本文主要是介绍百家号个人账号爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
百家号爬虫
爬取内容:个人账号下的全部内容
爬取步骤
一开始用request库发现得不到数据,访问页面的时候加了一层通行证类似的东西。
所以选择用Selenium模拟浏览器的操作。
1、用Selenium模拟打开需要爬取的个人页面
# 创建一个浏览器实例
driver = webdriver.Chrome()
# 打开网站
driver.get("https://author.baidu.com/home/92")
成功打开网页后,F12打开开发者工具,页面不断往下滑发现前端页面是异步加载,那么前端一定会有新的请求发送给后端,得到新数据后在前端渲染出来。
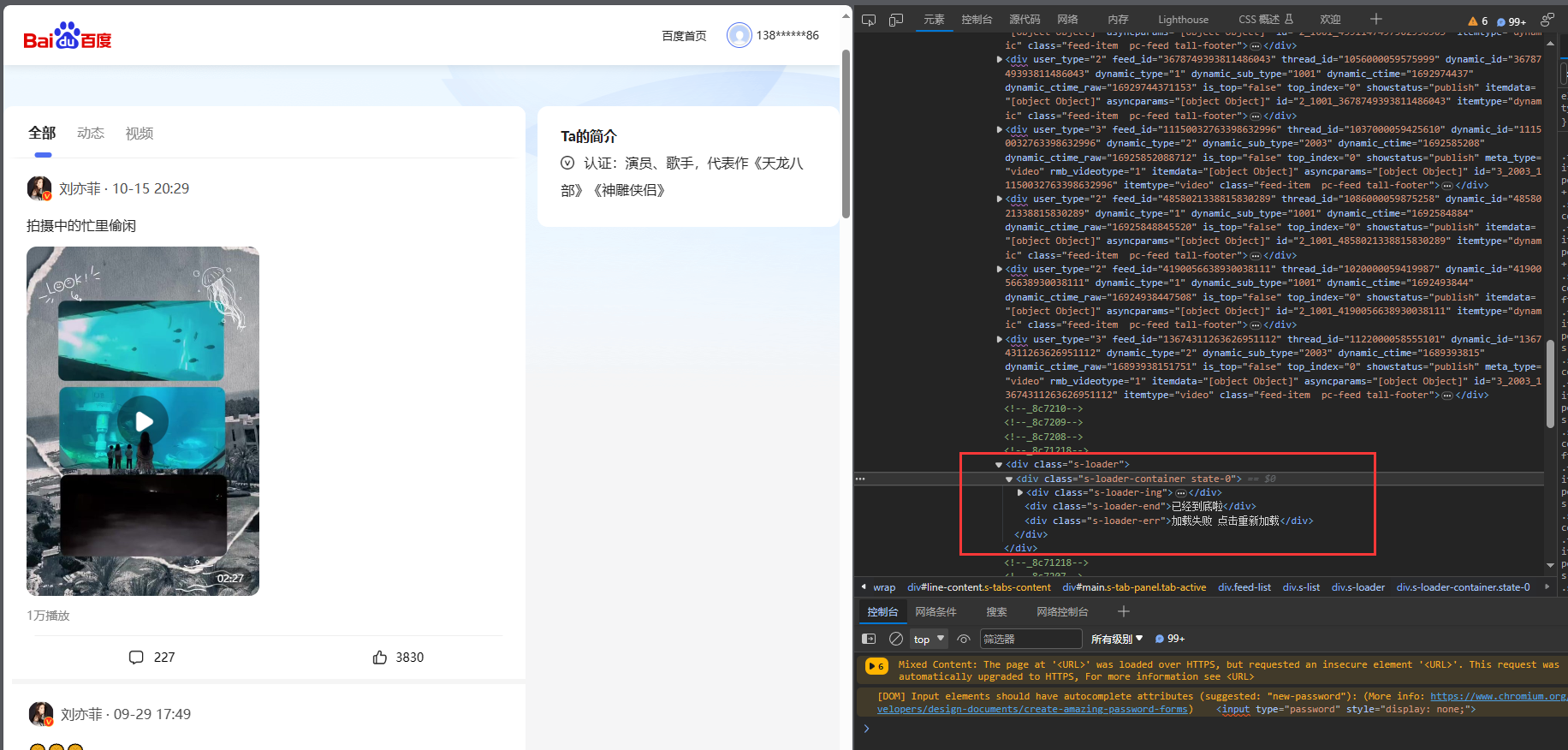
2、找到前后端交互数据的请求
找到响应的请求
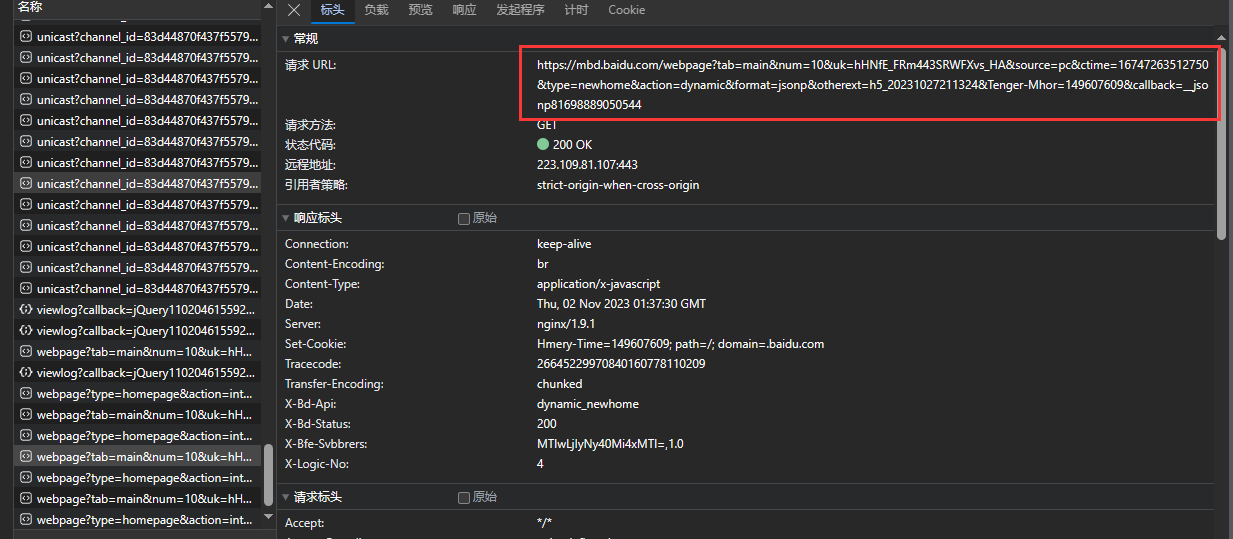
可以看到响应内容主要是包含动态的一个列表,那么这就是我们需要的
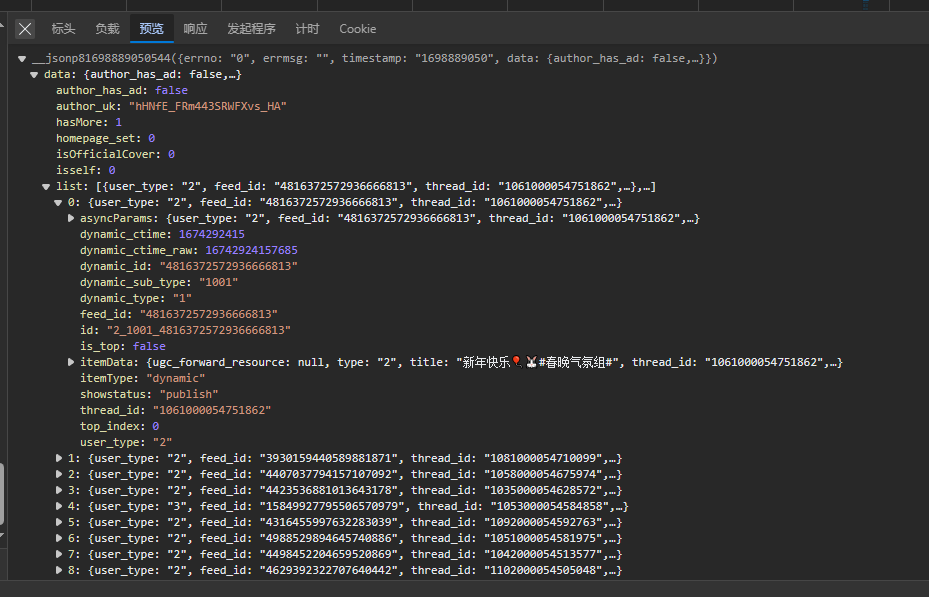
缩减请求URL,通过每次删除一个参数,对比结果,得到一个较短的URL地址
https://mbd.baidu.com/webpage?tab=main&num=10&uk=hHNfE_FRm443SRWFXvs_HA&source=pc&ctime=16747263512750&type=newhome&action=dynamic&format=jsonp&otherext=h5_20231027211324&Tenger-Mhor=149607609&callback=__jsonp81698889050544
缩减后请求URL
https://mbd.baidu.com/webpage?tab=main&num=10&uk=hHNfE_FRm443SRWFXvs_HA&ctime=16747263512750&type=newhomeformat=jsonp
主要参数分析:
- num:每次返回的动态内容的条数
- uk:要爬取用户的唯一标识
- ctime:动态的标识,表示获取内容从当前动态开始,往后num条(当没有ctime参数时默认从第一条动态开始)
从哪里获取这些参数来构造一个新的请求呢?
UK值的获取
在页面元素中搜索当前用户的uk值“hHNfE_FRm443SRWFXvs_HA”,发现包含在body的script标签中
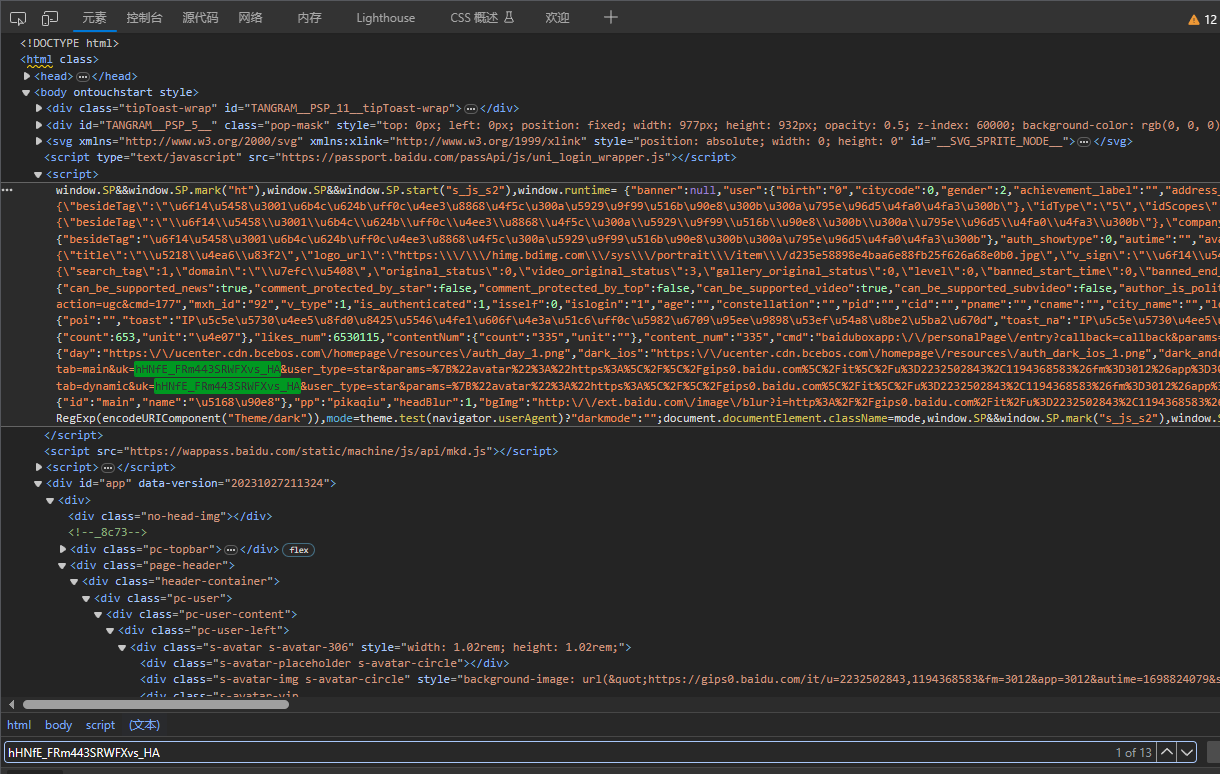
获取UK代码
headContainer = driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div/div/div/div[2]/h2")
scriptContainer = driver.find_element_by_xpath("/html/body/script[2]")
scriptHTML = scriptContainer.get_attribute("innerHTML")
ukSet = set(s for s in scriptHTML.split("&") if s.startswith("uk"))
uk = ukSet.pop().split("=")[-1]
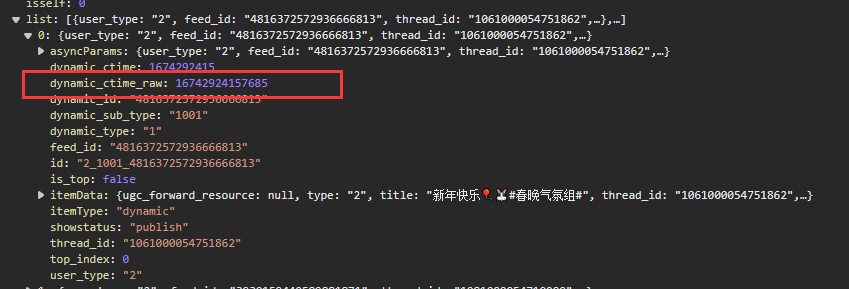
ctime值的获取
对于ctime的获取,就是请求响应中dynamic_ctime_raw的值
3、用Selenium模拟地址栏输入访问请求
知道这些主要参数后,就可以构造新的请求,用Selenium模拟打开这个请求
# 模拟在地址栏输入URL
script = 'window.location.href = "https://mbd.baidu.com/webpage?tab=main&num=10&uk= {}&ctime{}&type=newhome&action=dynamic&format=jsonp"'.format(uk, ctime)
driver.execute_script(script)
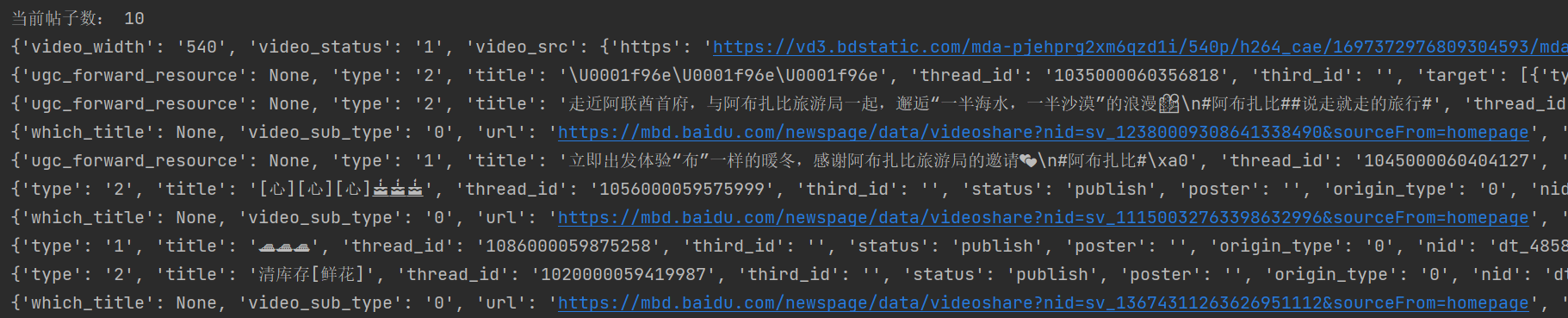
4、爬取结果
里面包含了动态的标题,点赞,评论,图片或视频链接
源代码
import json
import timefrom selenium import webdriver# 创建一个浏览器实例
driver = webdriver.Chrome()
# 打开网站
driver.get("https://author.baidu.com/home/92")headContainer = driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div/div/div/div[2]/h2")
scriptContainer = driver.find_element_by_xpath("/html/body/script[2]")
scriptHTML = scriptContainer.get_attribute("innerHTML")
ukSet = set(s for s in scriptHTML.split("&") if s.startswith("uk"))
uk = ukSet.pop().split("=")[-1]ctime = ""while 1:# 模拟在地址栏输入URLscript = 'window.location.href = "https://mbd.baidu.com/webpage?tab=main&num=10&uk={}&ctime={}&type=newhome&action=dynamic&format=jsonp"'.format(uk, ctime)driver.execute_script(script)jsonp_str = driver.find_element_by_xpath("/html/body/pre")jsonp_str = jsonp_str.text# 提取JSON数据start_index = jsonp_str.index('(') + 1end_index = jsonp_str.rindex(')')json_str = jsonp_str[start_index:end_index]# 将JSON字符串转换为Python对象data = json.loads(json_str)# 输出转换后的Python对象postList = data["data"]["list"]print("当前帖子数:", len(postList))if len(postList) == 0:print("爬取完毕!!!")breakfor postItem in postList:ctime = postItem["dynamic_ctime_raw"]itemData = postItem["itemData"]print(itemData)这篇关于百家号个人账号爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!