本文主要是介绍Restormer Efficient Transformer for High-Resolution Image Restoration论文代码运行记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Restormer代码训练和测试运行记录
- 文章及代码地址
- 1. 所需环境
- 2. 配置环境
- 3. 安装gdrive以便下载数据集
- 4. 放置权重文件
- 5. 运行Demo
- 运行单图像散焦去模糊
- 训练、测试
Restormer代码训练和测试运行记录
文章及代码地址
文章名称:Restormer: Efficient Transformer for High-Resolution Image Restoration(CVPR 2022)
github代码地址: CVPR 2022–Oral] Restormer
我的百度网盘:链接:https://pan.baidu.com/s/1z89DzRazG2HBO8uBFUPJFg?pwd=k1fn
提取码:k1fn
我百度网盘代码所含内容:
- 创建了requirements.txt文件,除了torch,其他的依赖都包括其中。
- 为了下载谷歌数据集所需的gdrive安装包,go安装包。(只能在linux中使用)
- 包含单图像散焦去模糊的预训练权重,其他所有的权重文件单独放一个网盘来了,按需下载。
所有权重文件百度网盘:链接:https://pan.baidu.com/s/1Kjg8KhITGheXDjRZwp3rKA?pwd=1pof
提取码:1pof
1. 所需环境
3060 Laptop+WSL 22.04+ cuda 11.8 +~~PyTorch 1.8.1(无法使用)~~PyTorch 2.0.1 (可使用)
错误
错误一:3060 Laptop架构无法使用作者原有的PyTorch 1.8.1版本,会报错如下。我猜测30系显卡应该都会报错,因为30系显卡都是sm_86架构,PyTorch 1.8.1 只支持最高sm_75架构。
虽说安装1.8版本,可以通过 torch.cuda.is_abailable()查看返回是True,但是无法运行该代码。
/home/wang/miniconda3/envs/Restormer/lib/python3.8/site-packages/torch/cuda/__init__.py:104: UserWarning:
NVIDIA GeForce RTX 3060 Laptop GPU with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37.

2. 配置环境
-
克隆仓库,并进入该文件夹
git clone https://github.com/swz30/Restormer.git cd Restormer -
新建虚拟环境
conda create -n Restormer python=3.8 conda activate Restormer -
因为github没有给requirements.tet文件,因此我们自己创建一个。如果你通过网盘下载的文件夹,里面包含该requirements.tet文件,无需再次创建。
touch requirements.txt vim requirements.txt把如下内容复制,粘贴直接右键即可。
matplotlib scikit-learn scikit-image opencv-python yacs joblib natsort h5py tqdm einops gdown addict future lmdb numpy pyyaml requests scipy tb-nightly yapf lpips -
安装依赖
# 下面是作者的版本,因为30系显卡不支持PyTorch1.8了,咱们直接最新版吧。 # conda install pytorch=1.8 torchvision cudatoolkit=10.2 -c pytorch # PyTorch官网安装,这是适用于cuda 11.8的 2.0.1版本。 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install requirements.txt
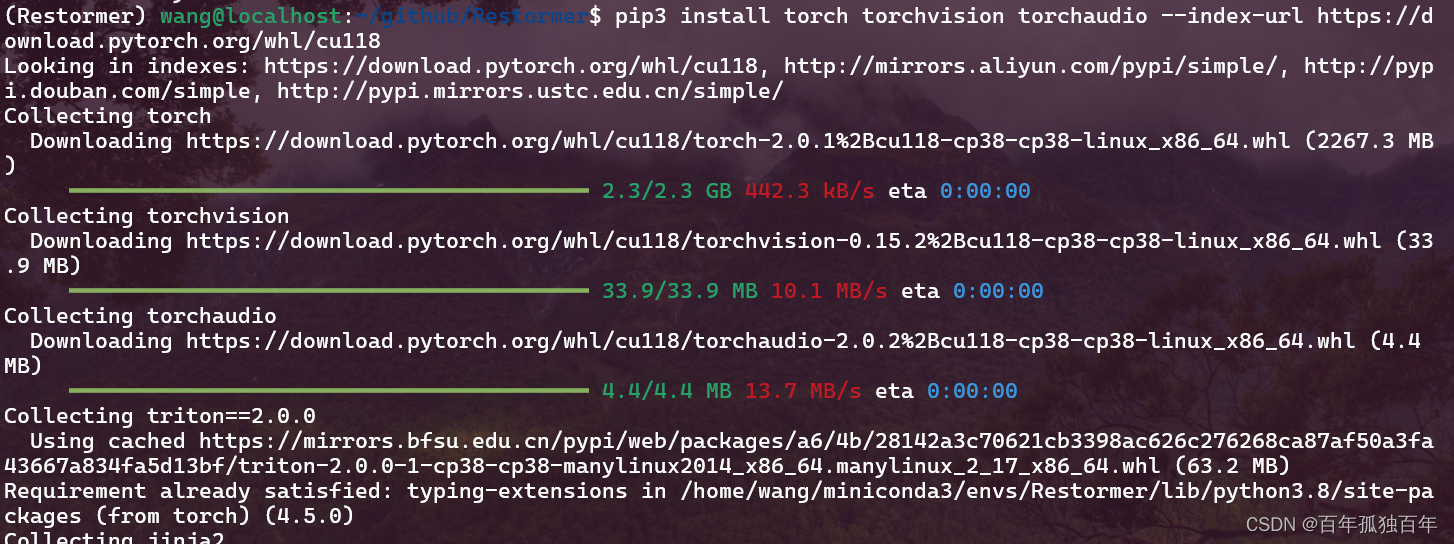
-
安装basicsr,如果是windows可能会报错。
python setup.py develop --no_cuda_ext
安装成功之后如下图所示。
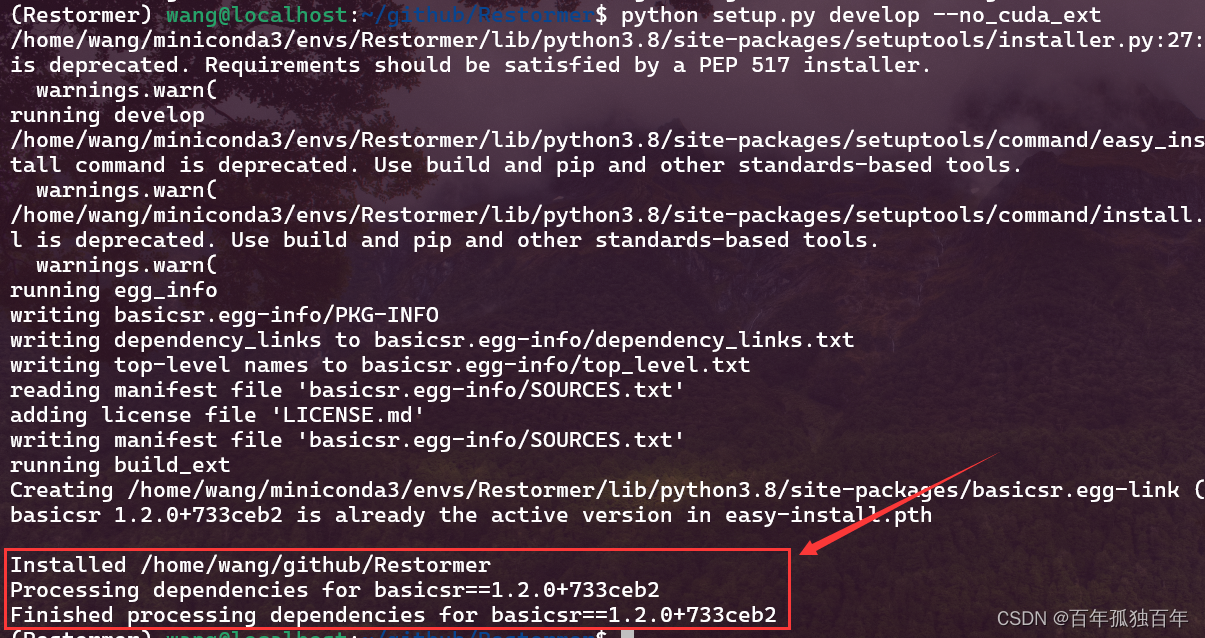
至此环境已经准备完成。
3. 安装gdrive以便下载数据集
备注:如果你只运行demo,就没必要使用gdrive了,可以不安装。或者你自己也已经有GoPro等数据集了,也不要安装这个。如果你有自己的模糊数据集,也不用安装这个。
从谷歌云盘下载文件,需要先安装Golang,然后使用Golang包管理工具“go”来安装“gdrive”。
-
安装 go
curl -O https://storage.googleapis.com/golang/go1.11.1.linux-amd64.tar.gz mkdir -p ~/installed tar -C ~/installed -xzf go1.11.1.linux-amd64.tar.gz mkdir -p ~/go -
将go添加到环境变量中
export GOPATH=$HOME/go export PATH=$PATH:$HOME/go/bin:$HOME/installed/go/bin具体来说,这两个环境变量的含义如下:
export GOPATH=$HOME/go:这个命令将设置一个名为 “GOPATH” 的环境变量,它的值为 “ H O M E / g o " ,其中 " HOME/go",其中 " HOME/go",其中"HOME” 表示当前用户的home目录。这个环境变量告诉编译器和其他工具在哪里寻找 Go 语言的源代码、二进制文件和其他相关资源。export PATH=$PATH:$HOME/go/bin:$HOME/installed/go/bin:这个命令将向系统的环境变量 “PATH” 中添加两个目录,分别为 “ H O M E / g o / b i n " 和 " HOME/go/bin" 和 " HOME/go/bin"和"HOME/installed/go/bin”。这些目录包含了一些与 Go 语言相关的可执行文件,例如 “go” 命令和 “gofmt” 命令等。通过将这些目录添加到 “PATH” 环境变量中,您可以在命令行中直接使用这些命令,而无需输入完整的路径。
-
安装 gdrive
go get github.com/prasmussen/gdrive从 GitHub 上下载一个名为 “gdrive” 的代码库,并将其安装到您的计算机上。
注意:上述代码可能无法使用。
那就通过手动安装,如下命令
wget https://github.com/prasmussen/gdrive/releases/download/2.1.1/gdrive_2.1.1_linux_386.tar.gz tar -xvf gdrive_2.1.1_linux_386.tar.gz sudo mv gdrive /usr/local/bin/ gdrive help
4. 放置权重文件
记得把权重文件放置在\Defocus_Deblurring\pretrained_models该目录下,本文只做了散焦去模糊的例子。
谷歌云盘地址:文件夹 - Google 云端硬盘(仅包含单图像散焦去噪权重)
因为我谷歌云盘不常用,上面的是作者提供的谷歌网盘,我保存到百度网盘中了,包含去噪、去雨、运动去模糊、散焦去模糊等全部预训练权重文件。
我的百度网盘:链接:https://pan.baidu.com/s/1Kjg8KhITGheXDjRZwp3rKA?pwd=1pof
提取码:1pof
5. 运行Demo
运行单图像散焦去模糊
如果你环境配置好了,就是第二步配置环境都已经完成,那就可以尝试运行demo了。
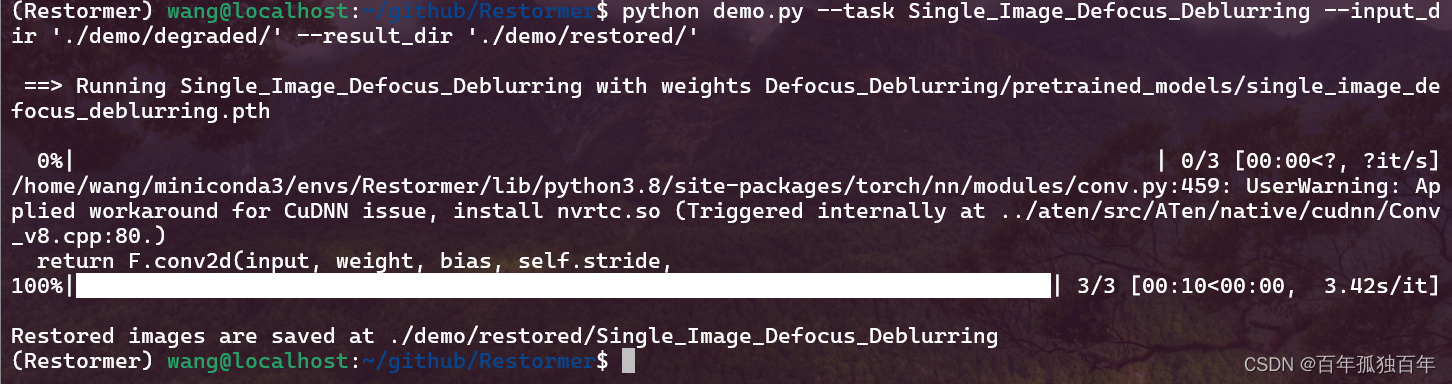
python demo.py --task Single_Image_Defocus_Deblurring --input_dir './demo/degraded/' --result_dir './demo/restored/'
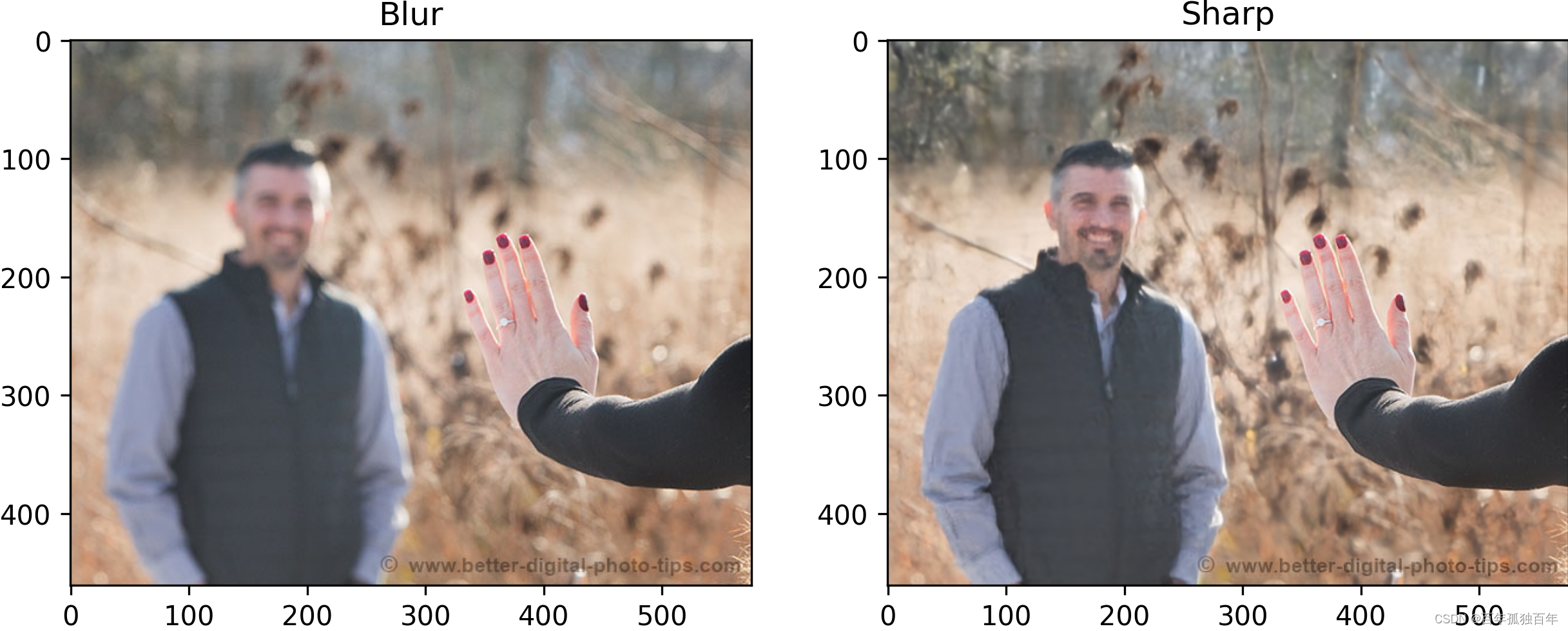
该命令输入如下所示。
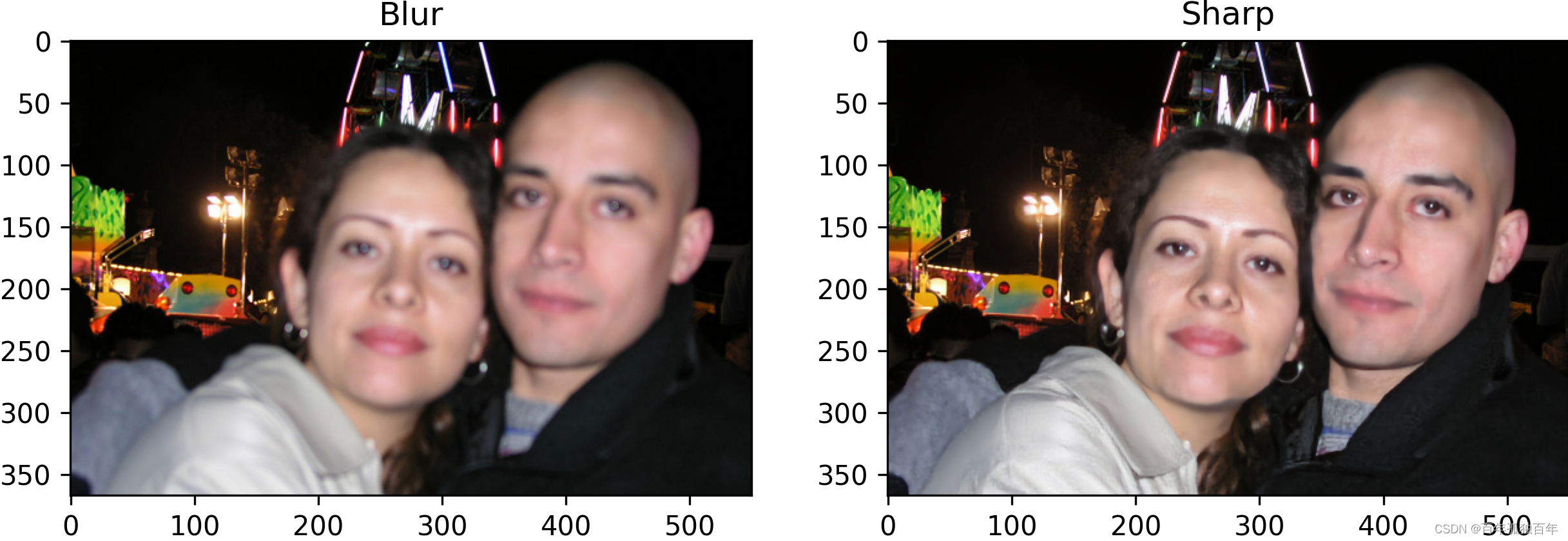
去模糊效果对比图。

训练、测试
下个博客一块再写吧,累了
这篇关于Restormer Efficient Transformer for High-Resolution Image Restoration论文代码运行记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






