本文主要是介绍NLP实战学习(1):keras+LSTM实现中文新闻标题分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据集来源:https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset
共382688条15个分类的新闻。
参考代码:https://blog.csdn.net/weixin_42608414/article/details/89856566
处理数据:
每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻ID,分类code,分类名称,新闻字符串(仅含标题),新闻关键词
6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,之后她的两个行为给自己加分_!_佟丽娅,网络谣言,快乐大本营,李浩菲,谢娜,观众们
共15个分类
100 民生 故事 news_story
101 文化 文化 news_culture
102 娱乐 娱乐 news_entertainment
103 体育 体育 news_sports
104 财经 财经 news_finance
106 房产 房产 news_house
107 汽车 汽车 news_car
108 教育 教育 news_edu
109 科技 科技 news_tech
110 军事 军事 news_military
112 旅游 旅游 news_travel
113 国际 国际 news_world
114 证券 股票 stock
115 农业 三农 news_agriculture
116 电竞 游戏 news_game
对新闻进行分词并且去除停用词(停用词表),我们将处理好的标签和新闻数据存入new.csv文件,方便之后使用。
import csv
import os
import jieba
import restopwords = [i.strip() for i in open('./data/cn_stop_words.txt',"r", encoding="utf-8").readlines()]def pretty_cut(sentence):cut_list = jieba.lcut(''.join(re.findall('[\u4e00-\u9fa5]', sentence)), cut_all=True)for i in range(len(cut_list) - 1, -1, -1):if cut_list[i] in stopwords:del cut_list[i]return cut_listf = open ("./data/toutiao_cat_data.txt", "r", encoding="utf-8")
lines = f.readlines()
f.close()
with open(os.path.join("./data/news.csv"), "w", encoding="utf-8", newline='') as g:writer = csv.writer(g)writer.writerow(["label", "news"])for line in lines:x = line.strip(" ")x = line.strip("\n")y = x.split("_!_")z = " ".join(y)cut_y = " ".join(pretty_cut(z))writer.writerow([y[2],cut_y])
读取处理好的数据并随机查看:
import pandas as pd
df = pd.read_csv('./data/news.csv', delimiter=",",names=['label','news'])#将逗号分隔值(csv)文件读取到DataFrame中
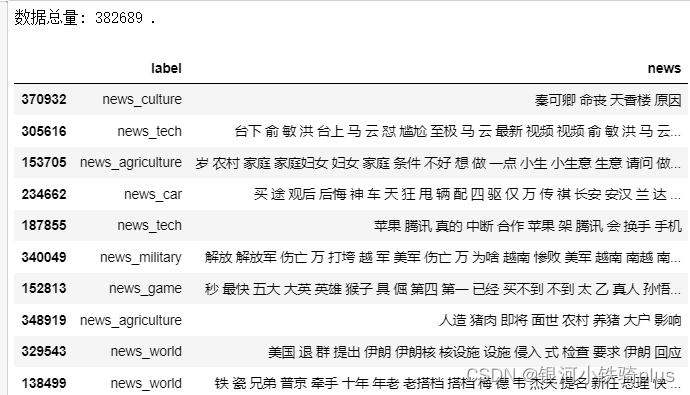
print("数据总量: %d ." % len(df))
df.sample(10)#对数据集进行抽样查看
查看并清洗空值
print("在 labek 列中总共有 %d 个空值." % df['label'].isnull().sum())#查看label列的空值
print("在 news 列中总共有 %d 个空值." % df['news'].isnull().sum())
df[df.isnull().values==True]#isnull返回一个布尔数组
df = df[pd.notnull(df['news'])]#保留非null的news
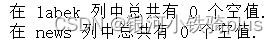
分别提取label和news:
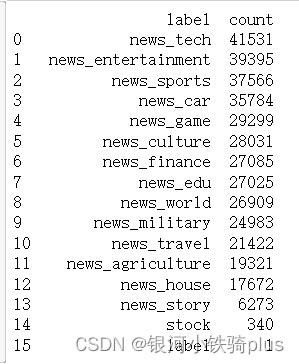
d = {'label':df['label'].value_counts().index, 'count': df['label'].value_counts()}#使用字典方法创建dataframe
df_label = pd.DataFrame(data=d).reset_index(drop=True)#数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引。
print(df_label)
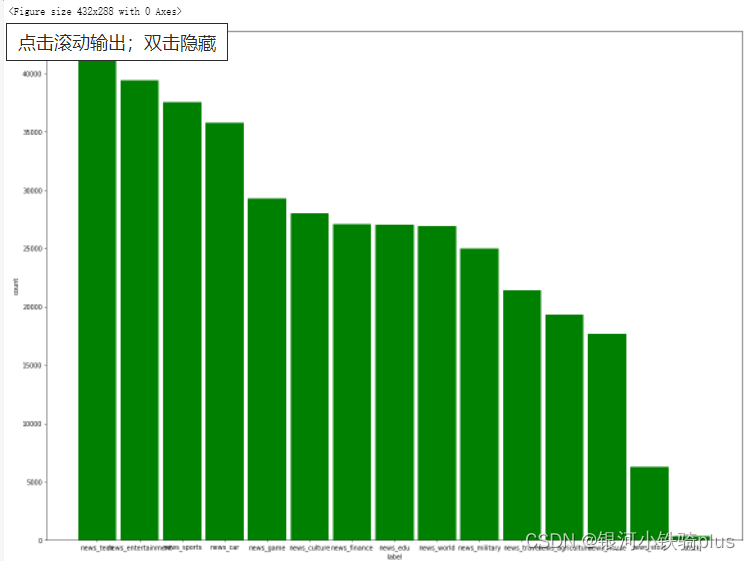
输出柱状图查看
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpllabel = [i for i in df_label["label"]]
count = [int(i) for i in df_label["count"]]
labels = label[0:-1]
count = count[0:-1]
fig = plt.figure()
plt.figure(figsize=(20,15),dpi=70)
plt.bar(labels,count,0.9,color="green")
plt.xlabel("label")
plt.ylabel("count")
plt.show()
将label类转换成id
df['label_id'] = df['label'].factorize()[0]
label_id_df = df[['label', 'label_id']].drop_duplicates().sort_values('label_id').reset_index(drop=True)
label_to_id = dict(label_id_df.values)
id_to_label = dict(label_id_df[['label_id', 'label']].values)
print(df.sample(10))

LSTM建模
- 将cut_review数据进行向量化处理,我们要将每条cut_review转换成一个整数序列的向量
- 设置最频繁使用的50000个词
- 设置每条 cut_review最大的词语数为250个(超过的将会被截去,不足的将会被补0)
from keras.preprocessing.text import Tokenizer
MAX_NB_WORDS = 50000 # 设置最频繁使用的50000个词
MAX_SEQUENCE_LENGTH = 250 # 每条cut_news最大的长度
EMBEDDING_DIM = 100 # 设置Embeddingceng层的维度
#num_words: 保留的最大词数,根据词频计算,保留前num_word - 1个
tokenizer = Tokenizer(num_words=MAX_NB_WORDS, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~', lower=True)
tokenizer.fit_on_texts(df['news'].values)
word_index = tokenizer.word_index
print('共有 %s 个不相同的词语.' % len(word_index))from keras.preprocessing.sequence import pad_sequences
X = tokenizer.texts_to_sequences(df['news'].values)
#经过上一步操作后,X为整数构成的两层嵌套list
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
#经过上步操作后,此时X变成了numpy.ndarray
#多类标签的onehot展开
Y = pd.get_dummies(df['label_id']).valuesfrom sklearn.model_selection import train_test_split
#拆分训练集和测试集,X为被划分样本的特征集,Y为被划分样本的标签
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.10, random_state = 42)import tensorflow as tf
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(MAX_NB_WORDS, EMBEDDING_DIM, input_length=X.shape[1]))
model.add(tf.keras.layers.SpatialDropout1D(0.2))#dropout会随机独立地将部分元素置零,而SpatialDropout1D会随机地对某个特定的纬度全部置零
model.add(tf.keras.layers.LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(tf.keras.layers.Dense(16, activation='softmax'))#输出层包含15个分类的全连接层,激活函数设置为softmax
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
开始训练:设置5个训练周期,batch_size=64
from keras.callbacks import EarlyStopping
epochs = 5
batch_size = 64 #指定梯度下降时每个batch包含的样本数
#callbacks(list),其中元素是keras.callbacks.Callback的对象。这个list的回调函数将在训练过程中的适当时机被调用
#validation_split指定训练集中百分之十的数据作为验证集
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size,validation_split=0.1,callbacks=[EarlyStopping(monitor='val_loss', patience=3, min_delta=0.0001)])
model.save(r'./model.h5')#保存模型
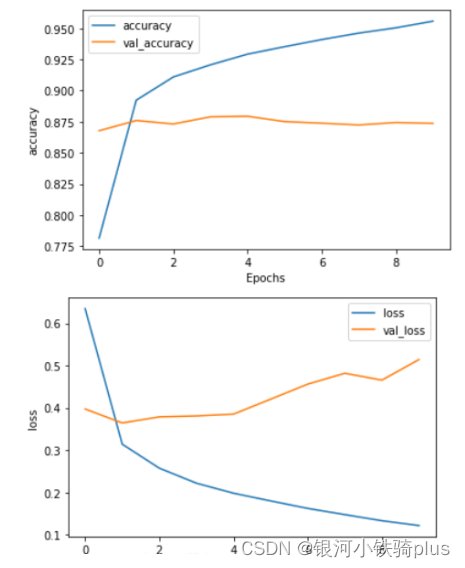
查看loss和acc曲线:
def plot_graphs(history, string):plt.plot(history.history[string])plt.plot(history.history['val_' + string])plt.xlabel("Epochs")plt.ylabel(string)plt.legend([string, 'val_' + string])plt.show()plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
预测两条新闻:
#预测两条新闻
def Predict(text):txt = pretty_cut(text)seq = tokenizer.texts_to_sequences(txt)padded = pad_sequences(seq, maxlen=MAX_SEQUENCE_LENGTH)pred = model.predict(padded)label_id= pred.argmax(axis=1)[0]print(text + " : " + label_id_df[label_id_df.label_id==label_id]['label'].values[0])
Predict("腾讯发布“00后画像报告” 颠覆我们对这一代的认知 00后,00后画像报告,腾讯,大数据,腾讯QQ")
#腾讯发布“00后画像报告” 颠覆我们对这一代的认知 00后,00后画像报告,腾讯,大数据,腾讯QQ : news_tech
Predict("教师招聘重要考点备考之中国古代教育专题 有教无类,孔子,九品中正制,科举制,察举制")
#教师招聘重要考点备考之中国古代教育专题 有教无类,孔子,九品中正制,科举制,察举制 : news_edu
在测试集上做预测:
#预测测试集
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
y_pred = model.predict(X_test)
y_pred = np.argmax(y_pred, axis=1)
Y_test=np.argmax(Y_test, axis=1)#将one-hot编码转换为整数
print('accuracy %s' % accuracy_score(y_pred, Y_test))
print(classification_report(Y_test, y_pred,target_names=[str(w) for w in labels]))

完整代码和数据可查看
这篇关于NLP实战学习(1):keras+LSTM实现中文新闻标题分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






