本文主要是介绍Excel2010如何获取外部数据比如导入来自网站中的数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Excel2010工作表不仅可以存储处理本机的数据,还可以导入来自网站的外部数据信息,由此可以看出它的功能多么的强大,下面对获取外部数据的整个过程以图文的形式进行介绍,相信不会的朋友可以快速理解。
简述
首先新建一个空白的Excel表格,接着在“获取外部数据”选项组中单击“自网站”按钮,在对话框中输入网站地址并点击“转到”按钮,在导入数据的页面,可以进行一些相关设置,这里先使用默认值。数据选定之后,点击导入按钮,在对话框中确定数据放置的位置,点击确定即可。
步骤
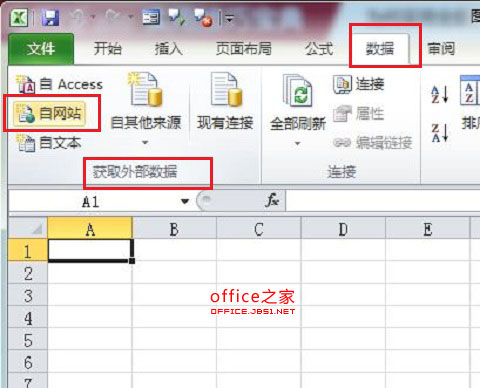
1. 首先需要准备一张空白的 Excel 表格用来存储来自网站的数据信息,然后在“数据”选项卡的“获取外部数据”选项组中单击“自网站”按钮,如图1:
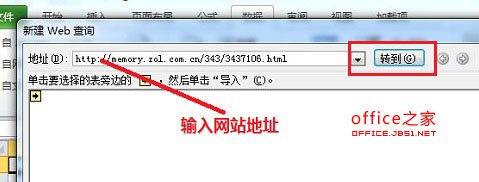
2. 在打开的“新建 Web 查询”页面当中需要输入网站地址,地址输入完毕之后单击“转到”按钮,如图2:
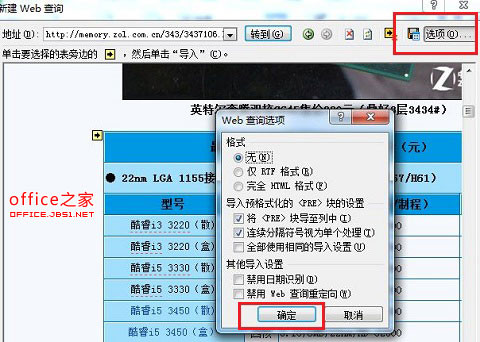
3. 这样就进入了需要导入数据的页面,在此页面中导入数据之前可以进行一些相关设置,单击右上角的“选项”按钮,打开“Web 查询选项”对话框,在此对话框中可以根据实际需要进行相关设置,我们暂时使用默认值,然后单击“确定”按钮,如图3:
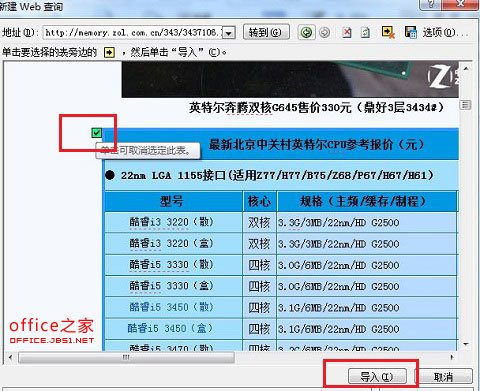
4. 接下来就可以在整个页面去选择要导入的数据,单击要导入数据左上角的“右箭头”按钮,如图4:
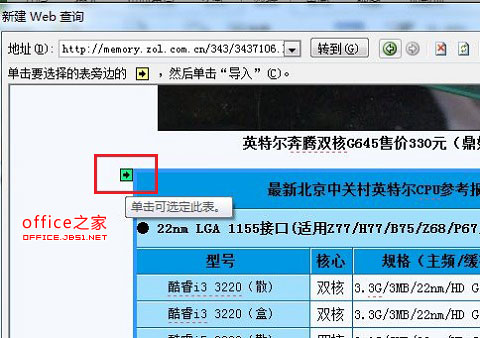
5. 单击后此“箭头”图标就变成“对号”图标了,数据选定完成后,单击右下角的“导入”按钮,如图5:
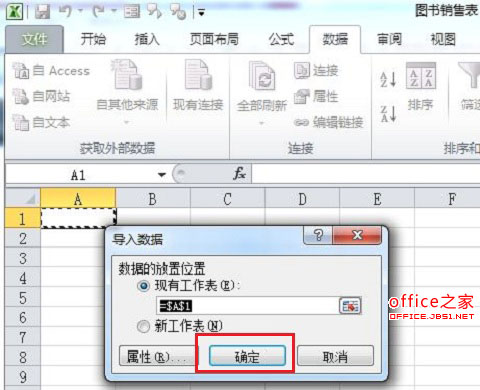
6. 在随后打开的“导入数据”对话框可以来确定一下数据放置的位置,这里面我们选择默认位置,单击“确定”按钮即可,如图6:
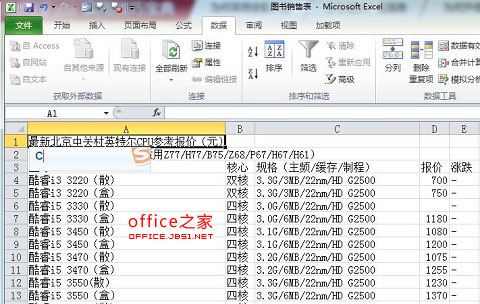
7. 网站中的数据已经被导入到了工作表当中,如图7:
这篇关于Excel2010如何获取外部数据比如导入来自网站中的数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



