本文主要是介绍OJ中常用平衡树,Treap树堆详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Treap定义
- Treap的可行性
- Treap的构建
- 节点定义
- 旋转
- 左单旋
- 右单旋
- 旋转的代码实现
- 插入
- 插入的代码实现
- 删除
- 遍历
- 查找
- Treap对权值的扩展
- Treap对size的扩展
- 扩展size域后的节点定义和旋转,插入,删除操作
- 查询第k小的元素
- 求元素的排名
- 查询后继、前驱
- Treap类的代码实现
- Treap的特点
- 无旋式Treap
- 无旋式Treap 定义
- 无旋式Treap 的特点
- 无旋式Treap 的节点定义
- 无旋式Treap 的操作
- 分裂(split)
- 合并(merge)
- 插入(insert)
- 删除(erase)
Treap定义
T r e a p = T r e e + H e a p Treap = Tree + Heap Treap=Tree+Heap
顾名思义,Treap其实就是树和堆的结合,其本质是一种平衡树。
我们最基础的BST在插入有序或接近有序的数据时,会退化成单链的结构,所以我们基于BST有着很多优化方案如AVL树引入平衡因子,红黑树引入颜色等等。
而我们的Treap引入堆其实就是为了维护平衡。其维护平衡的方法就是在BST的基础上加入修正值,修正值满足最小堆的性质(也可以是最大堆,本文基于最小堆实现),即根的修正值小于其子树的修正值。
Treap其实就是满足如下性质的二叉树:
- 如果左子树非空,那么左子树节点的值都小于根节点的值,并且根节点的修正值都小于左子树节点的修正值
- 如果右子树非空,那么右子树节点的值都小于根节点的值,并且根节点的修正值都小于右子树节点的修正值
- 它的左右子树也都是一棵Treap
下图例为一棵Treap
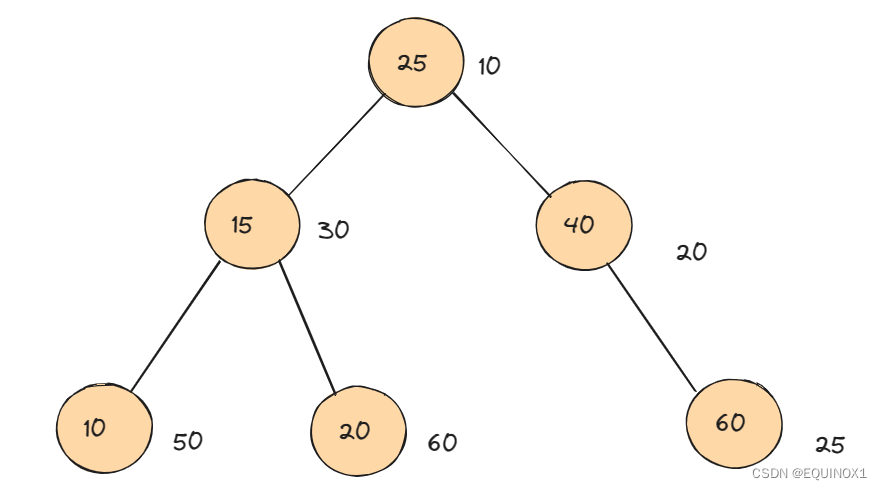
修正值的获取方法其实是一个随即生成的数字,没有规律。
Treap的可行性
前面提到了BST退化为单链是因为插入有序或者接近有序的数据,但我们修正值是一个随机数,获得有序随机数的概率很小,所以我们的Treap是趋于平衡并不是AVL树或者红黑树那种严格平衡,
Treap的构建
节点定义
struct TreapNode
{TreapNode *_left, *_right;//节点左右孩子指针int val, fix;//节点值以及修正值//int _weight;
};
旋转
我们常用的几种平衡树像是AVL树,RB树,为了维护其平衡性都要用到旋转操作,Treap也一样,但是Treap的只用到了左单旋和右单旋,调整比较简单,没有AVL树或是RB树那样繁琐的双旋。
我们记根节点为root,其左右孩子分别为SubL,SubR,左右孩子的左右孩子记为SubLL/SubLR和SubRL/SubRR
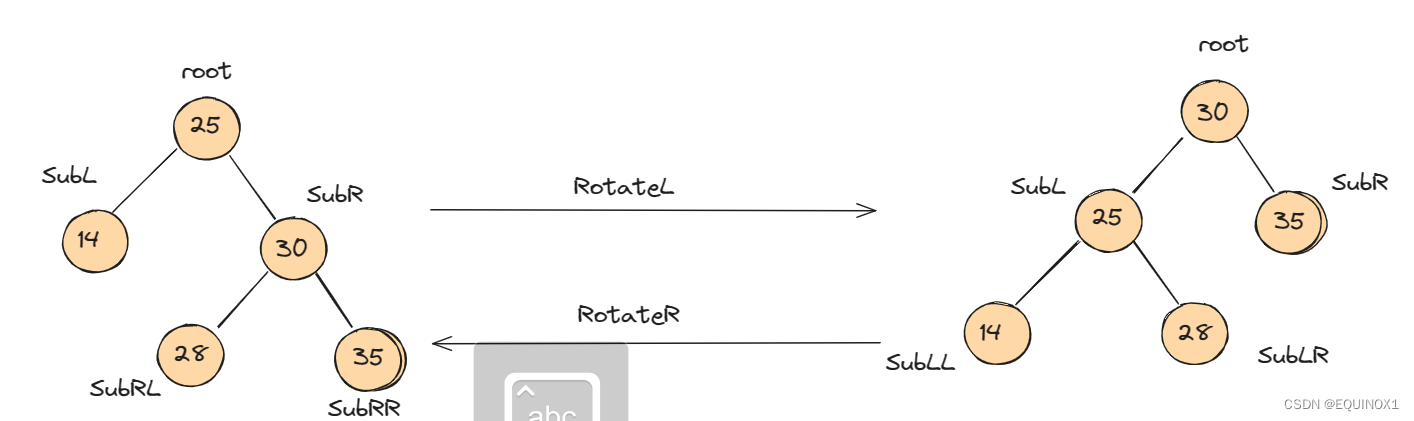
左单旋
左单旋一棵子树:SubRL作为root的右孩子,root作为SubR的左孩子

右单旋
右单旋一棵子树:SubLR作为root的左孩子,root作为SubL的右孩子

旋转操作的本质就是在不改变这棵树的中序遍历的前提下让这颗树的层数可能减小,不改变中序遍历自然维护了BST的性质,不过我们Treap中旋转还可以用来维护修正值的堆序。如:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
旋转后既维护了BST的性质又修正了修正值的堆序。
旋转的代码实现
void RotateL(TreapNode *&root)//左单旋
{TreapNode *SubR = root->_right;root->_right = SubR->_left;SubR->_left = root;root = SubR;
}
void RotateR(TreapNode *&root)//右单旋
{TreapNode *SubL = root->_left;root->_left = SubL->_right;SubL->_right = root;root = SubL;
}
插入
Treap的插入也BST相似(这里的插入暂时允许重复元素插入)
找到插入位置,建立新的节点,如果修正值异常那么就旋转维护
插入过程如下:
- 从根节点开始遍历
- 如果插入值小于当前节点值,那么在左子树插入,插入完成后,如果当前节点修正值大于左孩子修正值,那么右单旋
- 如果插入值大于当前节点值,那么在右子树插入,插入完成后,如果当前节点修正值大于右孩子修正值,那么左单旋
- 当前节点为空,那么找到了插入位置,在该位置进行插入
以下图为例
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
插入的代码实现
void insert(TreapNode *&cur, int val)
{if (!cur){cur = new TreapNode(val, rand());}else if (cur->val > val){insert(cur->_left, val);if (cur->fix > cur->_left->fix) // 左孩子修正值小于当前节点修正值,右旋当前节点RotateR(cur);}else{insert(cur->_right, val);if (cur->fix > cur->_right->fix) // 右孩子修正值小于当前节点修正值,左旋当前节点RotateL(cur);}
}
删除
Treap中删除元素相对于AVL树和RB树简直是简单爆了,一共只有三种情况(其实是成两种)
情况一:被删除节点是叶子节点
没有孩子没有牵挂,生不带来死不带去,直接删除即可
情况二:被删除节点有一个孩子节点非空
子承父业,用孩子节点代替当前节点
情况三:两个孩子节点都非空
不同于BST的替代删除法,我们是通过旋转将待删除结点调整到叶子节点或者只有一个孩子节点非空的位置,然后按照情况一二进行删除。
旋转调整的过程类似于堆调整算法中的向下调整(AdjustDown)算法
如果左孩子修正值小于右孩子修正值,那么右单旋,否则左单旋。如此往下调整直到调整为情况一二。
我们以下图删除结点15为例
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
我们删除的期望时间复杂度为O(logN)
代码实现:
void erase(TreapNode *&root, int val)
{if (root->val > val){erase(root->_left, val);}else if (root->val < val){erase(root->_right, val);}else // 找到待删除节点{if (!root->_right || !root->_left){ // 情况一二,该节点可以直接被删除TreapNode *tmp = root;if (!root->_right)root = root->_left; // 用左子节点代替它elseroot = root->_right; // 用右子节点代替它delete tmp; // 删除该节点}else{ // 情况三if (root->_left->fix < root->_right->fix){ // 左子节点修正值较小,右旋RotateR(root);erase(root->_right, val);}else{ // 左子节点修正值较小,左旋RotateL(root);erase(root->_left, val);}}}
}
遍历
和普通的二叉树遍历方式一样
void _InOrder(TreapNode *root){if (!root)return;_InOrder(root->_left);cout << root->val << ":" << root->fix << " ";_InOrder(root->_right);}void _PrevOrder(TreapNode *root){if (!root)return;cout << root->val << ":" << root->fix << " ";_PrevOrder(root->_left);_PrevOrder(root->_right);}
查找
和BST一样
bool Find(int val){TreapNode *cur = p;while (cur){if (cur->val > val)cur = cur->_left;else if (cur->val < val)cur = cur->_right;elsereturn true;}return false;}
Treap对权值的扩展
我们的Treap其实还存在一个问题,那就是它允许了重复元素的插入,对此我们可以再进一步的优化,那就是把重复的节点合并,即在节点定义里面增加一个权域weight,它存储的是当前值节点的数目。
这样我们插入时如果当前值已存在,那么把对应节点的weight+1即可,相应的,删除时只要把对应节点的weight-1即可,只有当weight为0才真正删除。
虽然增加了节点的大小,但是这样避免了一定程度的旋转,是一笔划算的买卖。
扩展了weight域后的节点定义和插入删除操作
struct TreapNode
{TreapNode(TreapNode *l, TreapNode *r, int v, int f) : _left(l), _right(r), val(v), fix(f), w(1){}TreapNode *_left, *_right;int val, fix, w;
};void insert(TreapNode *&cur, int val){if (!cur){cur = new TreapNode(nullptr, nullptr, val, rand());}else if (cur->val > val){insert(cur->_left, val);if (cur->fix > cur->_left->fix) // 左孩子修正值小于当前节点修正值,右旋当前节点RotateR(cur);}else if (cur->val < val){insert(cur->_right, val);if (cur->fix > cur->_right->fix) // 右孩子修正值小于当前节点修正值,左旋当前节点RotateL(cur);}else//已经存在,w++{cur->w++;}}void erase(TreapNode *&root, int val){if (root->val > val){erase(root->_left, val);}else if (root->val < val){erase(root->_right, val);}else // 找到待删除节点{if (!(--root->w))//如果w为0,在真正删除{if (!root->_right || !root->_left){ // 情况一二,该节点可以直接被删除TreapNode *tmp = root;if (!root->_right)root = root->_left; // 用左子节点代替它elseroot = root->_right; // 用右子节点代替它delete tmp; // 删除该节点}else{ // 情况三if (root->_left->fix < root->_right->fix){ // 左子节点修正值较小,右旋RotateR(root);erase(root->_right, val);}else{ // 左子节点修正值较小,左旋RotateL(root);erase(root->_left, val);}}}}}
Treap对size的扩展
除了对权域weight的扩展外,我们还可以再增加一个size域,size存储的是以当前节点为根的子树的大小。(我们称一棵子树中节点的数目为子树的大小)
为什么要记录当前子树大小呢?
这是为了满足对于第k大元素的查询。
在root所在子树里面找第k大节点,可以根据左右子树的size转化为在左/右子树中找第j大节点
增加了域自然要在相应的操作中对域进行维护。这里涉及三种操作旋转、插入、删除。
旋转:在旋转后对子节点和根节点分别重新计算其子树大小。
插入:新插入节点的size自然是1,对于插入路径上的每一个节点相应的size+1即可。
删除:对于待删除节点,对于删除路径上的每一个节点相应的size-1即可。
对于插入和删除的size维护都比较无脑,主要是保证旋转的维护逻辑无误。
扩展size域后的节点定义和旋转,插入,删除操作
struct TreapNode
{TreapNode(TreapNode *l, TreapNode *r, int v, int f) : _left(l), _right(r), val(v), fix(f), w(1), size(1){}int lsize()//左子树size{return _left ? _left->size : 0;}int rsize()//右子树size{return _right ? _right->size : 0;}TreapNode *_left, *_right;int val, fix, w, size;
};void erase(TreapNode *&root, int val){if (root->val > val){erase(root->_left, val);root->size--;}else if (root->val < val){erase(root->_right, val);root->size--;}else // 找到待删除节点{if (!(--root->w)){if (!root->_right || !root->_left){ // 情况一二,该节点可以直接被删除TreapNode *tmp = root;if (!root->_right)root = root->_left; // 用左子节点代替它elseroot = root->_right; // 用右子节点代替它delete tmp; // 删除该节点}else{ // 情况三if (root->_left->fix < root->_right->fix){ // 左子节点修正值较小,右旋RotateR(root);erase(root->_right, val);}else{ // 左子节点修正值较小,左旋RotateL(root);erase(root->_left, val);}}}elseroot->size--;}}void RotateL(TreapNode *&root){TreapNode *SubR = root->_right;root->_right = SubR->_left;SubR->_left = root;root = SubR;// 此时root为新根,显然要先调节子节点,再调节rootSubR = root->_left; // 命名有点迷惑性了,但是节省空间就这样了SubR->size = SubR->lsize() + SubR->rsize() + SubR->w;root->size = root->lsize() + root->rsize() + root->w;}void RotateR(TreapNode *&root){TreapNode *SubL = root->_left;root->_left = SubL->_right;SubL->_right = root;root = SubL;// 此时root为新根,显然要先调节子节点,再调节rootSubL = root->_right; // 命名有点迷惑性了,但是节省空间就这样了SubL->size = SubL->lsize() + SubL->rsize() + SubL->w;root->size = root->lsize() + root->rsize() + root->w;}void insert(TreapNode *&cur, int val){if (!cur){cur = new TreapNode(nullptr, nullptr, val, rand());}else if (cur->val > val){insert(cur->_left, val);cur->size++;if (cur->fix > cur->_left->fix) // 左孩子修正值小于当前节点修正值,右旋当前节点RotateR(cur);}else if (cur->val < val){insert(cur->_right, val);cur->size++;if (cur->fix > cur->_right->fix) // 右孩子修正值小于当前节点修正值,左旋当前节点RotateL(cur);}else{cur->size++;cur->w++;}}
查询第k小的元素
有了size域之后,我们访问第k小元素就很方便了,其实就是一个简单的分治问题。
对于一个节点root,它在当前子树内的排名显然是[lsize + 1 , lsize + w]
当k在区间左侧,说明要到左子树去找第k小元素
当k在区间右侧,说明要到右子树去找第k - lsize - w小元素
否则当前节点对应的值就是第k小元素
这里也能看出来我们对于weight域的扩展其实是很有必要的~
- 从节点root开始访问、
- 如果root.lsize + 1<= k <= root.lsize + w,则返回当前节点对应值
- 如果k < root.lsize + 1,则分治到左子树查找第k小
- 如果k > root.lsize + w,则分治到右子树查找第k - root.lsize - w小
代码如下:
T kth(TreapNode *root, int k){if (!root){assert(false);}if (k < root->lsize() + 1){return kth(root->_left, k);}else if (k > root->lsize() + root->w){return kth(root->_right, k - root->lsize() - root->w);}else{return root->val;}}
求元素的排名
既然能够查询第k小的元素,自然能够查询元素的排名,同样是利用分治的思想。
对于一个元素val,它的元素排名的贡献来自于值比它小的节点个数,而对于这个个数我们是可以在查找的路径上实现的。
过程为:
-
当前访问节点为root,路径前面的节点对于排名的贡献总和为prev,初始从根节点开始查询,prev初始为0
-
如果root的值为val,那么它的排名区间为[lsize + prev + 1 , lsize + prev + w] (说是区间是因为val的节点有w个)
-
如果root的值大于val,那么就分治到左子树,prev向下传递
-
如果root的值小于val,那么就分治到右子树,prev + lsize + w向下传递
代码如下:
int getKth(TreapNode *root, const T &val, int prev){if (!root){assert(false);}if (root->val > val){return getKth(root->_left, val, prev);}else if (root->val < val){return getKth(root->_right, val, prev + root->lsize() + root->w);}else{return root->lsize() + prev + 1;}}
查询后继、前驱
很常规的一个操作,查前驱就一直记录小于val的节点,同时访问右孩子
查后继就一直记录大于val的节点,同时访问左孩子
遇到空就return
TreapNode *ans;void prev(const T &val){prev(p, val);}void sub(const T &val){sub(p, val);}void prev(TreapNode *root, const T &val){if (!root)return;if (root->val < val)ans = root, prev(root->_right, val);elseprev(root->_left, val);}void sub(TreapNode *root, const T &val){if (!root)return;if (root->val > val)ans = root, sub(root->_left, val);elsesub(root->_right, val);}
Treap类的代码实现
这里给出Treap的完整代码
template <class T>
struct TreapNode
{TreapNode(const T &v, int f) : _left(nullptr), _right(nullptr), val(v), fix(f), w(1), size(1){}int lsize(){return _left ? _left->size : 0;}int rsize(){return _right ? _right->size : 0;}TreapNode *_left, *_right;T val;int fix, w, size;
};
template <class T>
class Treap
{
private:typedef TreapNode<T> TreapNode;TreapNode *p = nullptr;public:void insert(const T &val){insert(p, val);}bool Find(const T &val){TreapNode *cur = p;while (cur){if (cur->val > val)cur = cur->_left;else if (cur->val < val)cur = cur->_right;elsereturn true;}return false;}void erase(const T &val){erase(p, val);}void InOrder(){_InOrder(p);}void PrevOrder(){_PrevOrder(p);}T kth(int k){return kth(p, k);}int getKth(const T &val){return getKth(p, val, 0);}private:int getKth(TreapNode *root, const T &val, int prev){if (!root){assert(false);}if (root->val > val){return getKth(root->_left, val, prev);}else if (root->val < val){return getKth(root->_right, val, prev + root->lsize() + root->w);}else{return root->lsize() + prev + 1;}}T kth(TreapNode *root, int k){if (!root){assert(false);}if (k < root->lsize() + 1){return kth(root->_left, k);}else if (k > root->lsize() + root->w){return kth(root->_right, k - root->lsize() - root->w);}else{return root->val;}}void erase(TreapNode *&root, const T &val){if (root->val > val){erase(root->_left, val);root->size--;}else if (root->val < val){erase(root->_right, val);root->size--;}else // 找到待删除节点{if (!(--root->w)){if (!root->_right || !root->_left){ // 情况一二,该节点可以直接被删除TreapNode *tmp = root;if (!root->_right)root = root->_left; // 用左子节点代替它elseroot = root->_right; // 用右子节点代替它delete tmp; // 删除该节点}else{ // 情况三if (root->_left->fix < root->_right->fix){ // 左子节点修正值较小,右旋RotateR(root);erase(root->_right, val);}else{ // 左子节点修正值较小,左旋RotateL(root);erase(root->_left, val);}}}elseroot->size--;}}void _InOrder(TreapNode *root){if (!root)return;_InOrder(root->_left);cout << root->val << ":" << root->fix << ":" << root->size << " ";_InOrder(root->_right);}void _PrevOrder(TreapNode *root){if (!root)return;cout << root->val << ":" << root->fix << ":" << root->size << " ";_PrevOrder(root->_left);_PrevOrder(root->_right);}void RotateL(TreapNode *&root){TreapNode *SubR = root->_right;root->_right = SubR->_left;SubR->_left = root;root = SubR;// 此时root为新根,显然要先调节子节点,再调节rootSubR = root->_left; // 命名有点迷惑性了,但是节省空间就这样了SubR->size = SubR->lsize() + SubR->rsize() + SubR->w;root->size = root->lsize() + root->rsize() + root->w;}void RotateR(TreapNode *&root){TreapNode *SubL = root->_left;root->_left = SubL->_right;SubL->_right = root;root = SubL;// 此时root为新根,显然要先调节子节点,再调节rootSubL = root->_right; // 命名有点迷惑性了,但是节省空间就这样了SubL->size = SubL->lsize() + SubL->rsize() + SubL->w;root->size = root->lsize() + root->rsize() + root->w;}void insert(TreapNode *&cur, const T &val){if (!cur){cur = new TreapNode(val, rand());}else if (cur->val > val){insert(cur->_left, val);cur->size++;if (cur->fix > cur->_left->fix) // 左孩子修正值小于当前节点修正值,右旋当前节点RotateR(cur);}else if (cur->val < val){insert(cur->_right, val);cur->size++;if (cur->fix > cur->_right->fix) // 右孩子修正值小于当前节点修正值,左旋当前节点RotateL(cur);}else{cur->size++;cur->w++;}}
};
Treap的特点
- 期望深度为O(logn)有着严格的数学证明
- 实现简单,实际OJ中的代码编写十分简洁。
- 原理简单,只有两种单旋,而且只需维护两种基础数据结构的规则
- 稳定性佳,虽然不是严格平衡,但是其简单的代码加上期望平衡性能够很好的应用于算法题目中
无旋式Treap
无旋式Treap 定义
无旋式Treap,即无旋转操作的Treap,不同于我们其他的平衡树,他独有的调整操作是:分裂、合并。也正是其操作方式的特性使其具有支持维护序列和可持久化等特性。因此我们可以用封装的无旋式Treap实现类似C++STL中set的效果。
无旋式Treap 的特点
优点:支持可持久化,操作种类多(支持区间操作)
缺点:比众多平衡树效率低,且相比于旋转式Treap也要慢一些。
无旋式Treap 的节点定义
无旋式Treap 的节点定义和有旋式Treap一样
template <class T>
struct TreapNode
{TreapNode(const T &v, int f) : _left(nullptr), _right(nullptr), val(v), fix(f), w(1), size(1){}TreapNode *_left, *_right;T val;int fix, w, size;
};
无旋式Treap 的操作
分裂(split)
Treap的分裂有两种:按权值分裂和按排名分裂。思想一样,会一种另一种也就会了。这里介绍按权值分裂。
按照权值分裂
将指定根节点root分裂为两个Treap,第一个Treap所有节点的权值小于等于给定val值,第二个Treap所有节点的权值大于给定val值。(注意前者是小于等于,后者是严格大于)
using PII = pair<TreapNode* , TreapNode*>;PII split(TreapNode *root, const T &val){\\...}
操作流程
-
判断root所指向的节点是否为空;为空就直接返回nullptr对
-
将当前root节点所指向的值与给定的key值进行比较:
-
如果root → val > val ,则说明root所指向的节点及其右子树全部属于第二个Treap,同时向左子树继续分裂;
-
如果root → val <= val,则说明root所指向的节点及其左子树全部属于第一个Treap,同时向右子树继续分裂。
-
-
将root和子树递归分裂后得到的两个子树中的一个连接,和另一个子树组成pair返回
-
root分裂完要更新size值(update)
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
代码如下:
/*void update(TreapNode *root){if (!root)return;root->size = root->rsize() + root->lsize() + 1;}*/PII split(TreapNode *root, const T &val){if (!root)return make_pair(nullptr, nullptr);if (root->val > val){PII lp = split(root->_left, val);root->_left = lp.second;update(root);return make_pair(lp.first, root);}else{PII rp = split(root->_right, val);root->_right = rp.first;update(root);return make_pair(root, rp.second);}}
合并(merge)
有分裂自然有合并。由于我们合并一定是为了修补分裂,而分裂是由权值划分为了两个子树,所以一定满足一个子树的val全都小于另一个子树。
所以我们的merge的两个参数为两个根节点指针u,v,要求u树的val全都小于v树的val
然后按照u和v的修正值进行合并,u->fix < v->fix的话,把u的右子树和v合并,否则把v的左子树和u合并
每次合并完都要更新size值(update操作)
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
TreapNode *merge(TreapNode *u, TreapNode *v) // u全都小于v{if (!u)return v;if (!v)return u;if (u->fix < v->fix){u->_right = merge(u->_right, v);update(u);return u;}else{v->_left = merge(u, v->_left);update(v);return v;}}
插入(insert)
从插入和删除就能看出无旋式Treap的优越之处了,代码十分简单。
先按照val分裂,再把新结点和左子树合并,再合并两个子树
void insert(const T &val){PII pp = split(p, val);if (pp.first && pp.first->val == val)pp.first->w++, pp.first->size++;elsepp.first = merge(pp.first, new TreapNode(val, rand()));p = merge(pp.first, pp.second);}
删除(erase)
先按照val分成三段,中间的一段就是val,把两边的两段合并即可
void erase(const T &val){PII oo = split(p, val - 1);PII pp = split(p, val);if (pp.first && pp.first->val == val)delete pp.first;p = merge(oo.first, pp.second);}
查询区间排名等操作与旋转式Treap一样
完整代码
#include <iostream>
#include <string>
#include <algorithm>
#include <cassert>
#include <vector>
using namespace std;
#define int long long
template <class T>
struct TreapNode
{TreapNode(const T& v, int f) : _left(nullptr), _right(nullptr), val(v), fix(f), w(1), size(1){}int lsize(){return _left ? _left->size : 0;}int rsize(){return _right ? _right->size : 0;}TreapNode* _left, * _right;T val;int fix, w, size;
};
template <class T>
class Treap
{private:typedef TreapNode<T> Node;Node* p = nullptr;using PII = pair<Node*, Node*>;public:Node* ans;void prev(const T& val){prev(p, val);}void sub(const T& val){sub(p, val);}void insert(const T& val){PII pp = split(p, val);if (pp.first && pp.first->val == val)pp.first->w++, pp.first->size++;elsepp.first = merge(pp.first, new Node(val, rand()));p = merge(pp.first, pp.second);}void erase(const T& val){PII oo = split(p, val - 1);PII pp = split(p, val);if (pp.first && pp.first->val == val)delete pp.first;p = merge(oo.first, pp.second);}bool Find(const T& val){Node* cur = p;while (cur){if (cur->val > val)cur = cur->_left;else if (cur->val < val)cur = cur->_right;elsereturn true;}return false;}void InOrder(){_InOrder(p);}void PrevOrder(){_PrevOrder(p);}T kth(int k){return kth(p, k);}int getKth(const T& val){PII pp = split(p, val - 1);int ret = (pp.first ? pp.first->size : 0) + 1;p = merge(pp.first, pp.second);return ret;}private:void update(Node* root){if (!root)return;root->size = root->rsize() + root->lsize() + 1;}PII split(Node* root, const T& val){if (!root)return make_pair(nullptr, nullptr);if (root->val > val){PII lp = split(root->_left, val);root->_left = lp.second;update(root);return make_pair(lp.first, root);}else{PII rp = split(root->_right, val);root->_right = rp.first;update(root);return make_pair(root, rp.second);}}Node* merge(Node* u, Node* v) // u全都小于v{if (!u)return v;if (!v)return u;if (u->fix < v->fix){u->_right = merge(u->_right, v);update(u);return u;}else{v->_left = merge(u, v->_left);update(v);return v;}}void prev(Node* root, const T& val){if (!root)return;if (root->val < val)ans = root, prev(root->_right, val);elseprev(root->_left, val);}void sub(Node* root, const T& val){if (!root)return;if (root->val > val)ans = root, sub(root->_left, val);elsesub(root->_right, val);}T kth(Node* root, int k){if (root->lsize() + 1 == k)return root->val;else if (root->lsize() + 1 > k){return kth(root->_left, k);}else{return kth(root->_right, k - root->lsize() - root->w);}}void _InOrder(Node* root){if (!root)return;_InOrder(root->_left);cout << root->val << ":" << root->fix << ":" << root->size << " ";_InOrder(root->_right);}void _PrevOrder(Node* root){if (!root)return;cout << root->val << ":" << root->fix << ":" << root->size << " ";_PrevOrder(root->_left);_PrevOrder(root->_right);}
};
OJ练习
P3369 【模板】普通平衡树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
这里直接用静态版无旋Treap
#include <iostream>
#include <string>
#include <algorithm>
#include <vector>
using namespace std;
#define int long longint root, idx, lc[100010] = {0}, rc[100010] = {0}, sz[100010] = {0}, rnd[100010] = {0}, key[100010] = {0};int newnode(int val)
{idx++;key[idx] = val, rnd[idx] = rand(), sz[idx] = 1;return idx;
}void update(int x)
{sz[x] = sz[lc[x]] + sz[rc[x]] + 1;
}void split(int cur, int k, int &l, int &r) // l树权值小于等于k r大于k
{if (!cur)l = r = 0;else{if (key[cur] <= k){l = cur;split(rc[cur], k, rc[cur], r);}else{r = cur;split(lc[cur], k, l, lc[cur]);}update(cur);}
}int merge(int l, int r)
{if (!l || !r)return l + r;if (rnd[l] < rnd[r]){rc[l] = merge(rc[l], r);update(l);return l;}else{lc[r] = merge(l, lc[r]);update(r);return r;}
}void insert(int k)
{int l, r;split(root, k, l, r);root = merge(merge(l, newnode(k)), r);
}void erase(int k)
{int x, y, z;split(root, k, x, z);split(x, k - 1, x, y);y = merge(lc[y], rc[y]);root = merge(merge(x, y), z);
}int kth(int k) // 排名
{int l, r;split(root, k - 1, l, r);int ret = sz[l] + 1;root = merge(l, r);return ret;
}int getkth(int p, int k)
{if (sz[lc[p]] + 1 == k)return key[p];else if (sz[lc[p]] + 1 > k){return getkth(lc[p], k);}else{return getkth(rc[p], k - sz[lc[p]] - 1);}
}
int ans;
void prev(int p, int val)
{if (!p)return;if (key[p] < val)ans = p, prev(rc[p], val);elseprev(lc[p], val);
}void sub(int p, int val)
{if (!p)return;if (key[p] > val)ans = p, sub(lc[p], val);elsesub(rc[p], val);
}signed main()
{ios::sync_with_stdio(false);cin.tie(0), cout.tie(0);srand(time(0));int n;cin >> n;root = idx = 0;while (n--){int s, x;cin >> s >> x;if (s == 1)insert(x);else if (s == 2)erase(x);else if (s == 3)cout << kth(x) << '\n';else if (s == 4)cout << getkth(root, x) << '\n';else if (s == 5){prev(root, x);cout << key[ans] << '\n';}else{sub(root, x);cout << key[ans] << '\n';}}return 0;
}这篇关于OJ中常用平衡树,Treap树堆详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






