本文主要是介绍1949-2020全国31省市GDP数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
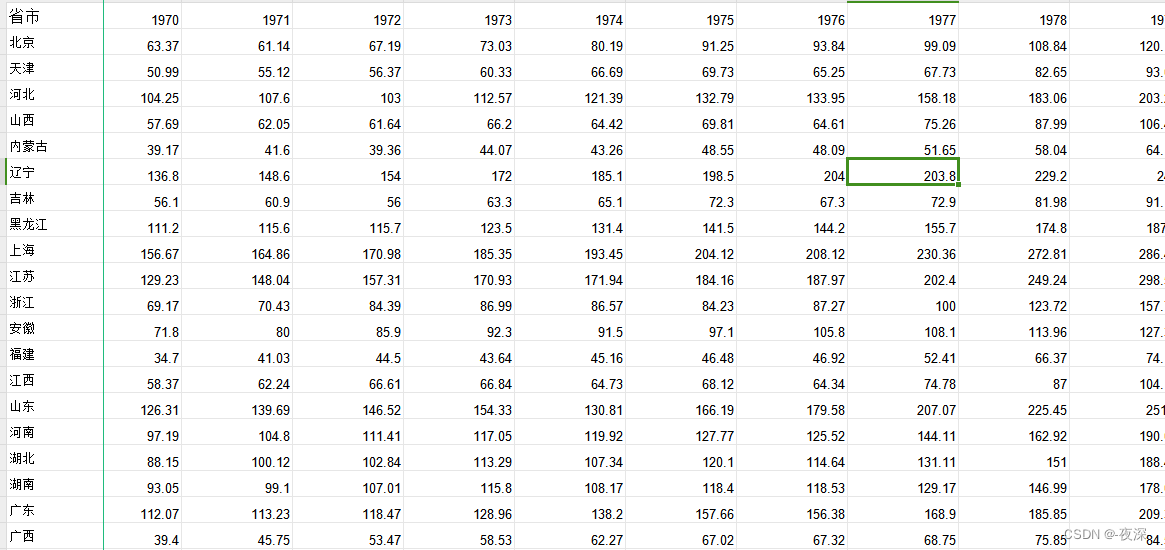
1949-2020全国31省市GDP数据
1、时间:1949-2020年
2、来源:国家统计局
3、指标:地区生产总值(GDP)
4、范围:31省市
5、指标解释:
国内生产总值(GDP)是指按国家市场价格计算的一个国家(或地区)所有常住单位在一定时期内生产活动的最终成果,常被公认为是衡量国家经济状况的最佳指标。
国内生产总值GDP是核算体系中一个重要的综合性统计指标,也是我国新国民经济核算体系中的核心指标,它反映了一国(或地区)的经济实力和市场规模。
6、下载链接:
1949年-2020年中国各省GDP![]() https://download.csdn.net/download/2201_75673146/88311216
https://download.csdn.net/download/2201_75673146/88311216
这篇关于1949-2020全国31省市GDP数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






