本文主要是介绍数据同步工具oracle goldengate安装与配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.前言
跨平台、异构数据库之间的数据同步,方案有限,Oracle OGG算比较靠谱的一个:
优点:性能好,大数据量速度快,对线上库性能的影响忽略不计;缺点:安装配置、维护有点麻烦,尤其是后期有字段变更时;
个人觉得适合部署在小范围、大数据量、对性能要求较高的同步需求。
本案例以Oracle(10.10.10.1) -> mysql(10.10.10.2)说明其部署过程以及注意事项。
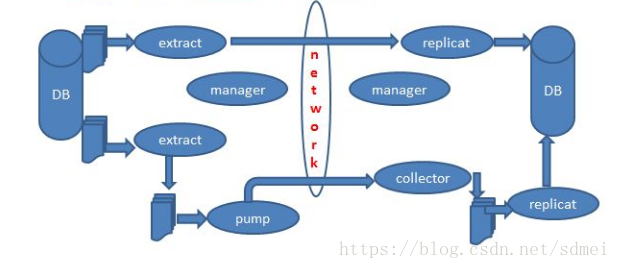
原理说明:
OGG从源库的redo log或归档日志中提取出相关表的数据变更,生成特定格式的文件,发送至目标库;目标库读取文件,应用到目标表;
源库有ext\pump进程,目标库有rep进程,这些进程分别完成数据提取、发送文件、应用文件的任务;
本案例中分别是ext1\pump1\rep1进程,每个进程有其各自的配置文件;
如果源库已经在线上跑过一段时间了,有了数据量,就需要通过初始化任务来先初始化目标库,然后再通过ext1\pump1\rep1进程增量同步‘
本案例中分别是initext1\initrep1完成初始化(注:初始化无pump进程)
此外,源和目标各有1个manager进程负责全局配置。
盗个图:
2.安装
for oracleexport ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/u01/app/oracle/ggs:$ORACLE_HOME/lib
./runInstaller
指定安装路径
./ggsci
create subdirs
for mysql
解压
直接执行./ggsci
create subdirs
3.准备
Oracle数据库归档模式;Oracle数据库设置SUPPLEMENTAL LOG和FORCE LOGGING:
SELECT supplemental_log_data_min, force_logging FROM v$database;
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
SQL> ALTER DATABASE FORCE LOGGING;
Oracle数据库设置表trandata
./ggci
ggsci > dblogin userid system password mypwd
ggsci > add trandata myschema.mydb
mysql设置以下参数:
binlog_row_image:full(默认)
log_bin
log_bin-index
max_binlog_size
binlog_format
mysql库中在mydb中创建checkpoint表:chkpt_mysql_create.sql
源表和目标表表必须有主键或唯一键;
目标表清空;
目标表禁用外键、约束、触发器;
如果初始数据量较大,临时删除目标表索引,初始化导入后再建
4.配置文件
以下文件置于dirprarm目录下--源端--
mgr:
PORT 7809
DYNAMICPORTLIST 7810-7820
ACCESSRULE, PROG *, IPADDR 192.168.*.*, ALLOW
--AUTOSTART ER *
--AUTORESTART ER *, RETRIES 3, WAITMINUTES 3
STARTUPVALIDATIONDELAY 5
PURGEOLDEXTRACTS /backup/ggs12/dirdat/*, USECHECKPOINTS, MINKEEPHOURS 2initext1:
EXTRACT initext1
SETENV (ORACLE_HOME = "/u01/app/oracle/product/11.2.0/dbhome_1")
SETENV (ORACLE_SID = "myora")
USERID system PASSWORD mypasswprd
RMTHOST 10.10.10.2, MGRPORT 7809
RMTTASK REPLICAT, GROUP initrep1
TABLE schema_name.table_name;ext1:
EXTRACT ext1
SETENV (ORACLE_HOME = "/u01/app/oracle/product/11.2.0/dbhome_1")
SETENV (ORACLE_SID = "myora")
USERID system PASSWORD mypwd
LOGALLSUPCOLS
EXTTRAIL /backup/ggs12/dirdat/aa
TABLE myschema.mytable;pump:
EXTRACT pump1
USERID system PASSWORD mypassword
RMTHOST 10.10.10.2, MGRPORT 7809
RMTTRAIL /data1/ggs/dirdat/aa
TABLE myschema.myname;mgr:
PORT 7809
DYNAMICPORTLIST 7810-7820
#AUTOSTART ER *
#AUTORESTART ER *, RETRIES 3, WAITMINUTES 3
STARTUPVALIDATIONDELAY 5
PURGEOLDEXTRACTS /data1/ggs/dirdat/*, USECHECKPOINTS, MINKEEPHOURS 2initrep1:
REPLICAT initrep1
TARGETDB mydbname@10.10.10.2:3306, USERID root, PASSWORD mypassword
MAP myschema.mytable, TARGET mydb.mytable, COLMAP(USEDEFAULTS, source_cola = target_cola, source_colb = target_colb);rep1:
REPLICAT rep1
TARGETDB dbcopy@10.10.10.2:3306, USERID root, PASSWORD mypassword
MAP myschema.mytable, TARGET mydb.mytable, COLMAP(USEDEFAULTS, source_cola = target_cola, source_colb = target_colb);5.创建进程
创建好配置文件后,收到执行以下命令创建进程(自动读取配置)--源端--
ggsci > add extract initext1, sourceistable
ggsci > add extract ext1, tranlog, begin now
ggsci > add exttrail /backup/ggs12/dirdat/aa, extract ext1
ggsci > add ext pump1, exttrailsource /backup/ggs12/dirdat/aa
ggsci > add rmttrail /data1/ggs/dirdat/aa, ext pump1ggsci > add replicat initrep1, specialrun
ggsci > add rep rep1, exttrail /data1/ggs/dirdat/aa, checkpointtable mydb.ggs_checkpoint6.开始同步
source:
ggsci > start ext1
ggsci > start pump1target
rep1设置HANDLECOLLISIONSsource:
ggsci > start initext1target:
ggsci > view report initrep1
确认initrep1执行完成
ggsci > start rep1
ggsci > info rep1
rep1配置文件删除HANDLECOLLISIONS?配置
ggsci > send replicat rep1, nohandlecollisionsggsci > start rep rep17.注意事项
(1).OGG不能识别复合唯一键,因此有复合键的需要用keycols指定,否则以所有字段作为key;
(2).调整源或目标表的字段步骤:
停止ext\pump\rep进程修改源和目标库字段
启动ext\pump\rep进程
为了防止DBA或运维误操作,在oracle相关表上创建触发器,提醒这是ggs table:
create or replace trigger tri_ddl_ggstab_permission
before drop or truncate or alter on database
beginif ORA_DICT_OBJ_NAME in ('TABNAME1','TABNAME2') thenraise_application_error(-20001,'GGS table, Contact DBA.');end if;
end;(3).万事离不开监控,ggs的监控可以通过创建心跳表监控实时同步情况
说明:
在源和目标表建心跳表;
源通过JOB自动更新心跳表;
目标表定时检查心跳表的时间与当前时间之差;
目标表中now() - update_time,反应了ggs同步情况;
目标表中auto_time - update_time,反应了ggs延时情况;
source:
create table ggs_monitor(ggs_process varchar2(100), update_time date) tablespace lbdata;
alter table ggs_monitor add constraint pk_ggsmonitor primary key(ggs_process);
insert into ggs_monitor(ggs_process,update_time) values ('ext1',sysdate);
begindbms_scheduler.create_job(job_name => 'job_ggs_monitor',job_type => 'PLSQL_BLOCK',job_action => 'begin update ggs_monitor set update_time=sysdate; commit; end;',start_date => sysdate,enabled => true, repeat_interval => 'Freq=Secondly;Interval=10');
end;
target:
create table ggs_monitor (ggs_process varchar(100) COLLATE utf8_bin DEFAULT NULL,update_time datetime DEFAULT NULL,auto_tim` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,primary key(ggs_process)
);GGS配置注意事项:
ext1: TABLE system.ggs_monitor, WHERE (ggs_process = 'ext1');zabbix
UserParameter=ggsAvail[*],/etc/zabbix/script/ggsAvail.sh $1
UserParameter=ggsDelay[*],/etc/zabbix/script/ggsDelay.sh $1ggsAvail.sh
#!/bin/bash
if [ $# -ne 1 ]; thenecho "Usage:$0 extname"exit
fiextname=$1
rootPath=/etc/zabbix/script
tmpLog=$rootPath/tmpGgsAvail${extname}.logmysql -u root -pmypwd <<EOF > ${tmpLog} 2>/dev/null
select concat('RESULTLINE#',now() - update_time,'#') message from dbadmin.ggs_monitor where ggs_process='${extname}';
EOF
sed -i '/RESULTLINE/!d' ${tmpLog}
resultLine=`cat ${tmpLog} | wc -l`
if [ $resultLine -ne 1 ]; thenecho 3600exit
fi
echo `cat ${tmpLog} | cut -d "#" -f 2`
exitggsDelay.sh
#!/bin/bash
if [ $# -ne 1 ]; thenecho "Usage:$0 extname"exit
fiextname=$1
rootPath=/etc/zabbix/script
tmpLog=$rootPath/tmpGgsDelay${extname}.logmysql -u root -pmypwd <<EOF > ${tmpLog} 2>/dev/null
select concat('RESULTLINE#',auto_time - update_time,'#') message from dbadmin.ggs_monitor where ggs_process='${extname}';
EOF
sed -i '/RESULTLINE/!d' ${tmpLog}
resultLine=`cat ${tmpLog} | wc -l`
if [ $resultLine -ne 1 ]; thenecho 3600exit
fi
echo `cat ${tmpLog} | cut -d "#" -f 2`
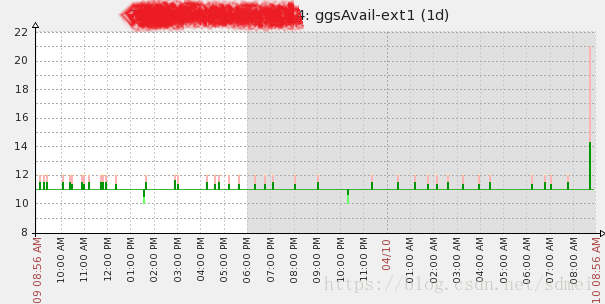
exitzabbix监控效果

这篇关于数据同步工具oracle goldengate安装与配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




