本文主要是介绍学习在echarts中优化数据视图dataView样式带表格样式,支持复制功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习在echarts中优化数据视图dataView样式 带表格样式
toolbox里有个dataView视图模式,里面的数据没有对整,影响展示效果,情形如下:
 像这种标题跟数据没有整齐对应上,看起来乱
像这种标题跟数据没有整齐对应上,看起来乱
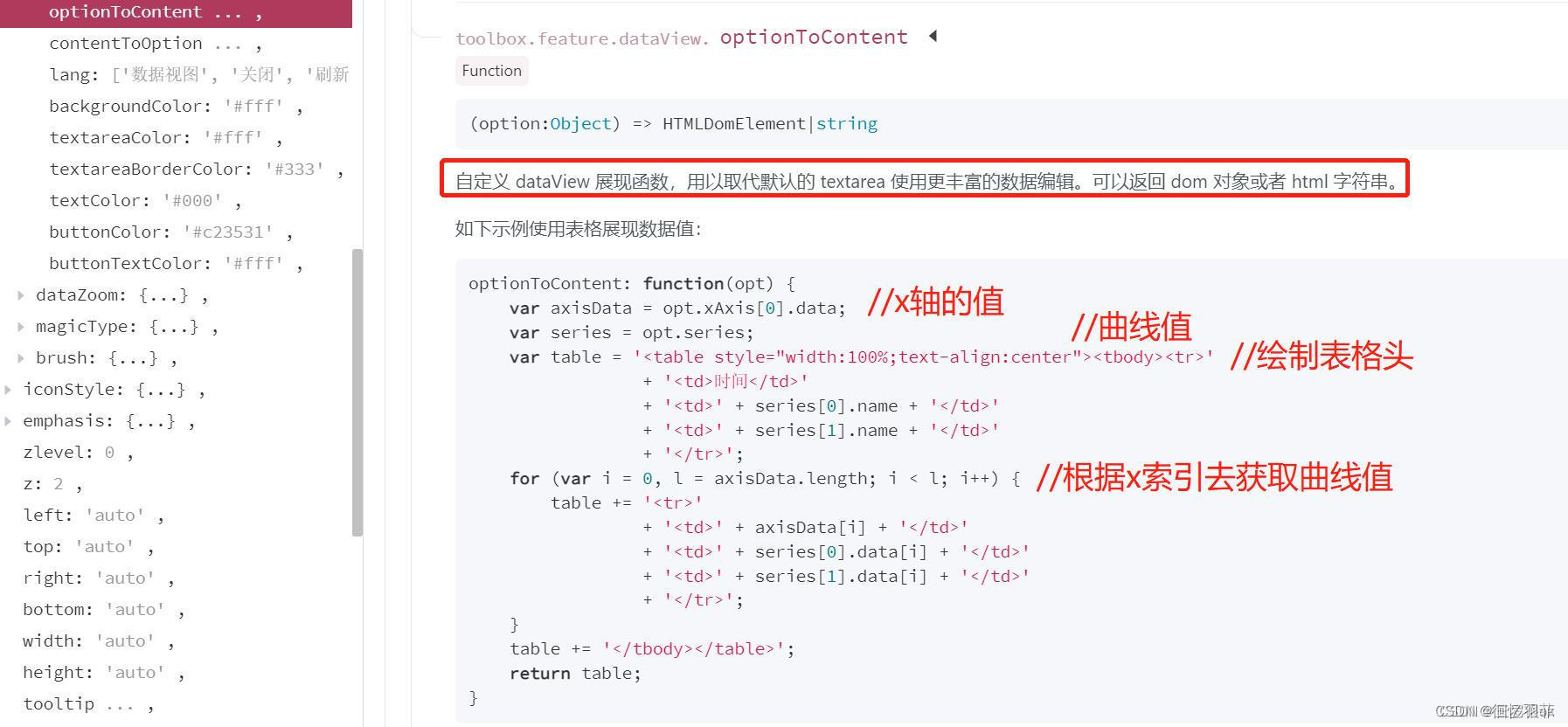
改问题解决方案为,option 》 toolbox 》 feature 》 dataView 》optionTocontent 回调函数中处理,具体代码如下:
option = {color: ['#f54c49','#1976d2'],tooltip: {trigger: 'axis',axisPointer: {type: 'shadow'}},toolbox: {show : true,feature : {dataView : {show: true, readOnly: false,optionToContent: function (opt) {var axisData = opt.xAxis[0].data;//x轴作为条件,y轴需改成yAxis[0].data;var series = opt.series;var tdHeads = '<td style="padding:0 10px">名称</td>';series.forEach(function (item) {tdHeads += '<td style="padding: 0 10px">'+item.name+'</td>';});var table = '<table border="1" style="margin-left:20px;border-collapse:collapse;font-size:14px;text-align:center;background-color:#666"><tbody><tr>'+tdHeads+'</tr>';var tdBodys = '';for (var i = 0, l = axisData.length; i < l; i++) {for (var j = 0; j < series.length; j++) {if(typeof(series[j].data[i]) == 'object'){tdBodys += '<td>'+series[j].data[i].value+'</td>';}else{tdBodys += '<td>'+ series[j].data[i]+'</td>';}}table += '<tr><td style="padding: 0 10px">'+axisData[i]+'</td>'+ tdBodys +'</tr>';tdBodys = '';}table += '</tbody></table>';return table;}},magicType : {show: true, type: ['line', 'bar']},restore : {show: true},saveAsImage : {show: true}},iconStyle:{borderColor:'white'}}}
修改后的效果为:
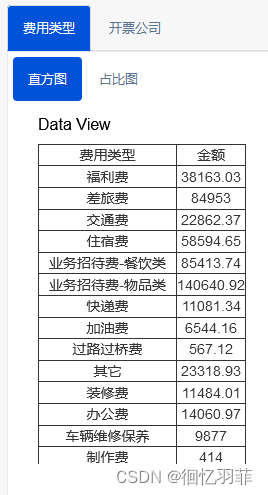
如果想解决复制问题,可以给table加个样式就解决了
var table = '<table style="width:100%;user-select: text;text-align:center;"><tbody><tr>'
主要是这个user-select: text; 就能复制了
result = {"title": {"text": "互动情况(UV)","subtext": "注: 点击下方说明项可选择是否展示, UV计算方式: 各个行为对应用户总数(去重)","textStyle": {"color": "rgba(255, 0, 0, 1)","fontSize": 20}},"tooltip": {"trigger": "axis","formatter": function (params) {let str = '';params.forEach((item, idx) => {str += `${item.marker} ${item.data.time}_${item.seriesName}: ${item.data.value}`str += idx === params.length - 1 ? '' : '<br/>'})return str},},"legend": {"type": "scroll","bottom": 6,"data": ["like","comment","collect","share","dislike","ALL"]},"toolbox": {"show": true,"feature": {"dataZoom": {"yAxisIndex": "none"},"dataView": {"show": true,"optionToContent": function (opt) {// console.log(opt) //该函数可以自定义列表为table,opt是给我们提供的原始数据的obj。 可打印出来数据结构查看var axisData = opt.xAxis[0].data; //坐标轴var series = opt.series; //折线图的数据console.log("1")console.log(series)console.log("2")var tdHeads = `<td style="margin-top:10px; padding: 0 15px">日期</td>`; //表头var tdBodys = "";series.forEach(function (item) {tdHeads += `<td style="padding:5px 15px">${item.name}</td>`;});var table = `<table border="1" style="margin-left:20px;user-select:text;border-collapse:collapse;font-size:14px;text-align:center"><tbody><tr>${tdHeads} </tr>`;for (var i = 0, l = axisData.length; i < l; i++) {for (var j = 0; j < series.length; j++) {if (series[j].data[i] == undefined) {tdBodys += `<td>${"-"}</td>`;} else {tdBodys += `<td>${series[j].data[i]["value"]}</td>`;}}table += `<tr><td style="padding: 0 15px">${axisData[i]}</td>${tdBodys}</tr>`;tdBodys = "";}table += "</tbody></table>";return table;},"contentToOption": function (HTMLDomElement, opt) {return opt;},"readOnly": false},"magicType": {"type": ["line","bar"]},"restore": {},"saveAsImage": {}}},"xAxis": {"type": "category","boundaryGap": false,"data": config.xAxis_data,},"yAxis": {"type": "value","axisLabel": {"formatter": "{value}"}},"series": [{"name": "like","type": "line","data": config.interaction_data.like},{"name": "comment","type": "line","data": config.interaction_data.comment},{"name": "collect","type": "line","data": config.interaction_data.collect},{"name": "share","type": "line","data": config.interaction_data.share},{"name": "dislike","type": "line","data": config.interaction_data.dislike},{"name": "ALL","type": "line","data": config.interaction_data.ALL},]
}return result
这篇关于学习在echarts中优化数据视图dataView样式带表格样式,支持复制功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





