本文主要是介绍强化学习-你在游戏中对战的人机是如何对付你的!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.与环境交互的数据介绍
2.要完成的目标分析
3.baseline方法
4.Onpolicy与Offpolicy策略。
在前面我写了一篇文章叫《强化学习-什么是强化学习?白话文告诉你!》这篇文章用了很通俗易懂的例子介绍了强化学习的一些基本的知识点。
读完上面的文章,再来看本篇文章算是比较合适,因为,研究嘛,终究是离不开数学的,所以本篇文章包含大量的公式,虽然学习公式的过程很难受,但是收获是绝对有的!
想必大家或多或少都玩过游戏,而强化学习现在在游戏领域应用很多。
我们来想象一下,一个游戏中应该有一个操作对象,这个对象就是一个智能体,这个智能体的每一步行动都会得到一个奖励(你比如说你往前一步捡到一个血包,那你的血量会增加,你放了一个技能,你的能量会减少,但被你砍到的敌人的血量会减少等等)。
一个游戏有一个终止状态吧,你比如王者荣耀,一方水晶破了,就代表游戏结束了,再比如今年过年很火的合成大西瓜,屏幕满了就表示游戏结束了。
那么一局游戏从开始到结束,一个智能体是不是会存在很多很多种状态,也会发出很多很多次动作,一直到游戏结束。这整个过程的状态走向以及动作序列正是强化学习需要研究的内容。
这一个完整的过程,我们叫做episod,即一个生命周期,那么整个生命周期的奖励值就是:
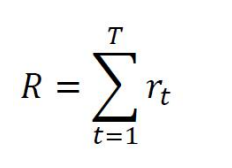
我们不能只考虑每一步的奖励值,而要考虑整个生命周期的生命值,也就是上面的R。
1.与环境交互的数据介绍
超级玛丽这个游戏应该是很多人小时候都玩过,那么如果这个游戏用强化学习来操作小人,那么交互图就是下图:

那么我们如何来记录一个智能体的一局游戏记录呢?答案如下:
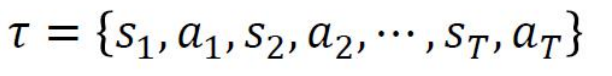
其中S表示状态(state),a表示动作(action),S1通过a1到达S2,S2通过动作到达S3,如此迭代一直到ST。
那么问题来了,智能体怎么知道执行什么动作才能得到更多的奖励呢?
这就是强化学习要解决的核心问题了。
下面我们来看几个东西:
第一个问题:动作执行概率。
可以训练神经网络。
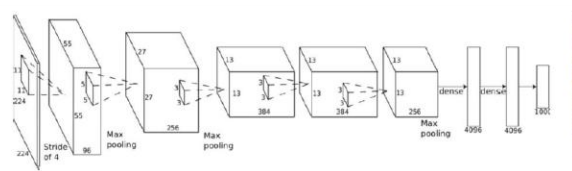
这个网络是在求什么呢
其实是在求
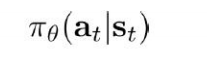
这个是什么玩意呢?它是代表状态St时候,执行动作at的概率。该值是通过调整网络的参数集合来训练得到的。
第二个问题:状态转换概率。
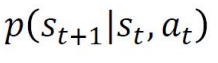
这个玩意是说状态St时候,执行动作at,到达状态St+1的概率是多少。那么在游戏里面,这个是不用我们管的,因为游戏规则都已经写好了。比如你放个技能,那你的下一个状态肯定是能量减少了。
第三个问题:奖励值。
那奖励怎么算呢,奖励是根据当前action和state共同决定的,这个在游戏里面也是游戏规则规定的,比如你被英雄A砍了一刀,你要掉多少血,你被英雄B砍一刀,你要掉多少血等等。
若不是在游戏里面,在其他领域,也可以根据action和state来设计奖励函数。
第四个问题:得到记录表达式。
那么了解了上面的这些玩意,我们就可以看这个公式了:

这个公式是模型的输出结果,它表示的就是一条记录表达式。里面有每个状态以及每个状态下执行的动作。
上面的过程如下图:

2.要完成的目标分析
那么到底要完成什么事情呢,上一小节其实已经说了,我们要求的是参数集。
因为我们要训练网络,所以我们要找到一个最优的参数集合。
那么什么样的参数集是最好的呢?
答案是得到奖励值最多的参数集合是最好的!
于是我们就有如下这个公式:
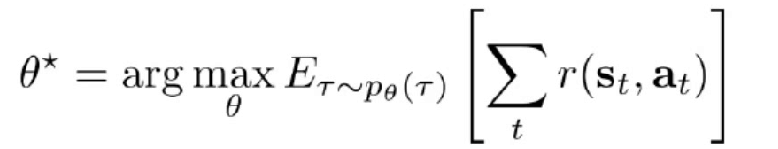
这个就代表总体奖励期望值最高的时候下的参数集。也就是目标函数
期望是什么,比如一个人平常考试分数就在70-90分,那么我们对他的期望就是80分左右。
为什么要用期望而不是准确值呢,因为智能体的这一系列过程有非常多的随机性,即使相同,得到的action也不相同。
有了这个目标函数,下一步就是对目标函数进行求解。

首先我们看看奖励值期望如何求,我们先举个例子,假如让你估计一名同学下一次的考试成绩期望分数,你怎么估计,你肯定会想,让这个同学考100次试,我取个平均分就是他的成绩期望值。
这是什么办法呢?这就是大数定律。我们也可以用这个办法来求奖励值期望。

N代表我要把这个过程进行的次数,比如一万次,那i就从1到1w,针对每一次的过程,状态t=1到t=T,首先将每一次状态转换的奖励值累加,得到每一个过程的总奖励值,然后将1w次过程的奖励值相加,得到1w次过程的奖励值,最后再求平均值,就是我们要的期望值。
期望值我们求到了,但是我们要的不是期望值,而是参数集啊?那么如何来求参数集呢?
我们往下看:
表示当前序列的可能性,
是奖励值,我们将
改写一下:

再计算梯度:
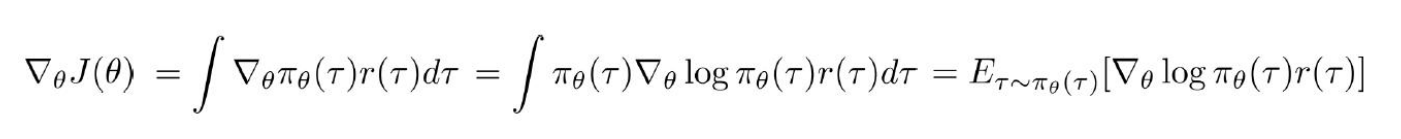
继续变形:

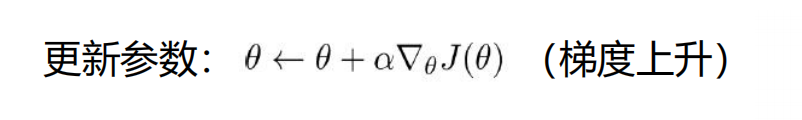
以上就是经过数学变换的目标函数。
3.baseline方法
如何来获取数据呢?
不断进行每个过程。然后做好每个过程的下图记录:
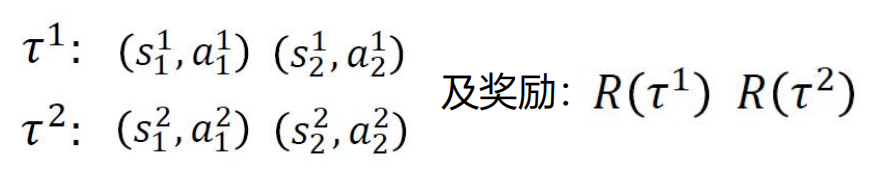
然后将数据带入目标公式:
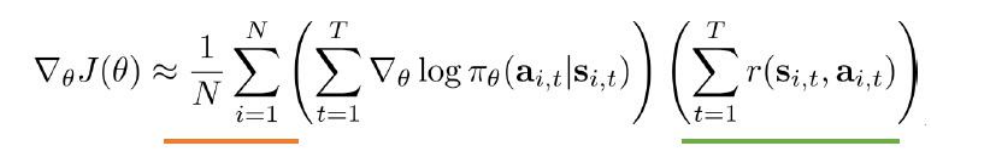
但是以上过程有一个问题,有些任务几乎全都是奖励,而惩罚值很少,这就会造成一个问题,就是智能体无法通过负的惩罚值来知道自己什么不应该做,因为它得到的大多数是奖励值,而惩罚值很少。
这种情况我们就可以做一个去均值处理。也就是把奖励值减去一个baseline(下面用b表示):
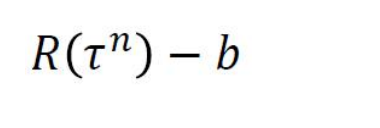
其中b(也就是baseline)的值为:
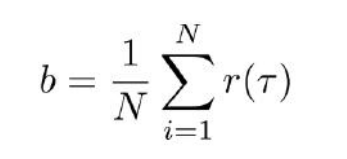
这样是不是就解决了奖励值中,负数(惩罚值)很少但正数(奖励值)很多的问题呢。
4.Onpolicy与Offpolicy策略。
Onpolicy:就是训练数据是由当前agent和环境不断交互得到。
这就有一个问题。
在这个公式中是含的,也就是说你交互一次得到的数据,只能在当前
下迭代一次,因为这条数据用完后
会发生改变,一旦发生改变,那么这条数据就不能够再使用了。那就必须再交互一次得到一条数据,再进行下一次迭代。
所以效率相对不高。
Offpolicy:就是利用别的agent与环境交互得到的数据来用,这样就解决了上述的问题。
有什么问题,欢迎一起讨论。
参考资料:强化学习实战课程
作者qq:1518887260
于2021年3月7日
这篇关于强化学习-你在游戏中对战的人机是如何对付你的!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







