列要求的为true,否则为falset = t[j] # filter,[3,nt,7][3,nt]->[num_P,7],初步选择好了哪些anchors对应正样本
5.扩增正样本
为了解决正样本较少的问题,同时因为中心偏移值范围限制在(-0.5,1.5)之间,所以可以通过将周围符合条件的网格也作为正样本点。一个target除了本身匹配的一个正样本,还可以通过减去偏移值,将target最多移动到邻近的两个网格以网格左上角为标准去进行回归偏移值计算。这样,一个target最多可以匹配三个正样本。

# Offsetsgxy = t[:, 2:4] # grid xy, # 正样本的xy中心坐标gxi = gain[[2, 3]] - gxy # inverse # 特征图的长宽-targets的中心j, k = ((gxy % 1 < g) & (gxy > 1)).T # <0.5,取网格中偏向于左,上的target为truel, m = ((gxi % 1 < g) & (gxi > 1)).T # 取网格中偏向于右,下的target为truej = torch.stack((torch.ones_like(j), j, k, l, m)) # 中心加左,上,右,下,五个# [num_P,7]->[5,num_P,7][5,num_P]->[num_P+,7],取出所有对应为true的target信息# 有重复的,但是后面会减去相应的偏移值,来定义更多的正样本,进而扩充正样本数量t = t.repeat((5, 1, 1))[j] # 复制五份,取出对应位置的target信息# [1,num_P,2]+[5,1,2]->[5,num_P,2],初始化坐标值,表示后面正样本经过每个偏移方向后的坐标# [5,num_P,2][5,num_P]->[num_P+,7],符合上面所说的每个正样本取邻近网格作为正样本偏移值的计算offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]else:t = targets[0]offsets = 0# Definebc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchorsa, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class# 正样本中心坐标减去每个方向的偏移值,对应一个正样本变成三个正样本,.long()表示以网格左上角坐标计算偏移值gij = (gxy - offsets).long() gi, gj = gij.T # grid indices,把坐标分离开
6.返回值
indices:batch里图像的索引,anchor的索引,以及预测输出特征层坐标的索引。这个后面计算loss的时候要从相应位置取出anchor与targets计算的偏移值与预测值计算loss
tbox:保存anchor与targets计算的偏移值,以对应特征网格左上角为标准,中心xy范围(0~1),wh是相应的特征图尺度
anch:正样本对应的anchor模板
tcls:类别
# Appendindices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices# gxy - gij:表示的是对于网格左上角的偏移值,gwh:targets的宽高,没做什么处理tbox.append(torch.cat((gxy - gij, gwh), 1)) # box,偏移值anch.append(anchors[a]) # anchorstcls.append(c) # classreturn tcls, tbox, indices, anch
代码
def build_targets(self, p, targets):'''P:predict->[检测层数,ANCHOR个数,gridspace长,gridspace宽,类别数+5(xywh+obj)], target:[num_target,image_index+class+xywh]'''# Build targets for compute_loss(), input targets(image,class,x,y,w,h)na, nt = self.na, targets.shape[0] # number of anchors, targets,na正常都为3tcls, tbox, indices, anch = [], [], [], [] # 用来存放结果的gain = torch.ones(7, device=self.device) # normalized to gridspace(就是输出的检测特征层大小) ,保存放缩到特征图大小的因子# ai:[3,nt],每个target对应的anchor索引,方便下一句的ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt),# cat([3,nt,6],[3,nt,1],dim=2)->[3,nt,7] nt:num_targets,增加anchor索引targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices,复制3份对应3个anchor# [num_anchor,num_target,image_idx+class+xywh+anchor_idx]g = 0.5 # bias,偏移值off = torch.tensor( # 坐标偏移值分别对应中心点、左、上、右、下[[0, 0],[1, 0],[0, 1],[-1, 0],[0, -1], # j,k,l,m# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm],device=self.device).float() * g # offsets,g=0.5,变为偏移值为0.5for i in range(self.nl): # 遍历每个检测层anchors = self.anchors[i] # 获取第i个模板的anchor# gain = [1, 1, 特征图w, 特征图_h, 特征图w, 特征图_h]gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain,放缩因子# Match targets to anchorst = targets * gain # targets为归一化的,乘以当前层尺度还原为当前层的尺度if nt: # 如果分层检测的特征层上有目标# Matchesr = t[..., 4:6] / anchors[:, None] # wh ratio# self.hyp['anchor_t']=4,根据偏移值计算公式,bw=pw(2σ(tw))^2,比值范围最好为(0,4)j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare,.max(2)[0]返回宽的比值和高的比值两者中较大的一个值# yolov5之前的方法,通过iou阈值来分配正负样本# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))# j中,符合比列要求的为true,否则为falset = t[j] # filter,[3,nt,7][3,nt]->[num_P,7],初步选择好了哪些anchors对应正样本# Offsetsgxy = t[:, 2:4] # grid xy, # 正样本的xy中心坐标gxi = gain[[2, 3]] - gxy # inverse # 特征图的长宽-targets的中心j, k = ((gxy % 1 < g) & (gxy > 1)).T # <0.5,取网格中偏向于左,上的target为truel, m = ((gxi % 1 < g) & (gxi > 1)).T # 取网格中偏向于右,下的target为truej = torch.stack((torch.ones_like(j), j, k, l, m)) # 中心加左,上,右,下,五个# [num_P,7]->[5,num_P,7][5,num_P]->[num_P+,7],取出所有对应为true的target信息# 有重复的,但是后面会减去相应的偏移值,来定义更多的正样本,进而扩充正样本数量t = t.repeat((5, 1, 1))[j] # 复制五份,取出对应位置的target信息# [1,num_P,2]+[5,1,2]->[5,num_P,2],初始化坐标值,表示后面正样本经过每个偏移方向后的坐标# [5,num_P,2][5,num_P]->[num_P+,7],符合上面所说的每个正样本取邻近网格作为正样本偏移值的计算offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]else:t = targets[0]offsets = 0# Definebc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchorsa, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class# 正样本中心坐标减去每个方向的偏移值,对应一个正样本变成三个正样本,.long()表示以网格左上角坐标gij = (gxy - offsets).long() gi, gj = gij.T # grid indices,把坐标分离开# Appendindices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices# gxy - gij:表示的是对于网格左上角的偏移值,gwh:targets的宽高,没做什么处理tbox.append(torch.cat((gxy - gij, gwh), 1)) # box,偏移值anch.append(anchors[a]) # anchorstcls.append(c) # classreturn tcls, tbox, indices, anch
总结
yolov5使用自己的数据集相关代码
yolov5网络结构代码解读
这篇关于yolov5的正负样本的定义和匹配的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






