本文主要是介绍Python爬取汽车之家二手车数据并作可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码
课程亮点:
1、系统分析目标网页
2、html标签数据解析方法
3、海量数据一键保存
获取二手车数据
环境介绍:
-
python 3.8
-
pycharm 2022.3专业版
-
requests >>> pip install requests
-
parsel >>> pip install parsel
案例实现流程:
一. 思路分析
-
需要抓取什么数据
-
大概的流程和步骤
-
确定数据来源
https://www.che168.com/china/list/ -
访问到 该地址
-
从访问之后的信息中 我们要取出 对应需要的数据字段
-
进行保存操作
-
分析翻页的规律
二. 代码实现
发送请求
提取数据
保存数据
代码展示
'''
python资料获取看这里噢!! 小编 V:qian97378,即可获取:
文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
import requests # pip install requests
import parsel # pip install parsel
import csvwith open('汽车之家.csv', mode='w', newline='', encoding='utf-8') as f:csv.writer(f).writerow(['card_name', 'cards_unit', 'price', 'original_price', 'href_url', 'img_url'])
headers = {'cookie': 'fvlid=1678707796259lUxyb5ctia8Y; sessionid=88abf095-f918-4e12-9837-cf8e61024732; area=430112; che_sessionid=1476DA7D-0E1A-4DB6-A0E5-94074A95603C%7C%7C2023-03-13+19%3A43%3A16.765%7C%7C0; listuserarea=0; sessionip=175.13.226.104; Hm_lvt_d381ec2f88158113b9b76f14c497ed48=1699272164; UsedCarBrowseHistory=0%3A49368425; userarea=0; sessionvisit=80b96168-6a79-46b4-b8a5-64adbde2fdda; sessionvisitInfo=88abf095-f918-4e12-9837-cf8e61024732|www.che168.com|102179; che_sessionvid=BE7B0EF0-7E60-4A60-9FBE-5CE182AA0FD2; ahpvno=8; Hm_lpvt_d381ec2f88158113b9b76f14c497ed48=1699276565; ahuuid=1993BFC6-651A-471B-A2F0-549B12314CE8; showNum=56; v_no=59; visit_info_ad=1476DA7D-0E1A-4DB6-A0E5-94074A95603C||BE7B0EF0-7E60-4A60-9FBE-5CE182AA0FD2||-1||-1||59; che_ref=0%7C0%7C0%7C0%7C2023-11-06+21%3A16%3A04.741%7C2023-03-13+19%3A43%3A16.765; sessionuid=88abf095-f918-4e12-9837-cf8e61024732','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
for page in range(100):url = f'https://www.che168.com/china/a0_0msdgscncgpi1ltocsp{page}exx0/?pvareaid=102179#currengpostion'# 1. 发送请求response = requests.get(url, headers=headers)# 2. 提取数据html_data = response.text# JSON格式的数据 -> 结构化数据 (根据层级关系取值) 字典取值 列表取值# 网页源代码 -> 非结构化数据# 所有的车辆信息 全部都在 li里面# 那我是不是可以先将 所有的 li 提取到# //ul[@class="viewlist_ul"]/liselect = parsel.Selector(html_data)# 拿到所有的lilis = select.xpath('//ul[@class="viewlist_ul"]/li')for li in lis:card_name = li.xpath('string(.//h4[@class="card-name"])').get()cards_unit = li.xpath('string(.//p[@class="cards-unit"])').get()price = li.xpath('string(.//span[@class="pirce"])').get()original_price = li.xpath('string(.//s)').get()href_url = li.xpath('.//a[@class="carinfo"]/@href').get()img_url = li.xpath('.//img/@src').get()print(card_name, cards_unit, price, original_price, href_url, img_url)# 多页采集 保存数据with open('汽车之家.csv', mode='a', newline='', encoding='utf-8') as f:csv.writer(f).writerow([card_name, cards_unit, price, original_price, href_url, img_url])
数据可视化
1. 导入模块
'''
python资料获取看这里噢!! 小编 V:qian97378,即可获取:
文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
import pandas as pd
from pyecharts.charts import *
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
2. Pandas数据处理
2.1 读取数据
df = pd.read_csv('汽车之家.csv', encoding = 'utf-8')
df.head()

2.2 查看表格数据描述
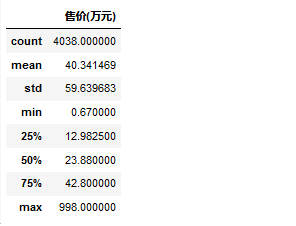
df.describe()
df.isnull().sum()

df.dropna(axis=0, how='any', inplace=True)
3 Pyecharts可视化
3.1 各省市二手车数量柱状图
counts = df.groupby('城市')['品牌'].count().sort_values(ascending=False).head(20)
'''
python资料获取看这里噢!! 小编 V:qian97378,即可获取:
文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
bar=(Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark')).add_xaxis(counts.index.tolist()).add_yaxis('城市二手车数量',counts.values.tolist(),label_opts=opts.LabelOpts(is_show=True,position='top'),itemstyle_opts=opts.ItemStyleOpts(color=JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])"""))).set_global_opts(title_opts=opts.TitleOpts(title='各个城市二手车数量柱状图'),xaxis_opts=opts.AxisOpts(name='书籍名称',type_='category', axislabel_opts=opts.LabelOpts(rotate=90),),yaxis_opts=opts.AxisOpts(name='数量',min_=0,max_=500.0,splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))),tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')).set_series_opts(markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='均值'),opts.MarkLineItem(type_='max',name='最大值'),opts.MarkLineItem(type_='min',name='最小值'),]))
)
bar.render_notebook()
3.3 二手车品牌占比情况
'''
python资料获取看这里噢!! 小编 V:qian97378,即可获取:
文章源码/教程/资料/解答等福利,还有不错的视频学习教程和PDF电子书!
'''
dcd_pinpai = df['品牌'].apply(lambda x:x.split(' ')[0])
df['品牌'] = dcd_pinpai
pinpai = df['品牌'].value_counts()
pinpai = pinpai[:5]
datas_pair_1 = [[i, int(j)] for i, j in zip(pinpai.index, pinpai.values)]
datas_pair_1
pie1 = (Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px')).add('', datas_pair_1, radius=['35%', '60%']).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="汽车之家二手车\n\n数量占比区间", pos_left='center', pos_top='center',title_textstyle_opts=opts.TextStyleOpts(color='#F0F8FF',font_size=20,font_weight='bold'),))
)
pie1.render_notebook()
尾语
好了,今天的分享就差不多到这里了!
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

最后,宣传一下呀~👇👇👇 更多源码、资料、素材、解答、交流 皆点击下方名片获取呀👇👇👇
这篇关于Python爬取汽车之家二手车数据并作可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



