本文主要是介绍【深度学习】卷积层填充和步幅以及其大小关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考链接
【深度学习】:《PyTorch入门到项目实战》卷积神经网络2-2:填充(padding)和步幅(stride)
一、卷积
卷积是在深度学习中的一种重要操作,但实际上它是一种互相关操作,,首先我们来了解一下二维互相关:具体做法是对应数字相乘后相加
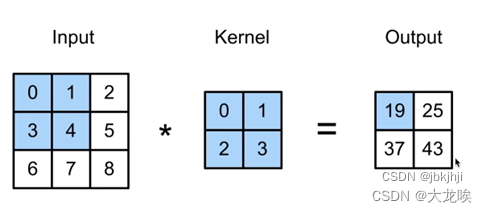
Output具体的运算过程:
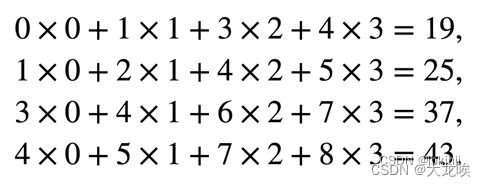
而一个卷积运算的操作如下,给一个输入矩阵和一个核函数,我们将从输入特征的左上角开始与核函数求内积,然后在进行滑动窗口,求下一个内积。得到我们的输出,具体计算如下
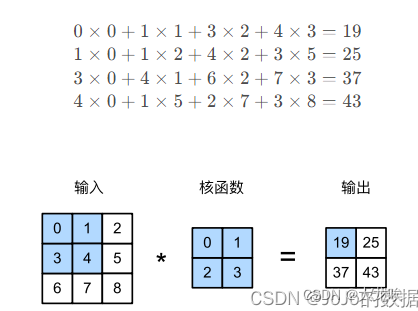
可以看出,通过卷积计算后,我们的原始数据特征变小了。假设输入矩阵为,核函数(Kernel)为
,通常核是一个方阵形式。那么得到的输出结果为
。
一维和三维卷积
- 一维:文本,语言,时序序列
- 三维:视频,医学图像,气象地图
二、卷积层的填充和步幅:控制输出大小的超参数
正如上面所说的假设输入特征为,核形状为
,那么经过卷积核作用后,得到的输出形状为
。可以看出,通常情况下输出特征会由于卷积核的作用而减小。而深度神经网络中,由于卷积核的作用,会导致我们的输出过早的变的很小,导致我们无法构建深层的神经网络。因此接下来介绍另外两个影响输出形状的方法,扩充(padding)和步幅(stride)。
- 有时候,输出远远小于输入,这是因为卷积核的影响,而在原始图像较小的情况下,任意丢失很多信息,这个时候我们需要使用填充解决此问题。
- 有时,我们可能希望大幅降低图像的宽度和高度。例如,我们发现一个图像实在是太大了。这个时候使用步幅可以快速将输出变小。
1. padding
为了构建深度神经网络,你需要学会使用的一个基本的卷积操作就是padding。首先让我们来回忆一下卷积是如何计算的:

这其实有两个缺陷:
第一个是如果每一次使用一个卷积操作,我们的图像都会缩小。 例如我们从 6x6 通过一个 3x3的卷积核,做不了几次卷积,我们的图片就会变得非常小,也许它会缩小到只有1x1。
第二个缺陷是图片角落或者边际上的像素只会在输出中被使用一次 因为它只通过那个3x3的过滤器(filter)一次 然而图片中间的一个像素,会有许多3x3的过滤器(filter)在那个像素上重叠 所以相对而言 角落或者边界上的像素被使用的次数少很多,这样我们就丢失了许多图片上靠近边界的信息。
所以为了同时解决上述的两个问题。我们能做的是在使用卷积操作前,对图片进行填充,通常是用0来进行填充,具体如下所示。
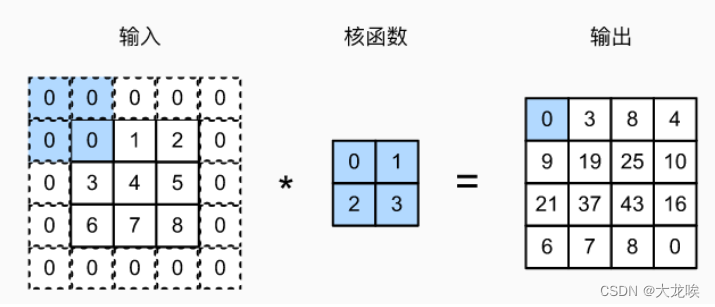
我们可以沿着图像边缘再填充一层像素。这样那么3×3的图像就被我们填充成了一个5×5的图像。如果你用2×2的卷积核对这个5×5的图像卷积,我们得到的输出就不是2×2,而是4×4的图像,你就得到了一个尺寸比原始图像3×3还大图像。习惯上,我们都用用0去填充,如果是填充参数,在这个案例中,
,因为我们在周围都填充了一个像素点,输出也就变成了
。所以,要是我们想要保持图像大小不变,则意味着
,则
,在后面我们的卷积核通常会设置为奇数。
为了指定卷积操作中的padding,我们可以指定的值。以上就是padding,下面我们讨论一下如何在卷积中设置步长。
2.步幅(stride)
卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。卷积中的步幅是另一个构建卷积神经网络的基本操作,例如,下面是一个步幅为3的情况。

如果我们用一个的过滤器卷积一个
的图像,padding为
,步幅为
,在这个例子中
,因为现在我们不是一次移动一个步长,而是一次移动
步,输出于是变为
。
表示向下取整。
这篇关于【深度学习】卷积层填充和步幅以及其大小关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




