本文主要是介绍0.3、sql 获取表中每一个分组中的第一条数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 问题描述
- 测试表结构
- 插入一下数据
- 提出需求
- 问题解决
- 拓展-根据id最简单
- 总结
问题描述
对于 SQL 搜索有一种场景尽管很少遇到,但是不可避免,就是对于数据进行分组,并且获取每一个分组中第一条数据。
本文给出可行的解决方案。
测试表结构
表字段主要是 id、name、type、date
create table test
(id bigint auto_incrementprimary key,name varchar(20) not null,type int not null,date datetime null
);
插入一下数据
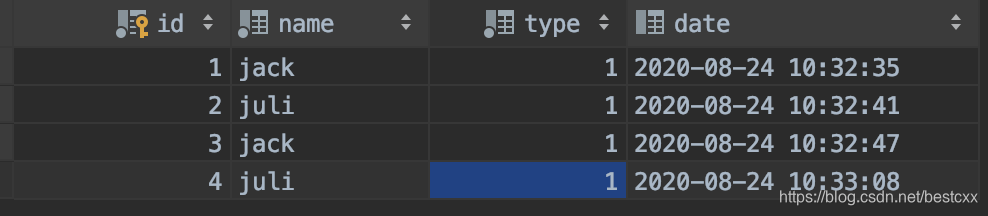
提出需求
获取 type=1,获取 name 和其对应的最早的 date值
问题解决
group by 之后无法获得差异化数据,所以可以先获取唯一id,然后通过多次套用的方式来解决。
即,根据 name 和 date 做第一次分类,组成临时表。
然后对这个临时表做第二次分类,获取每一类的的第一条数据
select name,min(date) from (select name, datefrom testwhere type = 1group by name, date)tem
group by name拓展-根据id最简单
如果我们需要获取整条数据,则可以使用 分组+id
select * from test where id in (select min(id)from testwhere type = 1group by name)
总结
group by 支持 对一个字段做分类,然后最另一个字段做条件处理。
只要确保每次处理分类字段+该分类下唯一区分条件字段 即可不断缩小数据范围。如果最后得出的数据是主键值,则可以返回来获取完整数据行的值。
这篇关于0.3、sql 获取表中每一个分组中的第一条数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





