本文主要是介绍练就分析思维,成为更好的数据分析师,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、一点碎语
- 二、6步练就数据思维
- 三、练就数据思维中的实施环节细化
- 3.1 找到利益相关者的步骤
- 3.2 回顾之前的发现能带来的启发
- 3.3 回顾之前的发现的一些方法
- 3.4 确定自己是否构建好问题需要问自己的10个问题
- 3.5 为识别出适当的模型必须考虑的三个问题
- 3.6 创造性分析思维的4个阶段
- 四、成为专家级的定量分析师,需要的态度、习惯、知识和方法
- 4.1 培养数据分析能力
- 4.2 培养过程注意事项
- 五、总结
一、一点碎语
《成为数据分析师》(托马斯·达文波特)这本书应该是第二次看了。距离上次看过大概过了一年左右了吧,再次回看,觉得从中又有了新的收获。“温故而知新”,这句话真的甚有道理。最近也整理了下自己小小的一方书桌,将自己“术业的书籍”放在了桌面上,将电脑从桌面上放到了下面,在不用的情况下,自己就一律收起来,不放在那么显眼的地方。在《得到》上听到过一种“场”的概念,因此,也欲塑造自己的一种**“读书场”**,对于自己有纸质书的,就尽可能在自己的场里阅读。如果下班比较早,自己也会刻意去附近的书店这种场所,去看书。附近有条件,还是要合适的应用起来,亲身体验了一段时间,在书店看书的效果真的要好很多,自己开小差、玩手机的时间会大大缩减。

已经有一个多月没有更新博文了,有点偷懒了。时刻保持撰写的能力,回顾和总结工作也好,学习也罢,生活也行,还是很重要的。不多说了,捡起来,权当是亡羊补牢。
回到本文的主题:练就分析思维,成为更好的数据分析师。其实没有想象中的那么难,只是我们日常可能会偷懒,直接跳过了一些很重要的步骤而径直冲着终极目标去了,而忽视了抵达终极目标所需经历的一些环节,从而错过了在达成目标的同时,练就属于自己的分析模式。下面,本文就《成为数据分析师》中的观点,将其中自己感觉不错的信息整理如下。
二、6步练就数据思维
定量分析的3个阶段和6个步骤:1
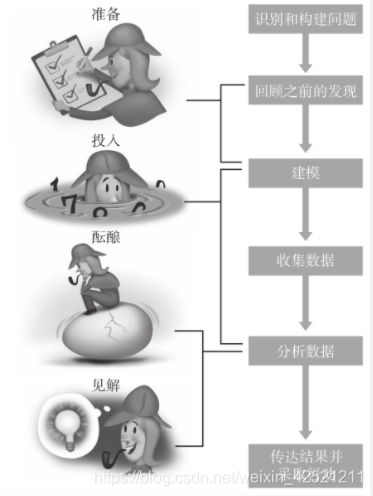
第一阶段:构建问题
- 识别问题
- 回顾之前的发现
第二阶段:解决问题
3. 建模或选择变量
4 . 收集数据
5. 分析数据
第三阶段:传达结果并基于结果采取行动
6. 传达结果并采取行动

构建问题的目的,就是确定分析工作要回答什么问题,以及基于这个问题的答案要做出什么样的决策。
- 找到利益相关者
- 聚焦
- 你所说的是什么样的故事
- 关键是,知道你想要什么
- 构建问题
解决问题的阶段,就是需要确定模型中采用的变量,并收集测量这些变量的数据,然后实实在在地进行数据分析。
- 每当你建立一个模型时,就必须简化它
- 收集和测量数据
- 二手数据的价值
- 原始数据迎来指数级大爆炸
- 模型的类型
- 改变是一件好事
传达结果并采取行动阶段,同前两个阶段同样重要。因为这直接关系到分析结果是否会导致某种行动。如果分析结果决策者不理解或者不乐意基于分析结果来制定决策,那前两个阶段的工作就白做了,那还不如不做。
- 不参与交流的东西。避免太过技术性的术语。
- 有成功也有失败
- 数据可视化的无限可能
- 报告的背后是决策流程的提升
- 当结果不再意味着行动
- 成功的关键
我们生活在一个博眼球的时代,因此将结果以一种妙趣横生、能够吸引注意力的方式进行传达是非常重要的。我们不能以纸上谈兵的方式来展示我们的报告,更不要期望任何人会被这样的报告打动,而应基于报告上的内容采取相应行动。
三、练就数据思维中的实施环节细化
3.1 找到利益相关者的步骤
- 识别所有的利益相关者
- 记录利益相关者的需求
- 评估和分析利益相关者的兴趣或影响
- 管理利益相关者的预期
- 采取行动
- 审核身份和重复步骤
3.2 回顾之前的发现能带来的启发
- 我们能讲述什么样的故事?这个故事是否与预测、报告、实验、调查相关?
- 我们更想找到何种类型的数据?
- 以前的变量是如何定义的?
- 我们更可能执行哪种分析?
- 我们如何用一种趣味横生、可能获得结果且与过去不一样的方式来讲故事?
3.3 回顾之前的发现的一些方法
- 对与你分析相关的关键术语做一次网上搜索
- 查阅统计学教程,查找与你正打算进行的分析类似的分析
- 与公司的分析师沟通,了解他们是否已经做过类似的事情
- 如果公司有一个知识管理系统,就在系统里查一下与你的分析相关的知识
- 与来自其他公司的分析师谈论这个问题,但注意不要与来自竞争对手公司的分析师谈论
- 参加一个关于分析的会议或者至少收看会议直播,了解是否有其他人在讲与你的分析相关的话题。
3.4 确定自己是否构建好问题需要问自己的10个问题
- 你是否已经定义了一个清晰的问题或机会来解决企业里非常重要的问题?
- 你是否已经考虑了多种选择方式来解决问题?
- 你是否已经识别出这个问题的利益相关者,且针对这个问题你已经和这些利益相关者进行了广泛的交流?
- 你是否对你计划解决的问题和利益相关者产生共鸣,且对他们会使用问题的结果来制定决策拥有信心?
- 一旦问题被解决,将基于结果制定的决策的内容以及决策制定者是谁,你清楚吗?
- 刚开始时,你对问题是否有一个较广泛的定义,到后来缩小到一个需要解决、需要应用数据以及明确可能出现的结果的非常确切的问题?
- 在解决这个问题时,你能否描述出你想讲述的分析故事的类型?
- 有人能够帮助你完成这个特定类型的分析故事吗?
- 你已经在你的组织内部或外部进行系统的查阅,以了解是否存在你想解决的问题相关的之前的发现或者经验了吗?
- 你是否基于回顾之前的发现所了解到的内容,对问题的定义进行了修正?
3.5 为识别出适当的模型必须考虑的三个问题
- 我们需要同时分析多少变量?
分析一个变量(单变量模型)、两个变量(双变量模型)还是三个或更多变量(多变量模型)的概率。- 我们需要得到描述性或推论性问题的答案吗?
描述性统计学(Descriptive Statistics)简单地描述了拥有的数据,但并不试图在数据之上对它进行概括。均值、中值和标准差是描述统计学的典型案例。它们通常是有用的,但是从统计学或数学的角度来说,它们不是很令人感兴趣。
推论统计学(Inferential Statistics)会取数据样本进行调查,并试图将调查结果推断或概括到一个更广泛的人口范围内。相关分析和回归分析是推论统计学的典型案例。因为它们包含了关于在样本中观察到的有多大可能会适用于更广泛的人口范围的估算。统计学家和定量分析师们对推论统计学的兴趣远高于描述统计学。- 在感兴趣的变量中,什么样的测量水平是可行的?
3.6 创造性分析思维的4个阶段
准备:为问题打好基础
投入:一门心思解决问题,处理手边的数据;寻找解决办法的长期斗争开始了。
酝酿:利用很可能在意识水平之下建立的、不同寻常的联系,在潜意识里将问题内化(往往在你感到沮丧和准备放弃时)
见解:在通过定量分析解决问题时的重大突破。
四、成为专家级的定量分析师,需要的态度、习惯、知识和方法
4.1 培养数据分析能力
一、当遇到数字时,先开动脑筋
- 别害怕数字
- 运用搜索引擎寻找有关你不知道的观点
- 扩展你的好奇心
二、从定量态度到定量知识
- 思考概率
- 回到学校
三、以新的思维方式行事比思考新的行动方式更容易
- 需要数字
- 千万别相信数据
- 对因果关系保持特别的怀疑
- 提出问题
- 练习定量分析
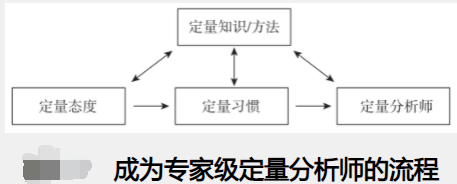
- 定量习惯——定量知识/方法
四、 成为数据分析师:
- 写报告,练习的第一步
- 形成定量分析群体
- 定期召开研讨会
- 定量分析——定量知识/方法
4.2 培养过程注意事项
在三个方面对数据保持怀疑:
- 关联性。
呈现在你面前的数据要与你所要解决的问题相关,并能代表它们应该代表的群体。如果数据不能对问题做出回答,那么它们就是没有意义的。- 准确性
如果数据与问题相关,却不准确,那么就要学会放弃。通过询问是谁提出的数据,这个数据是如何产生的,就能评价数据的准确性。没经过信任测试的数据是没有价值的。- 正确的解释
即便数据是准确的,但如果解释数据的方法不对,那么它们也会令人误解。尤其是那些对将来有规划的人,他们往往会故意曲解数据。
定量分析中的好问题:
- 你有数据来支撑你的假设吗?
- 你能告诉我你在分析中使用的数据源吗?
- 你确定这个样本能代表被试的人数吗?
- 你的数据分布中有没有异常值?它们会对结果产生什么样的影响?
- 你的分析背后有什么假设?
- 在什么条件下,你的假设和模式是无效的?
- 你能告诉我为什么要采用这样的分析法吗?
- 你如何转变数据,使其适用于你的模式?
- 你想过其他方法来分析数据吗?如果有,为什么不用呢?
- 你有没有想过,是独立变量导致了因变量的变化?你还可以进行哪些分析来了解因果关系?
写报告的三个目的:
- 可以学到更多东西,而且在遇到实际问题时,分析问题的熟练性也会得到提高;
- 这对解决工作中的问题大有裨益;
- 有助于在工作中创造分析性氛围,激励他人进行分析性思考和行动。
理想的定量分析师应具备5种能力:
- 他们会学习你的业务,并对商业问题感兴趣
- 他们会用商业术语交谈
- 他们会解释一些专业术语
- 他们希望形成某种关系
- 他们不会让你觉得自己傻
五、总结
数据分析是一门技术与艺术结合的产物,技术我们可以通过学习统计学课程、书籍等相关技术资源来获得。而所谓的艺术,也是可以修炼的,涉猎的范围尽可能广一点,对各种信息保持的好奇心多一点。这里的艺术,我将其理解为创造力。
我们也常在担心机器会替代掉我们的职业,现实也确实如此,但机械能替代的,截止目前,还是可以量化的重复性的工作,而我们人类,往往是喜欢打破常规而行动的。诸如:
- 找出与现有问题相关的东西,这是需要创造力的。
- 收集数据本身是一个乏味的过程,可是,决定收集什么样的数据却是创造性的。
- 数据的结果是固定的,可以结果的呈现方式,却是创造性的。
优秀的分析师就是在常规的流程中,适时的融入了用创造性的方式方法,从而获得不同于业余人员的结果。
其他部分摘记:
- 你必须不断地学习新的东西,因为市场对我们是不利的。如果你不能不断进步,那么你将退步。事实就是,不进则退!——西蒙斯
- “数据不是重点,数字也不是重点,重要的是观点。” —— 施密特
- 成功的关键是确保自己想好了该从哪一步开始,以哪一步结束。如果能正确区分和构建问题,就可以直截了当地进行下一步了。如果你没有有效地传达结果,那么什么行动也不会发生。
- 灵感并非突然闪烁出来,而是从长期的努力和专注中涌现出来的。——赵正莱
- 计算机能找出数据中的模式,可是人类才能让这些模式变得有意义。
- 如果某种预期模式并不是以数据形式呈现的,那么其中必定有滥竽充数或作假的人。
- 统计资料之于不成熟的预测者,犹如路灯之于醉汉——其用途不过是用来支撑而不是照明。——安德鲁·朗格
- 聚在一起是开始,保持一道是进步,一起工作是成功。——亨利·福特

《成为数据分析师》 【美】托马斯·达文波特;金镇浩,浙江人民出版社·湛庐文化,2018年2月
ISBN:9787213086229 ↩︎
这篇关于练就分析思维,成为更好的数据分析师的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







