本文主要是介绍为什么推荐使用Apache Camel作EAI?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
仅为笔者一家之言。
1. 概述
笔者所在公司主要业务属于电子政务,近两年随着国家"简政放权"的不断深入,政府机构之间信息共享的需求也变得日益频繁,而在历史遗留等诸多因素的影响之下部门之间的对接并没有预想中那么顺畅,这种情形下,一个好的框架无疑能大幅度降低对业务研发人员能力的要求,减少问题的产生,以及出现问题后的排查成本,最终达到降低应用集成成本的目的。
今年年初的时候,在与他家公司作技术交流的时候偶然接触到了Apache Camel这一组件。又在之后的工作中将其应用到公司的某个核心业务功能上,从结果反馈来看其表现不俗。
本文将结合笔者粗浅的认识,以及实际工作经验,阐述下笔者个人认为的在作EAI(Enterprise Application Integration,企业应用集成)时候Apache Camel的优势。
2. 理由
2.1 为EIP而生
Apache Camel官方网站首页上直接点明:“Based on Enterprise Integration Patterns (EIP) to help you solve your integration problem by applying best practices out of the box。” (基于EIP,通过开箱即可用的最佳实践来帮助你解决应用集成问题)。
2.2 完善的路由日志
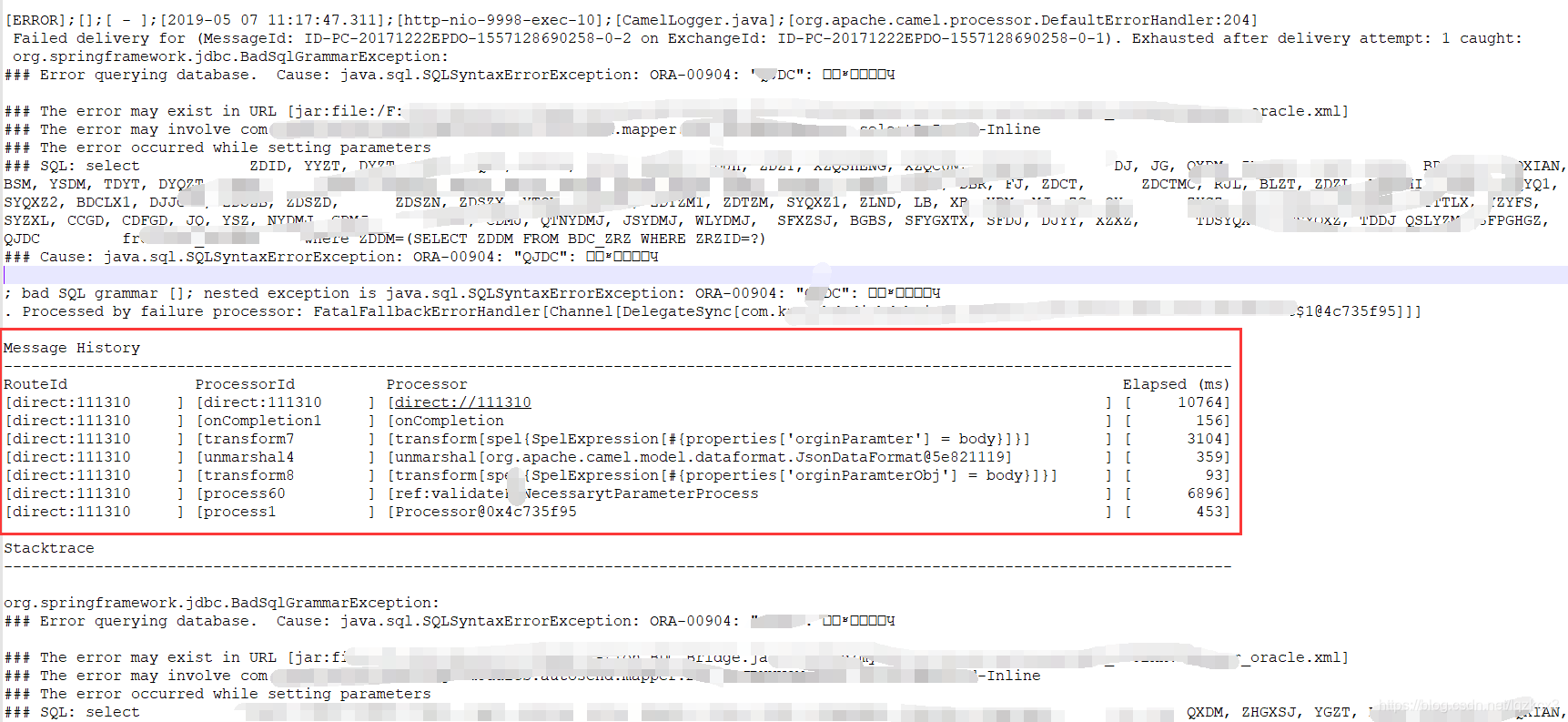
其强大的Pipeline设计,让我们可以将业务逻辑拆解为原子状的积木块,然后依据自身的业务需求将这些积木搭建成理想的样子,如果能够严格遵循这个思路执行下去,那么每个积木块中将只包含独立的小块逻辑,再辅之以少量简单的约束(例如不允许吞掉异常),那么其他关键性的业务扭转相关日志信息的记录我们可以借助Camel自身提供的路由日志功能来复现运行时的业务流程,可以想象这将能大大缩短我们在系统异常情况下的响应延时。
下面是笔者遇到的一个错误现场,路由流向非常清晰,错误原因也是一目了然:
2.3 完备的事务机制
现在人们对于系统的要求越来越高,由此造成的影响之一就是很少有一个系统能将用户的需求完全满足,也就是对于一个用户请求的响应,很可能是多个系统一起协同工作的结果。那么对于类似的请求,维护数据间的完整性就成了最基本的需求,也就是在系统处理某个请求失败时,能够回滚掉之前已经成功的多个子操作(注意这里的子操作不仅仅是数据库层面,还有诸如文件增删等非事务性的操作)。
在Apache Camel中,除了对常规的数据库事务的支持外,其还通过引入UOW(UnitOfWork)来完成对补偿性事务的需求,达到"最终一致性"的柔性事务效果。
借助以上概念和Camel提供的支持,我们可以通过引入适当的契约接口,来完成对于柔性事务最终一致性的支持。
public class TransactionCompensatingManager implements Synchronization {@Overridepublic void onComplete(Exchange exchange) {// NONE}@Overridepublic void onFailure(Exchange exchange) {// 捕获原始异常//final Exception e = exchange.getProperty(Exchange.EXCEPTION_CAUGHT, Exception.class);// Copy From MessageHelper.doDumpMessageHistoryStacktrace()@SuppressWarnings("unchecked")final List<MessageHistory> list = exchange.getProperty(Exchange.MESSAGE_HISTORY, List.class);Collections.reverse(list); //将list中的数据倒序for (MessageHistory messageHistory : list) {final NamedNode node = messageHistory.getNode();if (!(node instanceof ProcessDefinition)) {continue;}final String ref = ((ProcessDefinition) node).getRef();if (StringUtil.isEmpty(ref)) {continue;}final boolean containsBean = SpringBeanFactory.containsBean(ref);if (!containsBean) {continue;}final Processor bean = SpringBeanFactory.getBean(ref, Processor.class);if (!(bean instanceof XxxRollBack)) {continue;}((XxxRollBack) bean).rollback(exchange);}}
}
通过向Camel中注册以上配置,那么每个负责进行业务处理的Processor即可以通过实现XxxRollBack来完成自己负责的那块逻辑的事务回滚操作,简单,清晰,优美!
另外Camel在2.21.0之后的版本还引入了对于分布式事务Saga模式的支持,感兴趣的读者可以阅读下方的引用链接。
2.4 强大的运行时支持
Apache Camel支持动态卸载/添加,启动/停止,挂起/恢复Route等运行时操作,这在某些情况下会变得非常有用,当然更多的神来之笔就取决于研发人员的想象力和创造力,以及实际的业务场景了。(关于这一点,读者可以通过监控平台Hawtio来检验,实现方式参见笔者的另外一篇博客 Apache Camel监控之使用hawtio)

不过这里要额外说一句的是,笔者发现在实际工作中,不少研发人员,尤其是刚入行不久的,特别喜欢追求这种奇方秘技,寄希望于其能够拯救由一堆惨不忍睹的代码堆砌出来摇摇欲坠的系统,或彰显某些东西;对此笔者一直觉得莫名其妙——技巧是用来锦上添花的,你这根都烂了,还寄希望于在外面套一层绚烂的外衣能够力挽狂澜? 基础不牢,地动山摇,有这时间把基础打好,应该是一条更正确的路线。
2.5 极为丰富的扩展组件
Apache Camel历经12年的发展,到如今已经拥有多达三百余种扩展组件,几乎所有你能想象到的组件都能在Camel的扩展组件包中找到,例如让笔者惊讶的camel-exec(用于执行系统命令)等。感兴趣的读者可以去camel-components-list找一下是否有自己感兴趣的,或者马上要用到的。
而且每次的版本更新,这些扩展组件的版本号将一并随之更新,这样就免去你到处确认版本号的烦恼,非常方便。
2.6 方便灵活的扩展机制
由上面2.4小节就可以看出,Apache Camel的扩展应该是极其方便和灵活的,这一点不仅表现在第三方扩展组件上,也表现在对于内部自定义业务逻辑的拆解上,你可以将自身的业务逻辑拆解为一个个的Processor处理块,这只取决于你自己的想象力,Camel没有对此作任何限制。
2.7 详尽的文档
Apache Camel有着非常详尽的文档,并对应得在Github上维护着一份专门的 Camel Example,样例代码几乎涵盖了Camel的所有扩展组件,对于新手而言相当友好,对于熟手上手其他不熟悉的组件也是非常方便。
2.8 极其活跃的社区
这个可以说是以上大部分其他理由的基石。作为一款2007初成立至今依然有着如此活跃度的社区意味着你的绝大部分困扰已经被先驱者们遇到并解决,作为后来者的你可以尽情享受这样一份馈赠。个中的幸福对于由.NET阵营转投到Java阵营的笔者有着切身体会。
3. 意外之喜
3.1 学习第三方组件的起点
在你熟悉Apache Camel的基本使用之后,你就会发现Camel真的是学习其他第三方组件一个非常好的起点,因为它已经帮你把一些默认参数都准备好了, 你只需要参考Camel提供的详尽文档和用例,测试你想要的功能即可,例如下面这个测试Hibernate validator功能的单元测试:
CamelTestUtil.defaultPrepareTest2(new RouteBuilder() {@Overridepublic void configure() throws Exception {configValidatorFail(this);from("stream:in?promptMessage=Enter something:")//.setBody(constant(new Car(null, null)))//.to("bean-validator://x")//.to("stream:err");}
});
在以上测试用例中,你只需要关注各个注解的用途是否符合你的预期,然后快速挑选出符合你当前业务场景的注解即可。其他诸如初始化,验证等工作Camel会自动帮你完成,实在是大大降低了入门曲线。至于之后的高级应用,当然还是得看个人主观能动性了。
4. Links
- Apache Camel Office Site
- Apache Camel 介绍
- The Saga Pattern in Apache Camel
- 基于 Seata Saga 设计更有弹性的金融应用
这篇关于为什么推荐使用Apache Camel作EAI?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




