本文主要是介绍【论文阅读】Generating Radiology Reports via Memory-driven Transformer (EMNLP 2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
资料链接
论文原文:https://arxiv.org/pdf/2010.16056v2.pdf
代码链接(含数据集):https://github.com/cuhksz-nlp/R2Gen/
背景与动机

这篇文章的标题是“Generating Radiology Reports via Memory-driven Transformer”,发表于会议EMNLP2020。它的主要目的是使用记忆驱动的Transformer生成放射性医学影像的报告。
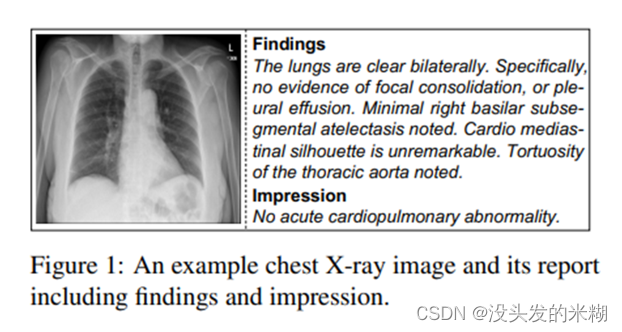
文章中给出了一个示例的X光片的报告,包含发现和印象两个部分。
文章指出,相比较于传统的NLP任务,放射性医学影像报告生成任务会需要生成内容包含很长的文本描述,详细地解释图像内容,同时生成的内容还具有模板式的特征,因此传统的基于字幕的方式对于这个任务是不太够用的。

在过往的研究中,针对这一任务,往往采用的两种方式是基于数据库检索的方法和基于模板的方法,然而这两种方法都依赖于大量的数据集或手工创建的模板,存在一定的局现性。
方法
首先在整体的架构方面,采用了一个端到端的Transformer架构,输入的图像序列首先进行Patch Partition操作,然后输入到特征提取网络中,得到一组Patch Features,用于Transformer的输入。论文对Transformer的改进主要集中在Decoder部分。
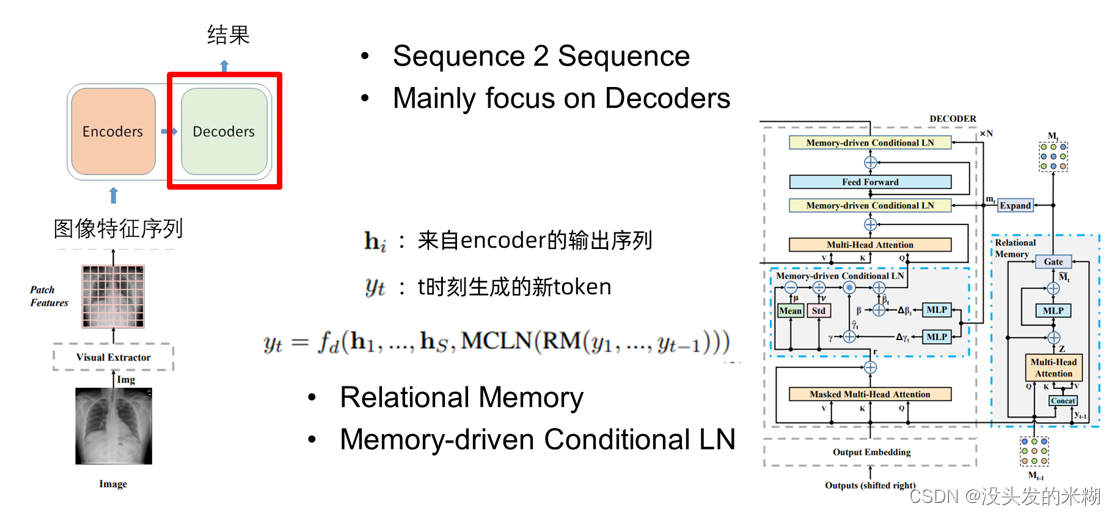
可以看到上面右侧这张图,在Decoder部分作者主要引入的两个机制是Relational Memory和Memory-driven Conditional LN。用一个公式来表示的话,其中hi是来自encoder的输出序列,yt是t时刻生成的新token。整体仍然保留了Transformer的架构,只是在它的基础上有一些模块的增加和改变。
为了描述方便,后面就统称Relational Memory为RM, Memory-driven Conditional LN为MCLN。
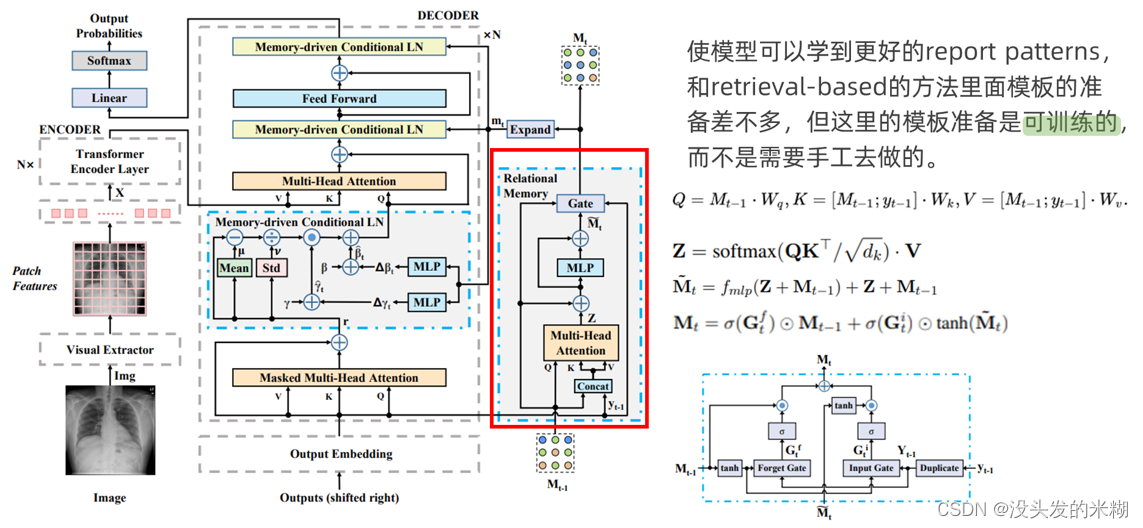
首先来看到RM部分。该部分的主要作用是使得模型能够学到更好的report patterns,它和retrieval-based的方法里面的模板的准备差不多,但这里的模板是可训练的,而不是需要手工去做的。
具体看到它的结构,可以看见该部分使用一个矩阵Mt来保存t时刻的记忆信息,根据文章的介绍,该矩阵的每个行是一个存储槽,代表一些重要的模式信息。在decoder生成token的过程中,矩阵结合前面时间步的输出逐步更新,更新的过程参考右边的这三个公式。首先在时间步t上,将来自时间步t-1的矩阵Mt-1通过一个Wq转化为Q,然后将Mt-1和前一时刻的输出yt-1连接,并转化为K和V,一起送进多头注意力模块中,得到结果Z。
考虑到这个记忆存储器是循环运行的,所以随着时间推移可能会发生梯度消失或爆炸的问题,因此引入了残差连接,同时引入了类似于LSTM中的门机制。
门机制的示意图如上面右下角的图片所示,Mt-1是上一时刻的记忆矩阵M,yt-1是上一时刻输出的token,两者分别送入遗忘门和输入门中,最后得到输出Mt。
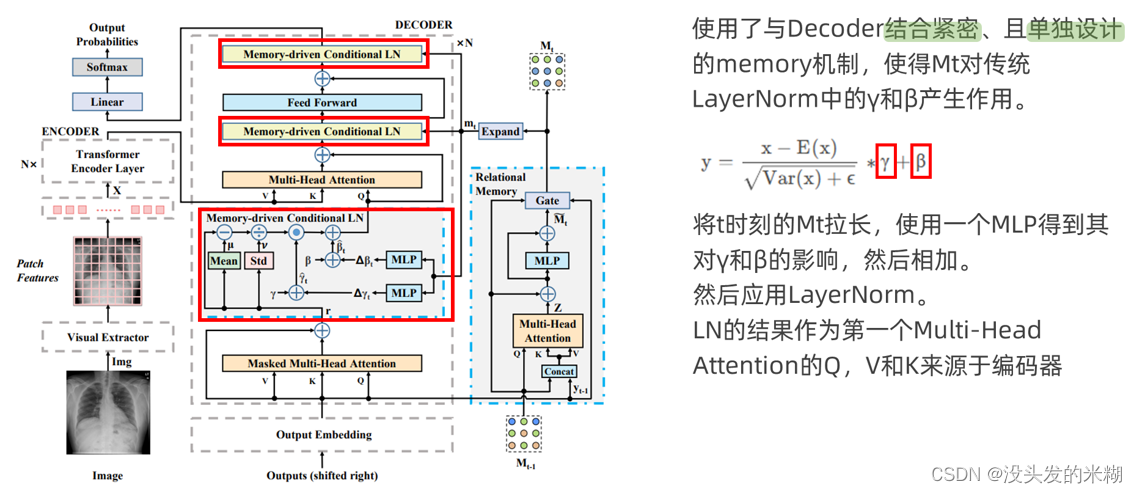
接下来看到MCLN部分。这一部分我认为是整篇论文创新点最大的部分,它创新性地将记忆力机制引入到了LayerNorm层中。使得每一时刻的Mt对LN层中的γ和β产生作用。它的思路也不复杂,分别通过一个MLP得到拉长后的Mt对γ和β的影响,然后将它们与原来的γ和β相加,然后再应用LayerNorm。LN的结果作为第一个MultiHead Attention的Q,V和K来源于编码器。
结果
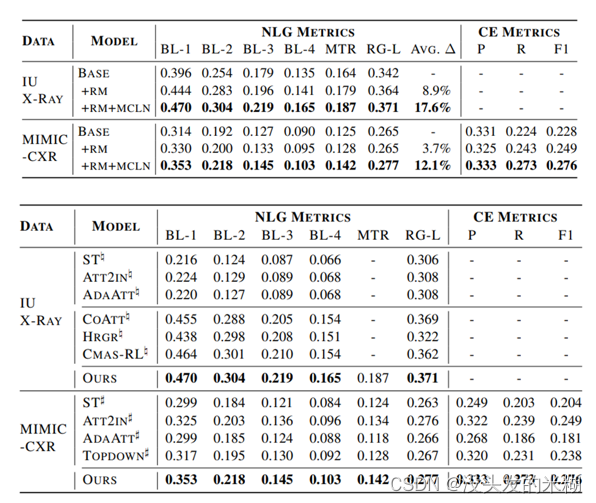
最后来到结果部分。论文主要是针对IU X-RAY和MIMIC-CXR这两个数据集进行实验。在与baseline对比的过程中,在多个评价指标下都超过了baseline。同时与先前的研究进行比较,也取得了不错的结果。
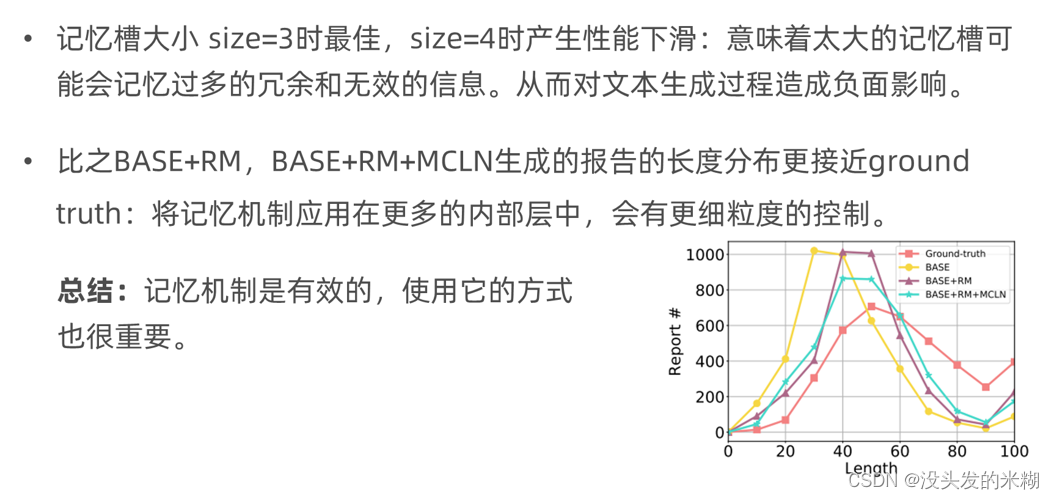
作者也针对结果进行了调参与分析,发现记忆槽size=3时效果最佳,size=4时产生了性能下降,意味着太大的记忆槽可能会记忆过多的冗余和无效信息,从而对文本生成过程产生负面影响。并且还做了消融实验,比之于BASE+RM,BASE+RM+MCLN生成的报告长度分布更接近于ground truth,这表明将记忆机制应用在更多的内部层中,会对模型生成的内容有更细粒度的控制。
总结
本文将记忆力机制引入到了端到端的放射性医学影像描述生成的任务重,从而确保了生成结果能够准确、详细地描述输入的影像,并且遵循常规的模式性的描述机制。
在引入记忆力机制的过程中,其更改Transformer的结构的地方比较新颖,在LN层上动刀子,从而将记忆的影响带到了Decoder内部的隐层状态中,获得了更细粒度的控制。
这篇关于【论文阅读】Generating Radiology Reports via Memory-driven Transformer (EMNLP 2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)