本文主要是介绍论文阅读:基于循环神经网络的船舶航迹预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读:基于循环神经网络的船舶航迹预测
论文下载:https://download.csdn.net/download/qq_33302004/15421819
目录
1. 摘要
2. 主要贡献
3. 一些有趣的观点
4. 基于SSPD的数据预处理方法
5. GRU循环神经网络预测模型
6. 实验
1. 摘要

2. 主要贡献
提出了一种基于循环神经网络的船舶航迹预测方法,主要包含两个部分:数据预处理(SSPD)和循环神经网络预测模型,算法流程如下:
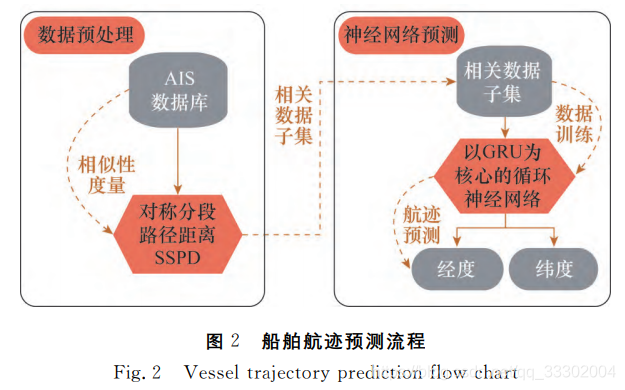
实验结果:平均计算耗时111.031s,平均误差为0.374%(采用均方误差,MSE)。
3. 一些有趣的观点
① 针对船舶航迹预测问题:研究集种于某海域给定时间范围内遵循一定规律的特定船舶类型的航迹预测问题。
航迹预测问题十分复杂,会受到不同海域、不同类型的船舶、不同天气等众多因素的影响,我认为研究特定的问题是一个好的选择。
② 使用SSPD方法选择出与待预测的航迹相似的航迹作为训练集。
不遵循相同规律的航迹,若不作处理都直接作为训练集会增加神经网络模型的学习难度,甚至还会出现自相矛盾的数据,导致不收敛,所以提前筛选数据集有必要。
③ AIS数据中的位置坐标是非平面坐标,所以作者对原始的坐标数据做了“高斯-克吕格”投影。
这是我之前没有遇到过的做法,后面也会深入研究一下AIS的原始坐标数据获取方式和是否做投影对预测结果的影响。
4. 基于SSPD的数据预处理方法
问题描述:

其中p是一个航迹点,用经纬度对表示。T是一段航迹,有若干(航迹点, 时刻)组成。

是用线段方式表示的轨迹,
表示点
和点
连接组成的线段,
表示航迹T的总长度
相似度计算(SSPD的过程):

上面的公式是在计算一个点p到线段s的距离,方法就是由p点向s做投影,如果落在s上,那么就将p点和投影点连线的长度作为点到线段的距离;否则就用p连接线段的两个端点,较短的连接线的长度作为距离。

点p到航迹的距离就是,点p到航迹T中每条线段距离的最小值。而航迹
到航迹
的距离就是
中每个点到航迹
距离的平均值。

所谓对阵分段路径距离也就是相似度,就是两条航迹相互距离的平均值。,的值越小,航迹之间的相似性程度越高; 反之,相似性程度越低。
筛选数据集的算法伪代码如下:

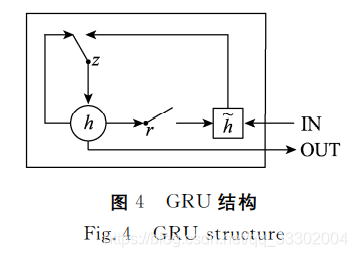
5. GRU循环神经网络预测模型
RNN网络结构:
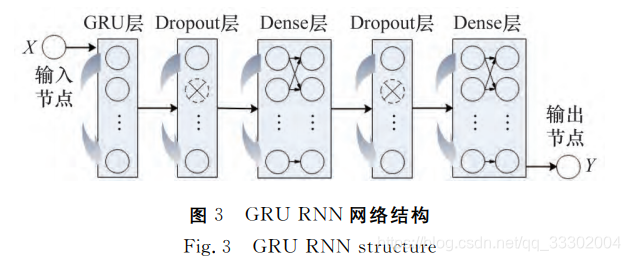
其中Dropout概率取0.2,Dense层就是全连接层。
模型结构包括1个输入节点,5个隐藏层,及1个输出节点。输 入节点接收序列 X 的长度为n,维度为2(即船舶的经度和 纬度坐标),通过隐藏 层 训 练,在输出节点获得最佳预测序 列Y,包括预测位置的经纬度坐标。

每一个神经元是一个GRU,每层神经元个数为100个
6. 实验
使用AIS数据,下载了2017年1~2月在通用横墨卡 托区域1~10范围内航行的商用及民用 类型的船舶共计719624条真实航迹数据。分为10组,每组约71000条数据。
实验结果:


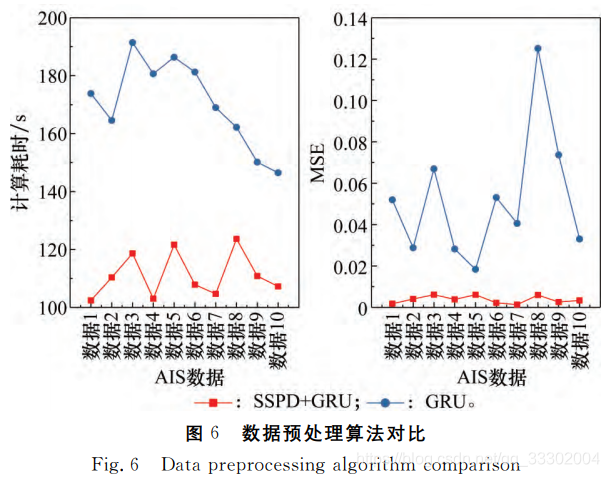
使用SSPD筛选数据和不使用的对比实验:
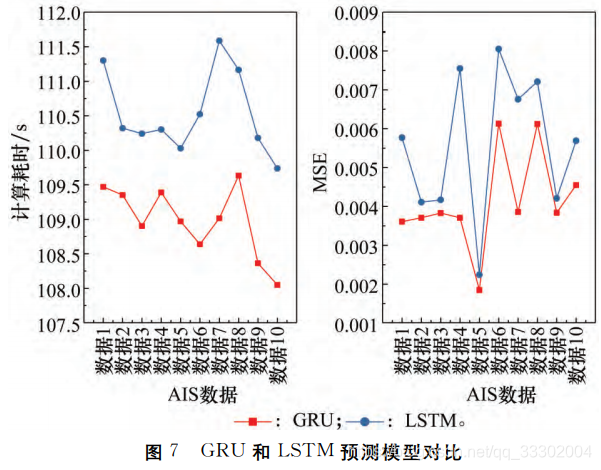
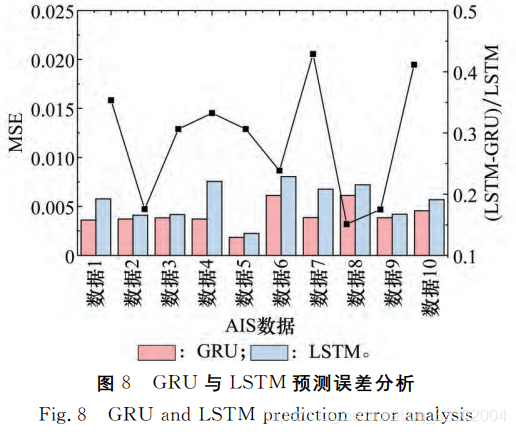
GRU神经元和LSTM神经元的对比实验:
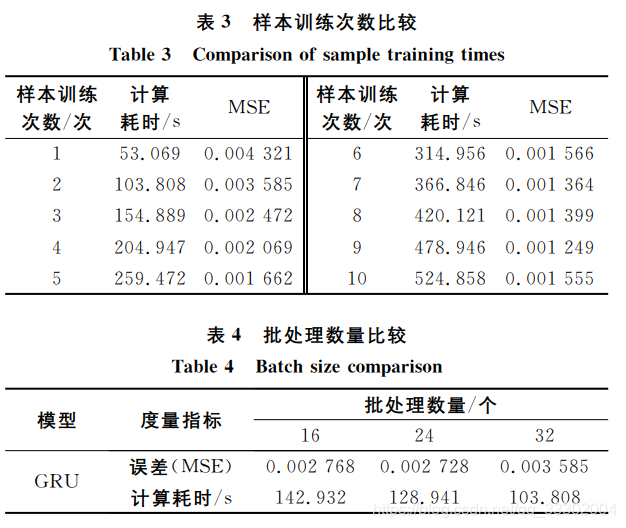
不同训练参数的对实验:

这篇关于论文阅读:基于循环神经网络的船舶航迹预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





