本文主要是介绍Kmeans原理实现——(python实现包含手肘法,kmeans++,降维可视化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、总代码呈现
#n为样本数目
#m为特征数目
#k为簇心数目#导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import copy as cp
from sklearn.decomposition import PCA#计算欧几里得距离
def Eucl_distance(array_x,array_y):return np.sum(np.square(array_x.reshape(1,-1) - array_y.reshape(1,-1)))#手肘法
def elbow_k(data):#通过计算代价函数(或畸变函数)来确定K值#吴达恩机器学习课上,k一般小于十类k_cost=[]for k in range(1,11):final_center,belong=k_means(k)cost=costfunc(final_center,data,k,belong) k_cost.append(cost)#x,y参数可以是标量,也可以是类似数组的数据结构(列表,numpy数组,pandas dataframe等) plt.plot(np.array([i for i in range(1,11)]),np.array(k_cost),c='green') #在点的最大值与最小值范围间随机给出随机簇心
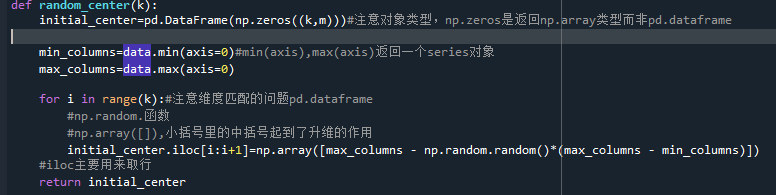
def random_center(k):initial_center=pd.DataFrame(np.zeros((k,m)))#注意对象类型,np.zeros是返回np.array类型而非pd.dataframemin_columns=data.min(axis=0)#min(axis),max(axis)返回一个series对象max_columns=data.max(axis=0)for i in range(k):#注意维度匹配的问题pd.dataframe#np.random.函数#np.array([]),小括号里的中括号起到了升维的作用initial_center.iloc[i:i+1]=np.array([max_columns - np.random.random()*(max_columns - min_columns)])#iloc主要用来取行return initial_center#代价函数
def costfunc(array_cent,data,k,book):#最终每一个簇心与每一个样本距离的和Sum_cost=0for i in range(k):for j in range(n):#对每一个簇心的每一个样本if i == book[j][0]:Sum_cost+=Eucl_distance(array_cent[i:i+1],data.iloc[j:j+1].values)return Sum_costdef k_means(k):initial_center=kpp_center(k)final_center=np.zeros((k,m))error=0.0001distance=0belong=np.zeros((n,1))#确定每一个样本归属与哪一类ifchange=Truewhile ifchange:ifchange=Falsetem_center=cp.deepcopy(initial_center)for j in range(n):min_dist=float('inf')for i in range(k):distance=Eucl_distance(initial_center.iloc[i:i+1].values,data[j:j+1].values)if distance < min_dist:min_dist=distancebelong[j][0]=i#重新分布簇心for i in range(k):Sum = 0center=np.zeros((1,m))for j in range(n):if belong[j][0] == i:Sum+=1center+=data.iloc[j:j+1].valuesif Sum != 0:for h in range(m):tem_center.iloc[i,h] = center[0][h]/Sumelse:continue#为簇心的移动设置误差for i in range(k):if Eucl_distance(tem_center.iloc[i:i+1].values,initial_center.iloc[i:i+1].values) > error:ifchange=Trueinitial_center.iloc[i:i+1] = tem_center.iloc[i:i+1]for i in range(k):final_center[i:i+1]=tem_center.iloc[i:i+1]return final_center,belongdef kpp_center(k):initial_center = pd.DataFrame(np.zeros((k,m)))#确定第一个随机簇心index = np.random.randint(1,n)initial_center.iloc[0,:] = np.copy(data.iloc[index,:])for i in range(k):dist = []for j in range(n):#每一个样本与已知初始簇心们的最小距离dist_temp=nearest_dist(data.iloc[j,:],initial_center.iloc[0:i,:])dist.append(dist_temp)Sum = sum(dist)#确定基准概率base_pro = np.random.random()#将距离列表转换为概率列表dist = [i/Sum for i in dist]#轮盘法for j ,value_j in enumerate(dist):if base_pro < value_j:initial_center.iloc[i,:] = np.copy(data.iloc[j,:])breakelse:base_pro = base_pro - value_jreturn initial_centerdef nearest_dist(data_series,initial_center):min_dist=float('inf')lenth=initial_center.shape[0]for i in range(lenth):temp = Eucl_distance(np.array(data_series),initial_center.iloc[i,:].values.reshape(1,-1))if temp < min_dist:min_dist = tempreturn min_distdef PCA_datas(x):dataMat = np.array(x)pca_sk = PCA(n_components=2)#利用PCA进行降维,数据存在newMat中newMat = pca_sk.fit_transform(dataMat)newMat = pd.DataFrame(newMat)return newMat def portion_visualize(k_final,final_data,final_center):
# =============================================================================
# x_center=final_center[:,2]
# y_center=final_center[:,1]
# plt.scatter(x_center,y_center,c='red')
# =============================================================================res=['green','blue','pink','yellow','black','violet']for i in range(k_final):xy_data = final_data[final_data[m] == i]x_data = xy_data.iloc[:,1].values.reshape(1,-1)y_data = xy_data.iloc[:,1].values.reshape(1,-1)plt.scatter(x_data,y_data,c=res[i])plt.show()return 0 def visualize(k_final,final_data,final_center):
# =============================================================================
# x_center=final_center.iloc[:,0]
# y_center=final_center.iloc[:,1]
# plt.scatter(x_center,y_center,c='red',marker = 'x')
# =============================================================================res=['green','blue','pink','yellow','black','violet']for i in range(k_final):xy_data = final_data[final_data[2] == i]x_data = xy_data.iloc[:,0].values.reshape(1,-1)y_data = xy_data.iloc[:,1].values.reshape(1,-1)plt.scatter(x_data,y_data,c=res[i])plt.show()return 0#导入数据
data=pd.read_table("D:\date engineering\pythonstudy\k-means\Vowel.txt",header=None,sep=',')
n=data.shape[0]
m=data.shape[1]
# =============================================================================
# elbow_k(data)#先运行这个确定k值
# =============================================================================k_final=int(input('所以你选择多少为最终k值?'))
final_center,belong=k_means(k_final)
belong = pd.DataFrame(belong)
final_data = pd.concat([data,belong],axis=1,join='inner',ignore_index=True)
#选取两列数据进行画图呈现
portion_visualize(k_final,final_data,final_center)
data=PCA_datas(data)
final_center = PCA_datas(final_center)belong = pd.DataFrame(belong)
data = pd.DataFrame(data)final_data = pd.concat([data,belong],axis=1,join='inner',ignore_index=True)#降维后实现可视化visualize(k_final,final_data,final_center)2.1 对kmeans算法的理解
(1)kmeans算法基本介绍:
kmeans算法是无监督学习中经典的分类算法,且仍具有相当多的优点。Kmeans算法的基本思想是:在空间样本点中选取k个簇心,对簇心周围的点进行归类,同时更新簇心至整个簇的中心。通过迭代,使簇心的位置收敛,呈现出最好的分类效果。
(2)kmeans算法优缺点:
优点:
①:原理简单,实现容易,收敛速度快
②:当结果簇是密集的,而簇与簇之间区别明显时,他的效果好
③:主要需要调节的参数仅仅时簇数k
缺点:
①:K值需要预先给定,很多情况下K值是很难估计的
②:对于初始选取的质心是敏感的,不同的初始簇心得到的聚类结果完全不同,对结果影响大
③:采用迭代的方法,可能只能得到局部的最优解,而无法得到全局的最优解
(3)kmeans算法步骤:
Ⅰ.在实验样本中选出k个初始簇心;
Ⅱ.将离簇心近的样本划分为同一类;
Ⅲ.由分类的结果对簇心进行重新分类;
Ⅳ若簇心尚未收敛,则重复Ⅱ、Ⅲ步骤;
Ⅴ对分好的簇进行可视化处理。
2.2 kmeans算法的实现步骤
Ⅰ.Kmeans算法需要首先获得一个初始簇心,这里实现分治化管理,创立了随机簇心函数。随机簇心的实现也很简单,我在样本中的每一维特征中的最小值与最大值之间随机选取了一个值,这里利用了min()与max(),random.random()函数,将他们组合k次成为初始簇心。在之后的kmeans优化中我会对给出初始簇心的方法进行优化,也就是kmeans++算法
Ⅱ.在判断周围哪些点属于某一簇时,我们会计算距离,通过这个距离来衡量哪些簇心离某一样本点更近,这里通俗的距离衡量公式是欧式距离,也是空间点之间的距离
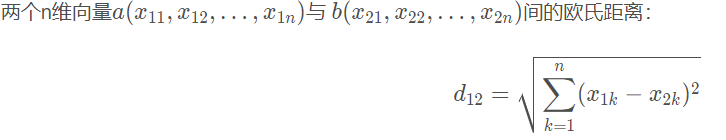

这里我并没有除以根号,因为在kmeans中只需比较距离之间的大小,且后面代价函数的计算中会运用到欧式距离的平方和。
Ⅲ在上一步骤中我们用到了kmeans算法,在这我们给予详细说明:
初始化变量
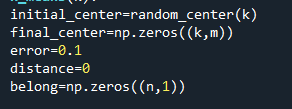

在这里对每一个样本,初始化最小距离为无穷大,然后得出该样本离哪个簇心最近,并记录该样本属于哪个簇心。最终得知一个簇中有哪些样本。

在这一步对簇心进行重新分布,并以簇内样本平均值的方式实现。也就是遍历每一个簇心下的每一个样本,判断其所属的类。这里格外的要注意,可能一个簇中一个样本点都没有,这可能会在分布簇心时导致除零错误。因此对该情况进行了考虑,增强了程序的健状性。
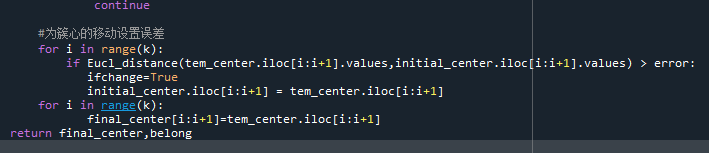
那么我们如何判断是否需要再对簇心进行重新分布了呢?也就是判断簇心什么时候收敛,在这里我们以簇心的移动距离为判断依据。因此我们需要之前未移动的簇心与移动后的簇心作比较,所以在之前的代码中都是对tem_center进行移动,在最后再将tem_center赋值给initial_center。如果收敛了,则将tem_center赋值到final_center中。

完整代码如上,以上的kmeans步骤中我们会反复进行,因此以判断簇心是否收敛时的ifchange作为变量来判断是否停止循环。
Ⅳ最后对分类后的点进行可视化处理,设置了portion_visualize函数

在这里对最终的数据选取了两列进行了二维可视化处理,最终数据是数据与belong数据的合并形式,可以反应每个样本隶属于哪个簇心。并且设置了颜色res列表,当簇数量小于6个时可以依次选取res列表中的颜色对簇进行上色。
2.3.1 kmeans初始簇心优化
Ⅰkmeans++算法介绍
在之前的kmeans缺点中提到过,kmeans对初始簇心的敏感度很高,一个好的初始簇心往往能对kmeans的效果有很大的提升。而好的初始簇心,是以簇心与簇内点的距离尽可能小,同时簇与簇之间距离尽可能大来实现的。这里介绍kmeans++算法,它是专为给出较优的初始簇心而设计的。
(1)在样本中随机选取一个样本作为初始簇心
(2)判断其他样本是否能作为簇心:
- 计算每个样本到离它最近的簇心的距离。该距离越大,则说明该样本越可能成为新簇心。(因为好的初始簇心要求簇心与簇心之间的距离尽可能大,而若某一样本距离它最近的簇心的距离都尽可能大,则说明该样本越可能成为新簇心。至于为什么不直接选取最远样本为新簇心会在后面提及)
- 以距离相对大小为概率的大小,同时使用轮盘法实现对概率的随机选择。(轮盘法的实现:在0-1之间随机选取一小数作为基准概率,依次判断所有样本,若样本的被选择概率大于基准概率,则选择该样本,反之,则将基准概率减去该样本的选择概率并继续判断,直到选择出一个新簇心。)
- 当选择完新一个新簇心后,重新计算各个样本被选择的概率,并继续随机选择,直到选择出全部的初始簇心。
Ⅱ kmeans++算法说明:
- 该算法的特点便是能以概率的形式来选取较优簇心。而之所以不直接选取距离最大的点为新簇心,是因为想确保新簇心选取的随机性,使得概率大的样本被选取的概率大,概率小的样本被选取的概率小,而不是直接选取最大概率的样本,这样就不会每次选取同样的样本作为新簇心。
- 对轮盘法原理的个人理解:
轮盘法的原理为顺序判断样本被选择与基准概率大小的关系,但由于是顺序判断样本,导致靠前的样本更容易被选择而使随机选择的性质并不能实现,所以数学方法上使基准概率会在每次更新时减去之前的样本概率,从而消除这种影响,当进行下一样本的判断时也能保持随机选择的性质。
Ⅲ kmeans++算法实现
def kpp_center(k):initial_center = pd.DataFrame(np.zeros((k,m)))#确定第一个随机簇心index = np.random.randint(1,n)initial_center.iloc[0,:] = np.copy(data.iloc[index,:])for i in range(k):dist = []for j in range(n):#每一个样本与已知初始簇心的距离总和dist_temp=nearest_dist(data.iloc[j,:],initial_center.iloc[0:i,:])dist.append(dist_temp)Sum = sum(dist)#确定基准概率base_pro = np.random.random()#将距离列表转换为概率列表dist = [i/Sum for i in dist]#轮盘法for j ,value_j in enumerate(dist):if base_pro < value_j:initial_center.iloc[i,:] = np.copy(data.iloc[j,:])breakelse:base_pro = base_pro - value_jreturn initial_center- 确定一个随机样本作为第一个簇心,这里采用randint随机索引来实现

在计算每个样本被选择的概率时,将每个样本依次与已确定的簇心们计算其中的最小距离。这里构建了nearest_dist函数来实现。一个简单的判断最小距离的函数如下:
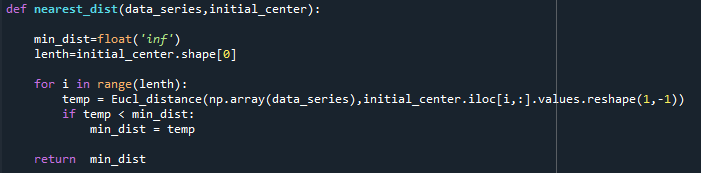
然后将每个样本的“最小距离”给整理为一个列表,再将该列表转换为每个样本被选择的概率形式。
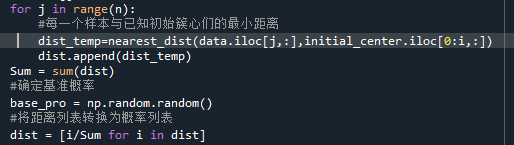
最后使用轮盘法实现概率选择。
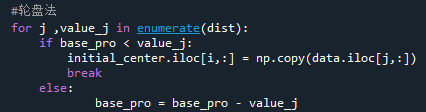
2.3.2 kmeans主成分分析可视化优化
Ⅰ 简单介绍主成分分析:


Ⅱ主成分算法PCA的调库使用

选取两列数据进行可视化

将数据整体降维后进行可视化。可以看出,这样对分类的观察效果更好了。

2.3.3 手肘法优化簇心个数k
当没有明确的分类需求时,在确定kmeans的参数k时可以用到的方法有手肘法与轮廓系数法,通常,当两者给出结果不一样的时候我们采取手肘法的结果。
手肘法是通过计算kmeans在不同k值得到的簇的优劣程度来给出一张关于k值与簇优劣程度的图.Kmeans算法一般是将样本分为一到十类。一般的,随着k值增加,簇肯定会越分越细越来越精准,但这就不符合我们将样本分类的本意了。所以,我们选择当簇优劣程度不再大幅下降时的簇数作为k值,由于图像不再大幅下降时的K值像手臂上的手肘,因此称为手肘法。而簇的优劣程度表现为每个簇中的点与簇心距离的平方相加,再将每个簇的总距离相加,这表现为该模型的好坏,在机器学习中把这种函数称为代价函数,也就是当代价函数最小时,一般获得模型的较优解。

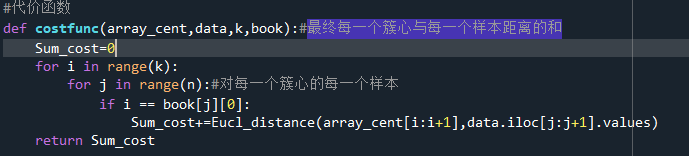
在此处将每个k值对应的代价得到并附加在空列表上,最终画出折线图。
2.4 kmeans算法的测试(五个数据集)
处理Blood数据集

手肘法判断簇心应该为4

处理cancer数据集

由手肘法判断k值应该取2

处理Vowel数据集

似乎几个数据集测试的效果不一,有的数据集分类的效果显著,例如Vowel,Blood,也有的感觉分3类也好,分两类也好,例如cancer,但这个时候一般就会需要我们来考虑分类的实际应用场景了,比如若判断一个人有没有癌症,那当然就是分两类最佳。
实验分析
Ⅰ 编写程序需要注意:
- 使用自定义函数时应尽可能将函数会用到的参数全部导入,避免使用全局变量,这样会导致调试时分不清在哪个函数里改变了变量。
- Python报错并不会十分严格,有时候你的函数参数传递只要不是形成了严格的错误,就不会报错,这要求在使用函数时你应该确保达到了你想要的效果。
Ⅱ使用pandas和numpy库时需注意:
- 一些numpy库中的函数使用对象只能是ndarray类型,因此可以将dataframe类型数据用.values处理成array类型,在对array维度有要求时,还可以用reshape
()函数对array进行维度重组。 - Pandas库中的series和dataframe与numpy库中的array索引方式不同
- Dataframe与series可以用ndarray来填充,但是必须得保持两者得维度一致——也就是dataframe需要用二维的array类型来填充,例如在代码中使用了np.array([])函数,可以将一维的array类型提升至二维。
这篇关于Kmeans原理实现——(python实现包含手肘法,kmeans++,降维可视化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




