本文主要是介绍Eolink Apikit 版本更新:「数据字典」功能上线、支持 MongoDB 数据库操作、金融行业私有化协议、GitLab 生成 API 文档...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🎉 新增
-
搭建自定义接口协议架构,支持快速适配金融行业各类型私有协议的导入、编辑和展示。
-
数据字典功能上线,支持以数据字典的形式管理参数枚举值;
-
数据库连接支持 MongoDB 数据库操作;
-
基于 Apikit 类型导入 API 数据支持增量更新。
🚀 优化
-
增强基于 Gitlab 仓库生成 API 文档能力,支持无注解生成;
-
自动化测试用例列表和项目列表优化,支持更多的排序和筛选体验,并本地缓存列表展示配置。
📑 修复
-
修复 Mock 设置的随机数开关影响 JS 脚本逻辑的问题;
-
测试用例模板相关的缺陷专项,解决大部分特殊场景使用问题。
功能亮点介绍:

对于金融行业而言,因其业务的特殊性,往往都会基于一些通用的开发框架进行升级改造,并形成一些行业内专用的接口协议文档。
为了满足金融行业对私有接口协议的文档管理和接口测试的需求,Apikit 平台近期进行了架构升级,通过协议 Schema 来统一管理不同协议的共性和差异,实现私有协议的功能开发,未来更能够支持用户自定义配置的方式快速生成自有协议。
近期 Apikit (私有部署)进行版本迭代,现已支持证券行业 FS 2.0 协议的 Json 格式接口文档的解析导入、支持 FS 2.0 、恒生与中焯协议的文档编辑能力;同时该三种私有协议支持自定义字段功能,实现 API 接口治理能力的全面提升。
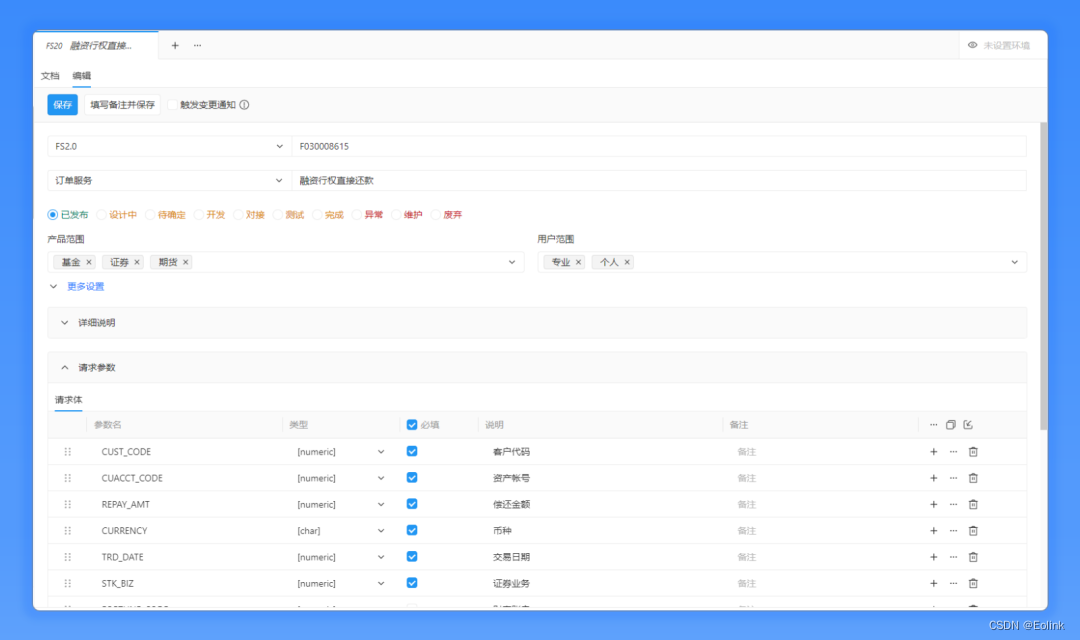

对于开发者而言,数据字典应该都不陌生了。大多数的业务系统接口涉及的数据字典众多,部分数据字典更是多达几十个值。需要支持数据字典的批量导入、修改、版本管理等功能,并支持数据字典与入参、出参的关联,以及与 API 文档同时分享与导出。
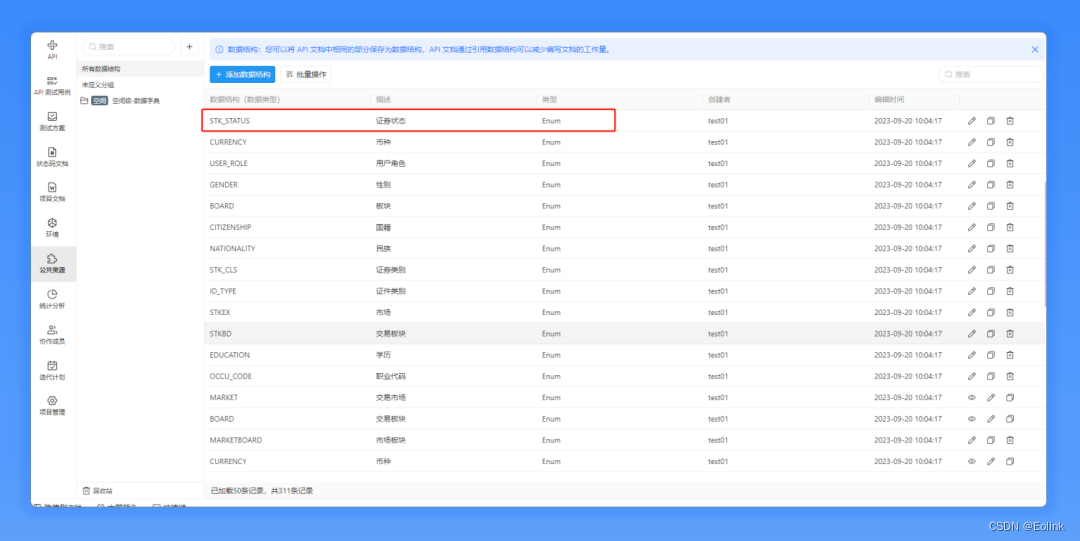
接口参数的枚举类型可以,一般通过数据字典管理,用户可以查看每个参数对应的数据字典,了解传参的值范围。
提供系统级别的数据字典管理功能,可以在该管理功能中,对数据字典进行增删查改操作。在 API 文档中,提供数据字典和入参出参的关联,支持分享 API 文档时,可选择分享数据字典。

Apikit 新增支持“mongodb”和“mongoose”两种最主流的脚本驱动。用户可在不同的开发场景中选择最合适的数据库驱动类型,以获得更好的性能和适应性。
👉 配置操作指引:https://help.eolink.com/tutorial/Apikit/c-1263#tip8


本次更新对常用的 JAVA 语言代码的 Gitlab 仓库生成 API 文档能力进行了增强,支持一键无注解生成 API 文档,有效提升效率。
近期的重要更新就先介绍到这里!未来,我们会持续优化产品,带给大家更棒的 API 研发管理体验~
Eolink Apikit 官网 👉 https://www.eolink.com/apikit
这篇关于Eolink Apikit 版本更新:「数据字典」功能上线、支持 MongoDB 数据库操作、金融行业私有化协议、GitLab 生成 API 文档...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







