本文主要是介绍python从数据集中读取日期并对两条折线中间填色,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
datetime模块读取时间
折线图填色
在图表中添加日期可以使得图标更加有用。在天气数据文件中,第一个日期在第二行:
“USW00025333”,“SKIKA AIRPORT”,AK US“,”2018-07-01“,”0.25“,,”62“,”50“
读取该数据时,获得的是字符串,因此需要想办法将字符串
”2018-7-1“转化为一个表示相应日期的对象。为创建一个表示2018年七月1日的对象,可使用模块datetime中的方法stptime()
from datetime import datetime
import csv
import matplotlib.pyplot as pltfilename ='data/sitka_weather_2018_simple.csv'#将要使用的文件名赋给filename
with open(filename) as f:#打开这个文件并且把返回的文件对象赋给freader = csv.reader(f) #调用csv.reader()并将前面储存的文件对象作为实参传递给它,从而创建一个与该文件相关联的阅读器对象,这个阅读器的对象被赋给了reader#模块csv中包含函数next(),调用它并传入阅读器对象时,它将返回文件中的下一行。header_row = next(reader) #文件的第一行中一系列的文件头指出了后续各行包含的是什么样的信息#reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一个元素储存在列表中#print(header_row)#for index, column_header in enumerate(header_row): 更详细的显示数据# print(index , column_header)#在知道需要哪些列中的数据后,我们来读取一些数据,从文件中获取最高温度,最低温度和日期:highs,dates,lows= [],[],[]for row in reader:current_date = datetime.strptime(row[2],'%Y-%m-%d')high = int (row[5]) #数据是用字符串存储的,因此转化类型low=int(row[6])dates.append(current_date)highs.append(high)lows.append(row[6])#print(highs)
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
fig,ax =plt.subplots()
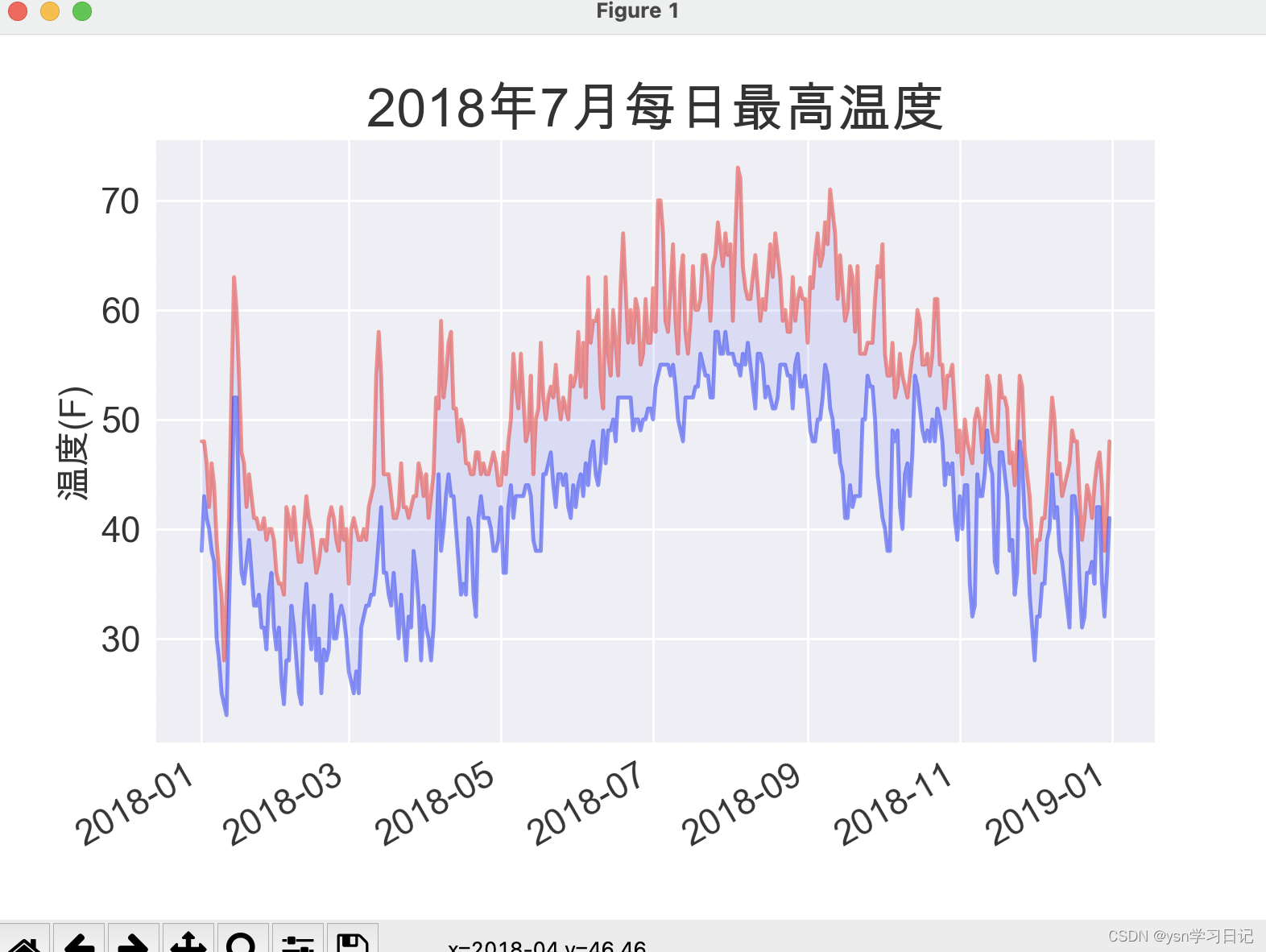
ax.plot(dates,highs , c='red',alpha=0.5)#alpha为透明度
ax.plot(dates,lows,c='blue',alpha=0.5)
ax.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1)
#设置图形格式
ax.set_title("2018年7月每日最高温度",fontsize=24)
ax.set_xlabel('',fontsize=16)
fig.autofmt_xdate()#绘制倾斜的日期标签以免重叠
ax.set_ylabel("温度(F)",fontsize=16)
ax.tick_params(axis='both',which ='major',labelsize=16)
plt.show()datetime模块读取时间
对于datetime模块有很多设置日期和时间的实参
%A 星期几Monday
%B 月份名January
%m 用数字表示的月份
%d 用数字表示的月份中的一天
%Y 四位的年份
%y 两位的年份
%H 24小时的小时数
%I 12小时的小时数
%p am或者pm
%M 分钟数 00—59
%S 秒数 00—61
可以根据我们的需要来进行使用
折线图填色
这边可以使用fill_between的函数来对于两个折线图之间进行颜色的填充,同时可以通过alpha来改变透明度来使得你的图看上去更美观。结果如下显示:
这篇关于python从数据集中读取日期并对两条折线中间填色的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







